Download as docx, pdf, or txt
You might also like
- Mathematics All inDocument317 pagesMathematics All inAnthony Caputol100% (7)
- What Is Frequent Pattern Analysis?Document37 pagesWhat Is Frequent Pattern Analysis?Rishabh JainNo ratings yet
- Data MiningDocument26 pagesData MiningDeepika SharmaNo ratings yet
- Assignment 2Document13 pagesAssignment 2tzeloNo ratings yet
- Association Rule Mining: Data Mining and Knowledge Discovery Prof. Carolina Ruiz and Weiyang LinDocument11 pagesAssociation Rule Mining: Data Mining and Knowledge Discovery Prof. Carolina Ruiz and Weiyang LinChristine CheongNo ratings yet
- 06 - Unsupervised Learning - 18 Dec 2023Document50 pages06 - Unsupervised Learning - 18 Dec 2023Hadi MirzaNo ratings yet
- Table. Example of Market Basket TransactionsDocument3 pagesTable. Example of Market Basket TransactionsMithun MNo ratings yet
- B.Tech May2022 Comp CSPE-64 Sem4Document4 pagesB.Tech May2022 Comp CSPE-64 Sem4ankit12012064No ratings yet
- Module5 DMWDocument13 pagesModule5 DMWSreenath SreeNo ratings yet
- 11 Association Rules Mining NewDocument32 pages11 Association Rules Mining NewNilakhya ChawrokNo ratings yet
- HW 1Document5 pagesHW 1calvinlam12100No ratings yet
- CH 03 Frequent Pattern Mining 2021Document62 pagesCH 03 Frequent Pattern Mining 2021PRIYA RATHORENo ratings yet
- Unit 2 Decision TreeDocument16 pagesUnit 2 Decision TreePradeep PrathipatiNo ratings yet
- Powerpoint Presentation On SomlethingDocument181 pagesPowerpoint Presentation On SomlethingAshik AhmedNo ratings yet
- Week 7 Assignment 1Document6 pagesWeek 7 Assignment 1Justpositive StuffNo ratings yet
- Chapter3 DMDocument33 pagesChapter3 DMBinyam Bekele MogesNo ratings yet
- SI N D IA: Jee Advanced Sample Paper - 2019 Sample Paper 2 Mathematics Part-I QuestionsDocument3 pagesSI N D IA: Jee Advanced Sample Paper - 2019 Sample Paper 2 Mathematics Part-I QuestionsMudit KumarNo ratings yet
- Association Rules FP GrowthDocument32 pagesAssociation Rules FP GrowthMuhammad TalhaNo ratings yet
- Grade 7 WorkbookDocument103 pagesGrade 7 WorkbookMaria Russeneth Joy Nalo100% (1)
- SR Conflict LR (1) Item: S - .A, $ A - B., According To PowerDocument3 pagesSR Conflict LR (1) Item: S - .A, $ A - B., According To PowerAkash YadavNo ratings yet
- Ilovepdf MergedDocument30 pagesIlovepdf MergedKEERTHANA KNo ratings yet
- Cluster Analysis-Part I, II and IIIDocument77 pagesCluster Analysis-Part I, II and IIIRohit TornekarNo ratings yet
- Matrix ApplicationDocument21 pagesMatrix ApplicationMahjabin Zerin RahmanNo ratings yet
- IC EEE MAT Sample 1Document11 pagesIC EEE MAT Sample 1pjustinwebNo ratings yet
- AssociationDocument29 pagesAssociationAnonymous 1pDnp6XZNo ratings yet
- Exp 9Document9 pagesExp 9ansari ammanNo ratings yet
- 2020-Dec CS-719 40Document3 pages2020-Dec CS-719 40Sahil ChoudharyNo ratings yet
- Midterm F07 SolutionsDocument4 pagesMidterm F07 SolutionsKamal JackNo ratings yet
- Frequent PatternsDocument80 pagesFrequent PatternsPINKINo ratings yet
- mcd2080 Tutorial Questions 2018 03Document139 pagesmcd2080 Tutorial Questions 2018 03andreasNo ratings yet
- Lab Manual - MATLABDocument9 pagesLab Manual - MATLABSavan PatelNo ratings yet
- Finding Pattern Using Apriori Algorithm Through WEKA Tool: Chaman VermaDocument6 pagesFinding Pattern Using Apriori Algorithm Through WEKA Tool: Chaman VermaNaveenNo ratings yet
- Sequential Pattern Mining: A Comparison Between GSP, SPADE and Prefix SPANDocument21 pagesSequential Pattern Mining: A Comparison Between GSP, SPADE and Prefix SPANdeveshagNo ratings yet
- Matrix: Functional DescriptionDocument6 pagesMatrix: Functional DescriptionOthmane BoualamNo ratings yet
- 9 VectorsAndMatricesDocument8 pages9 VectorsAndMatricesMohammed AbdallahNo ratings yet
- Csi Zg518 Ec-3r First Sem 2023-2024Document8 pagesCsi Zg518 Ec-3r First Sem 2023-2024aparajithan.comcastNo ratings yet
- Bca 301Document4 pagesBca 301api-3782519No ratings yet
- Apriori AlgorithmDocument3 pagesApriori AlgorithmtoarnabchNo ratings yet
- Summative Assesment - DS - Set1Document3 pagesSummative Assesment - DS - Set1susanta satpathyNo ratings yet
- Data Mining: Department of Information Technology University of The Punjab, Jhelum CampusDocument23 pagesData Mining: Department of Information Technology University of The Punjab, Jhelum CampusMalik AwanNo ratings yet
- Mining Association Rules in Large DatabasesDocument77 pagesMining Association Rules in Large DatabasesvasulaxNo ratings yet
- Csi Zg518 Ec-3r First Sem 2023-2024Document8 pagesCsi Zg518 Ec-3r First Sem 2023-2024vewij82511No ratings yet
- 17,18,30,31Document31 pages17,18,30,31Diego CepedaNo ratings yet
- CHP 2 STAT 245 Summer 2021Document48 pagesCHP 2 STAT 245 Summer 2021Jaheda SultanaNo ratings yet
- 3) 65 (Apriori Algorithm) : Frequent Item Set in Data Set (Association Rule MiningDocument4 pages3) 65 (Apriori Algorithm) : Frequent Item Set in Data Set (Association Rule MiningSuyog TangadkarNo ratings yet
- Field of SpecializationDocument240 pagesField of SpecializationMildred Ewag50% (2)
- 8 - Cia 3 KeyDocument3 pages8 - Cia 3 KeyAshish ChowdartyNo ratings yet
- IOR Assignment 2Document3 pagesIOR Assignment 2jenny henlynNo ratings yet
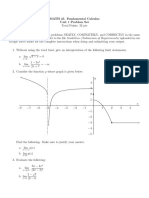
- Unit 1 Problem Set-5Document2 pagesUnit 1 Problem Set-5DanielNo ratings yet
- Assoc 1Document26 pagesAssoc 1pavithrapranuNo ratings yet
- Chapter - Determinant and MatriXDocument17 pagesChapter - Determinant and MatriXKhushbu KumariNo ratings yet
- Final AssignmentDocument4 pagesFinal AssignmentTalha TariqNo ratings yet
- BCS-012 PyqDocument92 pagesBCS-012 PyqsdfbfbbgvNo ratings yet
- Review Formulas Math 2013 For PowerpointDocument78 pagesReview Formulas Math 2013 For PowerpointJuvannie CuevaNo ratings yet
- Placement Test Without KEYDocument10 pagesPlacement Test Without KEYMichelle SavanneNo ratings yet
- Module 4-1Document153 pagesModule 4-1nigel.colaco12No ratings yet
- Week 12 - Lecture Notes Special MatricesDocument25 pagesWeek 12 - Lecture Notes Special MatricesFarheen NawaziNo ratings yet
- Association Rule MiningDocument20 pagesAssociation Rule MiningAkrem ZouabiNo ratings yet
- Factoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)From EverandFactoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)No ratings yet
- Experiment No 1: Department of Computer EngineeringDocument59 pagesExperiment No 1: Department of Computer EngineeringKenNo ratings yet
- DAC ASDM ContainerDocument53 pagesDAC ASDM ContainerKenNo ratings yet
- Laptop Setup MacDocument8 pagesLaptop Setup MacKenNo ratings yet
- Topper 2Document89 pagesTopper 2KenNo ratings yet
- Assignment No.1 (NLP)Document2 pagesAssignment No.1 (NLP)KenNo ratings yet
- University of MumbaiDocument32 pagesUniversity of MumbaiKenNo ratings yet
- Depar T Mentofappl I Edsci Encesandhumani T I Es: SR .No Experi Mentname Co PoDocument5 pagesDepar T Mentofappl I Edsci Encesandhumani T I Es: SR .No Experi Mentname Co PoKenNo ratings yet
- Gartner-Building A Data Mana 771797 NDXDocument65 pagesGartner-Building A Data Mana 771797 NDXAadi ManchandaNo ratings yet
- DBMS NotesDocument11 pagesDBMS NotesbalainsaiNo ratings yet
- Survery of Nearest NeighborDocument4 pagesSurvery of Nearest NeighborGanesh ChandrasekaranNo ratings yet
- Firebird GfixDocument29 pagesFirebird Gfixval.intan@gmail.comNo ratings yet
- Tourism Recommendation System Based On Semantic Clustering and Sentiment AnalysisDocument22 pagesTourism Recommendation System Based On Semantic Clustering and Sentiment AnalysisBruno CanalesNo ratings yet
- HCI-130-148 SummarizedDocument11 pagesHCI-130-148 SummarizedRejean IsipNo ratings yet
- Amazing Books Final Project Rubric Student AssessmentDocument2 pagesAmazing Books Final Project Rubric Student AssessmentOanaNo ratings yet
- Machine Learning and Cloud Computing: Survey of Distributed and Saas SolutionsDocument13 pagesMachine Learning and Cloud Computing: Survey of Distributed and Saas SolutionssfarithaNo ratings yet
- Chapter 1Document43 pagesChapter 1SanthoshNo ratings yet
- Strategi Pengembangan Usaha Lada Di UD. Dua Putri Bumijo Kota Yogyakarta Daerah Istimewa YogyakartaDocument15 pagesStrategi Pengembangan Usaha Lada Di UD. Dua Putri Bumijo Kota Yogyakarta Daerah Istimewa YogyakartaC2Galih Dzaky FadhlurrohmanNo ratings yet
- Objectives of DBMS:: Data AvailabilityDocument2 pagesObjectives of DBMS:: Data AvailabilitySRIHARSHANo ratings yet
- Pre SEO Analysis ReportDocument13 pagesPre SEO Analysis ReportShikha JainNo ratings yet
- UML-Library System DocumentationDocument55 pagesUML-Library System DocumentationUmakanth Nune50% (6)
- Eil Exam Pattern and SyllabusDocument1 pageEil Exam Pattern and SyllabusSai KumarNo ratings yet
- Database For Criminal Record Management SystemDocument33 pagesDatabase For Criminal Record Management SystemM.Rizwan73% (22)
- 6-Modul - PTI412 - IoT-1-2020Document17 pages6-Modul - PTI412 - IoT-1-202020200801015 Joko SulistyoNo ratings yet
- Debug InfoDocument48 pagesDebug InfoElvide MercyNo ratings yet
- Name:-Tanveer Ul Hasan: Topic To Be DiscussedDocument23 pagesName:-Tanveer Ul Hasan: Topic To Be Discussedtan999729No ratings yet
- Using PDF Files in CONTENTdmDocument23 pagesUsing PDF Files in CONTENTdmLLLNo ratings yet
- Story Board TableauDocument2 pagesStory Board Tableauswati.vijay1204No ratings yet
- Lab 5BDocument6 pagesLab 5BRoaster GuruNo ratings yet
- Brief Review On SQL and NoSQLDocument4 pagesBrief Review On SQL and NoSQLEditor IJTSRDNo ratings yet
- CSE-3421 Test #1: "Design"Document10 pagesCSE-3421 Test #1: "Design"Ishan JawaNo ratings yet
- Big Data Computing - Assignment 7Document3 pagesBig Data Computing - Assignment 7VarshaMegaNo ratings yet
- Database Final Project ReportDocument8 pagesDatabase Final Project ReportMehedi Hasan EmonNo ratings yet
- UX Design - Course - SyllabusDocument5 pagesUX Design - Course - SyllabusPradeep Patil100% (1)
- Evaluasi Desain WebsiteDocument14 pagesEvaluasi Desain WebsiteAgung NurhidayatNo ratings yet
- Master Mongodb Development For Web & Mobile Apps. Crud Operations, Indexes, Aggregation Framework - All About Mongodb!Document3 pagesMaster Mongodb Development For Web & Mobile Apps. Crud Operations, Indexes, Aggregation Framework - All About Mongodb!Ahimbisibwe BakerNo ratings yet
- VTAG - Service Management Proposal - v2.3.3Document16 pagesVTAG - Service Management Proposal - v2.3.3anzzar.storeNo ratings yet
- Data Mining Based Cyber-Attack Detection: Tianfield, HuagloryDocument18 pagesData Mining Based Cyber-Attack Detection: Tianfield, HuagloryCésar Javier Montaña RojasNo ratings yet