Download as docx, pdf, or txt
You might also like
- The Ultimate Guide To Drum Programming - EDMProdDocument32 pagesThe Ultimate Guide To Drum Programming - EDMProdSteveJones100% (4)
- Tandardized Est of Nglish Roficiency: S T E PDocument80 pagesTandardized Est of Nglish Roficiency: S T E Pmo moNo ratings yet
- Designing Out PlagiarismDocument2 pagesDesigning Out PlagiarismmischlercNo ratings yet
- Introduction To Criminology (Review Materials For 2013 Criminology Board Examination)Document43 pagesIntroduction To Criminology (Review Materials For 2013 Criminology Board Examination)Clarito Lopez88% (33)
- PSYC6213 DQ 2.2 ResourcesDocument5 pagesPSYC6213 DQ 2.2 ResourceshibasaleemmNo ratings yet
- Grade 8: Module 4: Unit 2Document260 pagesGrade 8: Module 4: Unit 2leshea JOHNNo ratings yet
- Basics of Social Research Canadian 3rd Edition Neuman Solutions Manual 1Document23 pagesBasics of Social Research Canadian 3rd Edition Neuman Solutions Manual 1michaelhardingkawrzocynq100% (39)
- Basics of Social Research Canadian 3rd Edition Neuman Solutions Manual 1Document17 pagesBasics of Social Research Canadian 3rd Edition Neuman Solutions Manual 1james100% (44)
- Basics of Social Research Canadian 3Rd Edition Neuman Solutions Manual Full Chapter PDFDocument36 pagesBasics of Social Research Canadian 3Rd Edition Neuman Solutions Manual Full Chapter PDFrobert.crape569100% (21)
- Cox 2013Document10 pagesCox 2013gopinaik8336No ratings yet
- The Repertory Grid:: Eliciting User Experience Comparisons in The Customer'S VoiceDocument4 pagesThe Repertory Grid:: Eliciting User Experience Comparisons in The Customer'S VoicespdeyNo ratings yet
- Solution Manual For An Invitation To Social Research How Its Done 5th EditionDocument7 pagesSolution Manual For An Invitation To Social Research How Its Done 5th EditionKaraWalkerixpe100% (44)
- HOw To Write Review1Document33 pagesHOw To Write Review1Dr.Neelam JainNo ratings yet
- Assessment Article Review 2Document4 pagesAssessment Article Review 2api-333320887No ratings yet
- SyllabusLSC 0S1 2400 Jan024 PDFDocument7 pagesSyllabusLSC 0S1 2400 Jan024 PDFJou BarzolaNo ratings yet
- Hand-In Assignment - Chapter 1Document3 pagesHand-In Assignment - Chapter 1Mike ParisiNo ratings yet
- Example of Chapter 4 Qualitative ThesisDocument6 pagesExample of Chapter 4 Qualitative Thesiskellybyersdesmoines100% (2)
- 4TH Q - WEEK 1 - Chapter 1Document22 pages4TH Q - WEEK 1 - Chapter 1Cristina TolentinoNo ratings yet
- Dissertation Proposal TemplateDocument7 pagesDissertation Proposal TemplateHazel Jhoy Del MundoNo ratings yet
- The Research ProposalDocument7 pagesThe Research ProposalRenz Olex M. CanlasNo ratings yet
- Artículo de UsabilidadDocument10 pagesArtículo de UsabilidadANA BELEN LARA ORTIZNo ratings yet
- Chapter 1Document23 pagesChapter 1Grald Traifalgar Patrick ShawNo ratings yet
- NISU CC Fundamentals and Guide in Thesis and Dissertation Writing of TED FINALDocument23 pagesNISU CC Fundamentals and Guide in Thesis and Dissertation Writing of TED FINALGrald Traifalgar Patrick ShawNo ratings yet
- Chapter 0 IntroductionDocument14 pagesChapter 0 IntroductionHomaya ZumiNo ratings yet
- CORE104 W10S1 CriticalReviewWorkshopDocument47 pagesCORE104 W10S1 CriticalReviewWorkshopKoha TrầnNo ratings yet
- Cdlis Proposal FormatDocument9 pagesCdlis Proposal FormatPushpanjali Herbal TradersNo ratings yet
- Chapter 1 Problem and Its BackgroundDocument17 pagesChapter 1 Problem and Its BackgroundClint WilliamsNo ratings yet
- Book For DsDocument69 pagesBook For DsBala JiNo ratings yet
- Research GuidelineDocument50 pagesResearch Guidelineyassinabdulmalik85No ratings yet
- A New Intelligent Tutoring System : Lindsey FordDocument8 pagesA New Intelligent Tutoring System : Lindsey FordLydia LeeNo ratings yet
- Literature Review 11 Oktober 2021Document22 pagesLiterature Review 11 Oktober 2021Siti AisyahNo ratings yet
- Contributing Authors: Book Reviews 247Document6 pagesContributing Authors: Book Reviews 247Nany Suhaila Bt ZolkeflyNo ratings yet
- Capstone-Ict12 2020 Scat-1Document46 pagesCapstone-Ict12 2020 Scat-1nprovido51No ratings yet
- Methods of Research ReviewerDocument10 pagesMethods of Research ReviewerCorazon R. LabasanoNo ratings yet
- Guidelines For Multiple-Choice Items: Illustrative Item 5.35Document18 pagesGuidelines For Multiple-Choice Items: Illustrative Item 5.35Yhona ArindaNo ratings yet
- Indicators Are Key in Learning ArgumentDocument12 pagesIndicators Are Key in Learning Argumenthnif2009No ratings yet
- Local Media8865838383823137779Document7 pagesLocal Media8865838383823137779Sharra DayritNo ratings yet
- Dwnload Full Sociology A Brief Introduction Canadian 6th Edition Schaefer Solutions Manual PDFDocument35 pagesDwnload Full Sociology A Brief Introduction Canadian 6th Edition Schaefer Solutions Manual PDFthioxenegripe.55vd100% (11)
- Research and Development in The TeachingDocument5 pagesResearch and Development in The TeachingAlex GarciaNo ratings yet
- Full Download Sociology A Brief Introduction Canadian 6th Edition Schaefer Solutions ManualDocument35 pagesFull Download Sociology A Brief Introduction Canadian 6th Edition Schaefer Solutions Manualmasonpd59n100% (47)
- Olivia Models-1Document18 pagesOlivia Models-1Guyan GordonNo ratings yet
- Ks2 English 2011 Level 6 Reading Marking SchemeDocument32 pagesKs2 English 2011 Level 6 Reading Marking SchemeNasrin PeaksNo ratings yet
- Tugas METLIT - Cinta Meilika - 222040 - 2B - S1-IndividuDocument5 pagesTugas METLIT - Cinta Meilika - 222040 - 2B - S1-Individucintameilika854No ratings yet
- Miller Qualitative Article Critique AssignmentDocument2 pagesMiller Qualitative Article Critique Assignmentapi-283597245No ratings yet
- Course Outline: All Undergraduate ProgrammesDocument5 pagesCourse Outline: All Undergraduate ProgrammesLai Yi, Natalie NGNo ratings yet
- Adult, Community, and Professional Learning: The Role of Recursive FeedbackDocument28 pagesAdult, Community, and Professional Learning: The Role of Recursive FeedbackdocjorseNo ratings yet
- Micromax CEC MBA 1st SEMDocument22 pagesMicromax CEC MBA 1st SEMVinay SavaniNo ratings yet
- Expert Concept Mapping Study On Mobile Learning: PurposeDocument15 pagesExpert Concept Mapping Study On Mobile Learning: PurposeJuan BendeckNo ratings yet
- Plan and Procedures For The Study: Nature/Type of StudyDocument20 pagesPlan and Procedures For The Study: Nature/Type of StudyHelena TurnipNo ratings yet
- Misamis Oriental Institute of Science and Technology: Course Code: Module No. Course Title: DateDocument9 pagesMisamis Oriental Institute of Science and Technology: Course Code: Module No. Course Title: DateJeneviveNo ratings yet
- Question Bank For University Questions For 2 YearsDocument6 pagesQuestion Bank For University Questions For 2 Yearssubakarthi100% (1)
- 2.1 Action Research Framework AAM - JLSDocument11 pages2.1 Action Research Framework AAM - JLSMia AgatoNo ratings yet
- Using Metacognitive To Promote LearningDocument9 pagesUsing Metacognitive To Promote LearningNuraihan HashimNo ratings yet
- Evaluating A Personal Questionnaire Method For The Appraisal of Student ConcernsDocument66 pagesEvaluating A Personal Questionnaire Method For The Appraisal of Student ConcernsArjun PanditaNo ratings yet
- Psych IA Final Draft - Aliza BaigDocument20 pagesPsych IA Final Draft - Aliza BaigAliza BaigNo ratings yet
- What Is The Value of Course-Specific Learning Goals?: by Beth Simon and Jared TaylorDocument6 pagesWhat Is The Value of Course-Specific Learning Goals?: by Beth Simon and Jared TaylorballechaseNo ratings yet
- Alternative Assessment and Second Language Study What and WhyDocument7 pagesAlternative Assessment and Second Language Study What and WhyCelina Kich De RéNo ratings yet
- Format of A Thesis/Dissertation ReportDocument11 pagesFormat of A Thesis/Dissertation ReportCarl Joshua TorresNo ratings yet
- Effective Planning Strategies and Proposal Writing: A Workbook for Helping ProfessionalsFrom EverandEffective Planning Strategies and Proposal Writing: A Workbook for Helping ProfessionalsNo ratings yet
- What Motivates Faculty to Teach in Distance Education?: A Case Study and Meta-Literature ReviewFrom EverandWhat Motivates Faculty to Teach in Distance Education?: A Case Study and Meta-Literature ReviewNo ratings yet
- Assessment and Feedback in Higher Education: A Guide for TeachersFrom EverandAssessment and Feedback in Higher Education: A Guide for TeachersRating: 5 out of 5 stars5/5 (1)
- Competence and Program-based Approach in Training: Tools for Developing Responsible ActivitiesFrom EverandCompetence and Program-based Approach in Training: Tools for Developing Responsible ActivitiesCatherine LoisyNo ratings yet
- PestleDocument11 pagesPestleapi-641548996No ratings yet
- TJ Maxx and MarshallsDocument12 pagesTJ Maxx and Marshallsapi-641548996No ratings yet
- Retail Comparison Paper 1Document12 pagesRetail Comparison Paper 1api-641548996No ratings yet
- Branding and TrademarkDocument9 pagesBranding and Trademarkapi-641548996No ratings yet
- Groft Charity Classic PresentationDocument55 pagesGroft Charity Classic Presentationapi-641548996No ratings yet
- Experimental ReportDocument12 pagesExperimental Reportapi-641548996No ratings yet
- Individual Media Alert 1Document2 pagesIndividual Media Alert 1api-641548996No ratings yet
- Fisher Survey ReportDocument15 pagesFisher Survey Reportapi-641548996No ratings yet
- Fisherholding StatementDocument2 pagesFisherholding Statementapi-641548996No ratings yet
- Fisher Op-EdDocument2 pagesFisher Op-Edapi-641548996No ratings yet
- Fisher Press ReleaseDocument2 pagesFisher Press Releaseapi-641548996No ratings yet
- ROWEB 03638 Mia UKDocument4 pagesROWEB 03638 Mia UKNounaNo ratings yet
- Solid Edge Mold ToolingDocument3 pagesSolid Edge Mold ToolingVetrivendhan SathiyamoorthyNo ratings yet
- TRP 8750DDocument276 pagesTRP 8750DKentNo ratings yet
- 1 Cyber Law PDFDocument2 pages1 Cyber Law PDFKRISHNA VIDHUSHANo ratings yet
- Passive Form (1) This Test Comes From - The Site To Learn English (Test N°5733)Document2 pagesPassive Form (1) This Test Comes From - The Site To Learn English (Test N°5733)Maria Rajendran MNo ratings yet
- WikiHow Is An Online WikiDocument4 pagesWikiHow Is An Online Wikiksdnfi ouvynNo ratings yet
- Group2 Non Executive ResultsDocument3 pagesGroup2 Non Executive ResultsGottimukkala MuralikrishnaNo ratings yet
- My Job at The Crescent Falls Diner and EssayDocument6 pagesMy Job at The Crescent Falls Diner and EssayAsya Faudhatul InayyahNo ratings yet
- B1.1-Self-Study Đã Sài XongDocument5 pagesB1.1-Self-Study Đã Sài XongVy CẩmNo ratings yet
- LAS - Week 3 FunctionsDocument15 pagesLAS - Week 3 FunctionsLeywila Mae Yo BianesNo ratings yet
- Martin Luther King Jr. - A True Historical Examination. (N.D.) - Retrieved OctoberDocument5 pagesMartin Luther King Jr. - A True Historical Examination. (N.D.) - Retrieved Octoberapi-336574490No ratings yet
- It 429 - Week 11Document11 pagesIt 429 - Week 11mjdcan_563730775No ratings yet
- Architecture in EthDocument4 pagesArchitecture in Ethmelakumikias2No ratings yet
- Lesson Plans For English Form 5Document2 pagesLesson Plans For English Form 5Hajar Binti Md SaidNo ratings yet
- Hots Advance MiraeDocument36 pagesHots Advance MiraeHabibie BoilerNo ratings yet
- Form PDF 870914450231220Document8 pagesForm PDF 870914450231220Sachin KumarNo ratings yet
- KFC SongsDocument95 pagesKFC SongsKent PalmaNo ratings yet
- Harvatek Corp. v. Nichia Corp. - ComplaintDocument51 pagesHarvatek Corp. v. Nichia Corp. - ComplaintSarah BursteinNo ratings yet
- Job Description - CRM Marketing SpecialistDocument1 pageJob Description - CRM Marketing SpecialistMichael-SNo ratings yet
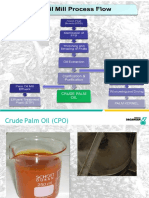
- Palm Oil MillDocument52 pagesPalm Oil MillengrsurifNo ratings yet
- Forms of Energy (Tutorial Part 2)Document3 pagesForms of Energy (Tutorial Part 2)asapamore100% (1)
- Leadership in Virtual TeamsDocument13 pagesLeadership in Virtual TeamsBrandon ManuelNo ratings yet
- 2013 848evo DucatiOmahaDocument140 pages2013 848evo DucatiOmahaFabian Alejandro Ramos SandovalNo ratings yet
- Permanent Hair Dye ColorantsDocument37 pagesPermanent Hair Dye ColorantsAntonio Perez MolinaNo ratings yet
- DLL WK 10 LC 171819Document14 pagesDLL WK 10 LC 171819Regiel Guiang ArnibalNo ratings yet
- Adetunji CVDocument5 pagesAdetunji CVAdetunji AdegbiteNo ratings yet
- International Documentary Festival of Ierapetra Awards - 2016 ProgrammeDocument26 pagesInternational Documentary Festival of Ierapetra Awards - 2016 ProgrammeZois PagNo ratings yet
- Mass Transfer in Fermentation ProcessDocument5 pagesMass Transfer in Fermentation ProcessSimone Bassan Zuicker ElizeuNo ratings yet