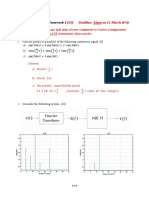
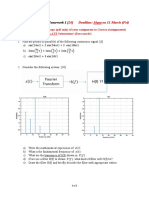
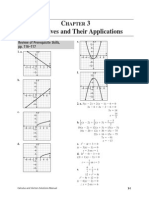
Download as pdf or txt
You might also like
- Solution Manual For Differential Equations and Linear Algebra 4th Edition by Goode ISBN 0321964675 9780321964670Document36 pagesSolution Manual For Differential Equations and Linear Algebra 4th Edition by Goode ISBN 0321964675 9780321964670jenniferwatersgbrcixdmzt100% (30)
- BP Approved Connection ListDocument10 pagesBP Approved Connection ListEDWIN M.PNo ratings yet
- Kloud Activity Final Activity2Document4 pagesKloud Activity Final Activity2no directionNo ratings yet
- Selection Criteria For EnginesDocument13 pagesSelection Criteria For EnginesVeda Prasad. RNo ratings yet
- Lesson 1 KeyDocument21 pagesLesson 1 KeyChristina LeeNo ratings yet
- Homework 1 SolDocument4 pagesHomework 1 SolELF7878No ratings yet
- Lab Session 04Document3 pagesLab Session 04MudassarNo ratings yet
- Matlab PrimerDocument10 pagesMatlab PrimerArthur RamosNo ratings yet
- Lab Wk1soln PDFDocument14 pagesLab Wk1soln PDFPeper12345No ratings yet
- Sol Tor CsabaDocument118 pagesSol Tor CsabaleeaxilNo ratings yet
- Pulp and Paper IndustryDocument2 pagesPulp and Paper IndustryjantskieNo ratings yet
- X-Bar and R Chart Observation TableDocument2 pagesX-Bar and R Chart Observation TableAman YadavNo ratings yet
- Hazard2Markov-Ver1 0Document5 pagesHazard2Markov-Ver1 0Nico FriedmannNo ratings yet
- Tutorials 3Document18 pagesTutorials 3z_k_j_vNo ratings yet
- Solution Manual For Differential Equations and Linear Algebra 4Th Edition by Goode Isbn 0321964675 9780321964670 Full Chapter PDFDocument36 pagesSolution Manual For Differential Equations and Linear Algebra 4Th Edition by Goode Isbn 0321964675 9780321964670 Full Chapter PDFsandra.montelongo651100% (12)
- Jan. 25, 2010 Homework 1 Solutions 6.094: Introduction To MatlabDocument10 pagesJan. 25, 2010 Homework 1 Solutions 6.094: Introduction To MatlabAbelo AgarNo ratings yet
- Problems On Sums and IntegralsDocument15 pagesProblems On Sums and IntegralsDevendraReddyPoreddyNo ratings yet
- Design RCC 2 Storey BuildingDocument37 pagesDesign RCC 2 Storey BuildingjansenrosesNo ratings yet
- LAB 10 RISC-V Assembly (Part II) : EE-222 Microprocessor SystemsDocument5 pagesLAB 10 RISC-V Assembly (Part II) : EE-222 Microprocessor SystemsShanawar AliNo ratings yet
- Jadual Susut Voltan (Single Core Cable) (TABLE 4D1B) : Lampiran IVDocument1 pageJadual Susut Voltan (Single Core Cable) (TABLE 4D1B) : Lampiran IVzfn2rqvqgqNo ratings yet
- ELEC1010 Homework 1Document2 pagesELEC1010 Homework 1ELF7878No ratings yet
- Speed Time GraphsDocument18 pagesSpeed Time GraphsJuan Carlo MarmolejoNo ratings yet
- HhahaDocument6 pagesHhahasofhiaputriNo ratings yet
- 1.0.0-Oscillations-Simple Pendulum-Set-2-Qp-MsDocument19 pages1.0.0-Oscillations-Simple Pendulum-Set-2-Qp-Msevans kesiilweNo ratings yet
- Eco 570 AssignDocument10 pagesEco 570 AssignMaryam KhanNo ratings yet
- FinalreportDocument21 pagesFinalreportOskar von waldenfelsNo ratings yet
- Assignment 1 MATH 1052Document2 pagesAssignment 1 MATH 1052KONAL PURINo ratings yet
- AQA Physics: AS Required Practical Report 3: "Determination of G by A Free-Fall Method" Liam WrightDocument5 pagesAQA Physics: AS Required Practical Report 3: "Determination of G by A Free-Fall Method" Liam WrightliamNo ratings yet
- EE Comp MATLAB Activity 3Document8 pagesEE Comp MATLAB Activity 3Reneboy LambarteNo ratings yet
- Mass Spectra Worksheet 1Document5 pagesMass Spectra Worksheet 13estherNo ratings yet
- Modified Rain Ow Counting Algorithm For Fatigue Life CalculationDocument6 pagesModified Rain Ow Counting Algorithm For Fatigue Life Calculationsrivathsan vivekNo ratings yet
- Rata-Rata: Kode LabDocument8 pagesRata-Rata: Kode LabFeny Anisa SetiaNo ratings yet
- High Performance Computing of Fluid DynamicsDocument22 pagesHigh Performance Computing of Fluid DynamicsOskar von waldenfelsNo ratings yet
- WS Overview of Graphical AnalysisDocument4 pagesWS Overview of Graphical AnalysismiguelhemarinaNo ratings yet
- Calculating Spearman's Rank Correlation Coefficient Using Technology - IBDP Mathematics - Applications and Interpretation SL FE2021 - KognityDocument4 pagesCalculating Spearman's Rank Correlation Coefficient Using Technology - IBDP Mathematics - Applications and Interpretation SL FE2021 - KognityMirjeta ZymeriNo ratings yet
- M-C - Y Q M: Theory Alabi AU Uantum EchanicsDocument177 pagesM-C - Y Q M: Theory Alabi AU Uantum EchanicsvalterbrigoNo ratings yet
- Sample FinalDocument10 pagesSample FinalsharadpjadhavNo ratings yet
- CidrDocument9 pagesCidrit_expertNo ratings yet
- Flexural Beam Design As - A's - EC - EngineeringPrograms - FullDocument7 pagesFlexural Beam Design As - A's - EC - EngineeringPrograms - FulldivyareddyNo ratings yet
- TimeSeries SARIMADocument15 pagesTimeSeries SARIMAHofidisNo ratings yet
- Dwnload Full Understanding Basic Statistics Enhanced 7th Edition Brase Solutions Manual PDFDocument36 pagesDwnload Full Understanding Basic Statistics Enhanced 7th Edition Brase Solutions Manual PDFpondoptionv5100% (12)
- Numerical Method V2Document60 pagesNumerical Method V2sh0755835No ratings yet
- Math 64Document5 pagesMath 64BEDZIGANo ratings yet
- Week-3 Session 2Document22 pagesWeek-3 Session 2Vinshi JainNo ratings yet
- OlinDocument25 pagesOlinLens WipesNo ratings yet
- 5 Smooth Square Footing On A Cohesive Frictionless Material: 5.1 Problem StatementDocument8 pages5 Smooth Square Footing On A Cohesive Frictionless Material: 5.1 Problem Statementseif17No ratings yet
- Lecture 3 Graphical Representation IIDocument21 pagesLecture 3 Graphical Representation IIsuman shresthaNo ratings yet
- ZZHW EigDocument2 pagesZZHW EigShak ShakNo ratings yet
- Patter Recognition (Spring 2014) Midterm ExamDocument5 pagesPatter Recognition (Spring 2014) Midterm ExamranaNo ratings yet
- Lab 5Document11 pagesLab 5Waleed Bashir KotlaNo ratings yet
- Exercises CE StatisticDocument12 pagesExercises CE StatisticSky FireNo ratings yet
- BSD Concrete 5th Dec (Ishikawa)Document31 pagesBSD Concrete 5th Dec (Ishikawa)mrsue99 mrNo ratings yet
- Orbit Determination Accuracy RequirementDocument16 pagesOrbit Determination Accuracy RequirementFrancisco CarvalhoNo ratings yet
- Sds322project 2 Jannu KarthikDocument19 pagesSds322project 2 Jannu Karthikapi-599289473No ratings yet
- Hydrographic SurveysDocument6 pagesHydrographic SurveysKelly P. DionisioNo ratings yet
- Hirata Et Al 2008Document10 pagesHirata Et Al 2008Sebastian WallotNo ratings yet
- The Periodic Motion of A Pendulum: /conversion/tmp/activity - Task - Scratch/544523685Document9 pagesThe Periodic Motion of A Pendulum: /conversion/tmp/activity - Task - Scratch/544523685Maria Lourdes FranciscoNo ratings yet
- Chapter 3 Solutions CalculusDocument83 pagesChapter 3 Solutions CalculusDanielChanNo ratings yet
- LSDDocument7 pagesLSDkasuwedaNo ratings yet
- Year 3 - CA5 Mar 23, 2022 Algebra 4 & 5, Graphs 4, Handling Data 3Document9 pagesYear 3 - CA5 Mar 23, 2022 Algebra 4 & 5, Graphs 4, Handling Data 3rh6ymtjzbyNo ratings yet
- A Hierarchy of Turing Degrees: A Transfinite Hierarchy of Lowness Notions in the Computably Enumerable Degrees, Unifying Classes, and Natural Definability (AMS-206)From EverandA Hierarchy of Turing Degrees: A Transfinite Hierarchy of Lowness Notions in the Computably Enumerable Degrees, Unifying Classes, and Natural Definability (AMS-206)No ratings yet
- Quasi-Monte Carlo Methods in Finance: With Application to Optimal Asset AllocationFrom EverandQuasi-Monte Carlo Methods in Finance: With Application to Optimal Asset AllocationNo ratings yet
- Lab 1Document8 pagesLab 1Нурболат ТаласбайNo ratings yet
- HW 5Document6 pagesHW 5Нурболат ТаласбайNo ratings yet
- HW 8Document6 pagesHW 8Нурболат ТаласбайNo ratings yet
- HS 620 630 User GuideDocument22 pagesHS 620 630 User GuideНурболат ТаласбайNo ratings yet
- HS 620 Vibration MeterDocument2 pagesHS 620 Vibration MeterНурболат ТаласбайNo ratings yet
- Non-Current Asset Held For Sale - NotesDocument4 pagesNon-Current Asset Held For Sale - NotesMARCUAP Flora Mel Joy H.No ratings yet
- Payment OptionsDocument2 pagesPayment OptionsDanson Githinji ENo ratings yet
- Webdriver CodeDocument3 pagesWebdriver CodejailaxmieceNo ratings yet
- L6 - Shear and Moment DiagramsDocument11 pagesL6 - Shear and Moment DiagramsSuman BhattaraiNo ratings yet
- Action Plan in General Parents and Teacher AssociationDocument2 pagesAction Plan in General Parents and Teacher Associationdina olayon100% (16)
- Introducing Hitachi Storage ArchitectureDocument210 pagesIntroducing Hitachi Storage ArchitecturevcosminNo ratings yet
- Transformer Fire ProtectionDocument13 pagesTransformer Fire ProtectionHermi DavidNo ratings yet
- English Language Paper 2Document24 pagesEnglish Language Paper 2Ahmed MahmoudNo ratings yet
- Bussiness MathematicsDocument3 pagesBussiness MathematicsPatric CletusNo ratings yet
- Dfe Brochure Osd Def Web-1Document6 pagesDfe Brochure Osd Def Web-1jessica febeNo ratings yet
- Fundamentals of Information Systems PDFDocument164 pagesFundamentals of Information Systems PDFharshithaNo ratings yet
- Sheria Petroleum Act 2015 Updated Version 15 6Document163 pagesSheria Petroleum Act 2015 Updated Version 15 6momo177sasaNo ratings yet
- NCM 112 EvalDocument16 pagesNCM 112 EvalMartin T ManuelNo ratings yet
- Switches and Disconnects Series M-ForceDocument12 pagesSwitches and Disconnects Series M-ForceCarlos AguiarNo ratings yet
- ISC Biotechnology 2026Document12 pagesISC Biotechnology 2026asNo ratings yet
- (Download PDF) Foundations of Mobile Radio Engineering First Edition Yacoub Online Ebook All Chapter PDFDocument42 pages(Download PDF) Foundations of Mobile Radio Engineering First Edition Yacoub Online Ebook All Chapter PDFarturo.williams321100% (13)
- Ratio Analysis Heritage Foods Ltd-2Document64 pagesRatio Analysis Heritage Foods Ltd-2Varun ThatiNo ratings yet
- S2A F Datasheet en GBDocument4 pagesS2A F Datasheet en GBAzhar AliNo ratings yet
- Monday November 25, 2020 Turnover and Net Profit Learning ObjectivesDocument3 pagesMonday November 25, 2020 Turnover and Net Profit Learning ObjectivesChikanma OkoisorNo ratings yet
- MQREIT Circular 22 11 2016Document137 pagesMQREIT Circular 22 11 2016fefefNo ratings yet
- 2021 Global Marketing Trends - PartDocument15 pages2021 Global Marketing Trends - PartGuy Bertrand MessinaNo ratings yet
- AFV - Modeller July-Aug 2016Document68 pagesAFV - Modeller July-Aug 2016Prplknite100% (5)
- Uv VarnishDocument4 pagesUv VarnishditronzNo ratings yet
- Gujarat Technological University: W.E.F. AY 2018-19Document3 pagesGujarat Technological University: W.E.F. AY 2018-19Bhavesh PatelNo ratings yet
- HyperthermiaDocument5 pagesHyperthermiaRapunzel Leanne100% (1)
- Lecture 1 Airport - Intro 2180602Document52 pagesLecture 1 Airport - Intro 2180602Ujjval Solanki67% (3)
- Share Capital Materials-1 (Theory and Framework)Document18 pagesShare Capital Materials-1 (Theory and Framework)Joydeep DuttaNo ratings yet