
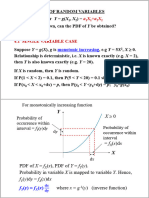
StatIdea Slides 5
StatIdea Slides 5
You might also like
- Dark Demon - Christine FeehanDocument4 pagesDark Demon - Christine Feehantheresa1970No ratings yet
- STAT2011 2017 Exam Formulae PDFDocument3 pagesSTAT2011 2017 Exam Formulae PDFeccentricftw4No ratings yet
- SMA 2231 Probability and Statistics IIIDocument89 pagesSMA 2231 Probability and Statistics III001亗PRÍËšT亗No ratings yet
- StatIdea Slides 2Document55 pagesStatIdea Slides 2xinmiao wangNo ratings yet
- StatIdea Slides 4Document97 pagesStatIdea Slides 4xinmiao wangNo ratings yet
- Cheat SheetDocument2 pagesCheat SheetVarun NagpalNo ratings yet
- Unit 4: PTSP Unit Iv Questions & AnswersDocument10 pagesUnit 4: PTSP Unit Iv Questions & AnswerssrinivasNo ratings yet
- Two Dimensional Random VariableDocument4 pagesTwo Dimensional Random VariableRajaRaman.GNo ratings yet
- Chapter 3Document38 pagesChapter 3Dina AssefaNo ratings yet
- 8mmpjoint AnnotatedDocument25 pages8mmpjoint AnnotatedAntal TóthNo ratings yet
- Lect6 PDFDocument11 pagesLect6 PDFMarco CocchiNo ratings yet
- Slides 2 PDFDocument110 pagesSlides 2 PDFMansoor SaleemNo ratings yet
- P8-Properties of DistributionsDocument12 pagesP8-Properties of Distributionsching chauNo ratings yet
- 1 Probability Density Functions (PDF) : PropertiesDocument6 pages1 Probability Density Functions (PDF) : PropertiesFariza MakhayNo ratings yet
- MCMC: Gibbs Sampling: D K k1 k+1 DDocument7 pagesMCMC: Gibbs Sampling: D K k1 k+1 DDevendraReddyPoreddyNo ratings yet
- Probability Theory - Formula SheetDocument13 pagesProbability Theory - Formula SheettommielombartsNo ratings yet
- Functions of Random VariablesDocument13 pagesFunctions of Random Variablescharlotte.chua03No ratings yet
- Chapter 8Document52 pagesChapter 8islamNo ratings yet
- Functions of Random Variables PDFDocument15 pagesFunctions of Random Variables PDFVatan JhaNo ratings yet
- Chapter 0Document13 pagesChapter 0nargizireNo ratings yet
- 1 What Is A Random Variable (R.V.) ?Document6 pages1 What Is A Random Variable (R.V.) ?Eric VonFreemanNo ratings yet
- Joint Random Variables 1Document11 pagesJoint Random Variables 1Letsogile BaloiNo ratings yet
- Statistics 116 - Fall 2004 Theory of Probability Practice Final # 2 - SolutionsDocument7 pagesStatistics 116 - Fall 2004 Theory of Probability Practice Final # 2 - SolutionsKrishna Chaitanya SrikantaNo ratings yet
- Lecture 2Document43 pagesLecture 2pamelasedimoNo ratings yet
- Lecture 2Document27 pagesLecture 2aman workinehNo ratings yet
- Lecture #11: Distributions With Random ParametersDocument3 pagesLecture #11: Distributions With Random ParametersmohamedNo ratings yet
- Final For MultivariateDocument73 pagesFinal For MultivariateAishwarya RamNo ratings yet
- Notes MTH S 504 (Lecture-02-03 Notes)Document32 pagesNotes MTH S 504 (Lecture-02-03 Notes)Priyanshu GuptaNo ratings yet
- Homework 3 SolutionsDocument6 pagesHomework 3 SolutionsislayerNo ratings yet
- Tutorial Sheet 2Document3 pagesTutorial Sheet 2Psycho MindNo ratings yet
- UW MATH-STAT395 Bivariate-Distributions PDFDocument17 pagesUW MATH-STAT395 Bivariate-Distributions PDFPraney handaNo ratings yet
- Conditional Expectation For Discrete Random Variables: AgendaDocument5 pagesConditional Expectation For Discrete Random Variables: Agendazakir abbasNo ratings yet
- S.Y.B.Sc. Mathematics (MTH - 211) Question BankDocument14 pagesS.Y.B.Sc. Mathematics (MTH - 211) Question BankAbrar MalikNo ratings yet
- My Notes For Discrete and Continuous Distributions 987654Document28 pagesMy Notes For Discrete and Continuous Distributions 987654Shah FahadNo ratings yet
- HW6Document4 pagesHW6Pallavi RaiturkarNo ratings yet
- Problems On Two Dimensional Random VariableDocument15 pagesProblems On Two Dimensional Random VariableBRAHMA REDDY AAKUMAIIA100% (1)
- Stat276 Chapter 6Document9 pagesStat276 Chapter 6Onetwothree Tube100% (2)
- Generalized Linear Models: FX Axb C DX Axb C DXDocument11 pagesGeneralized Linear Models: FX Axb C DX Axb C DXAishat OmotolaNo ratings yet
- M5A42 Applied Stochastic Processes Problem Sheet 1 Solutions Term 1 2010-2011Document8 pagesM5A42 Applied Stochastic Processes Problem Sheet 1 Solutions Term 1 2010-2011paradoxNo ratings yet
- G (X) F (X, Y) : Marginal Distributions Definition 5Document13 pagesG (X) F (X, Y) : Marginal Distributions Definition 5Kimondo KingNo ratings yet
- Prob ReviewDocument19 pagesProb ReviewSiva Kumar GaniNo ratings yet
- E20214 Math Econ 07 Concave Convex Functions Convex Sets Homogeneous FunctionsDocument11 pagesE20214 Math Econ 07 Concave Convex Functions Convex Sets Homogeneous FunctionsJohn ChanNo ratings yet
- HW 2 SolutionDocument7 pagesHW 2 SolutionAnonymous 9qJCv5mC0No ratings yet
- Sma 2201Document35 pagesSma 2201Andrew MutungaNo ratings yet
- Assignment 6 Solutions IIIDocument2 pagesAssignment 6 Solutions IIIindianpinkNo ratings yet
- Joint Distributions: He ShuangchiDocument36 pagesJoint Distributions: He ShuangchiZhengYang ChinNo ratings yet
- Portugaliae Mathematica Vol. 58 Fasc. 2 - 2001 Nova S Erie: Presented by J.P. DiasDocument20 pagesPortugaliae Mathematica Vol. 58 Fasc. 2 - 2001 Nova S Erie: Presented by J.P. DiasVayo SonyNo ratings yet
- Differential Equations 2Document2 pagesDifferential Equations 2Prince WilliamNo ratings yet
- Joint Probability FunctionsDocument7 pagesJoint Probability FunctionsBran RelieveNo ratings yet
- DX Dy y X F W: IndependentDocument13 pagesDX Dy y X F W: IndependentdNo ratings yet
- Simple Linear Regression.: 29.1 Method of Least SquaresDocument4 pagesSimple Linear Regression.: 29.1 Method of Least SquaresDebashis GuptaNo ratings yet
- DSC6132: Probability and Statistical Modelling: Lecture 4: Multivariate Random VariablesDocument55 pagesDSC6132: Probability and Statistical Modelling: Lecture 4: Multivariate Random VariablesJOHNNo ratings yet
- Assignment1 SolDocument4 pagesAssignment1 SolVetreivel KNo ratings yet
- 1.probability Random Variables and Stochastic Processes Athanasios Papoulis S. Unnikrishna Pillai 1 300 181 210Document30 pages1.probability Random Variables and Stochastic Processes Athanasios Papoulis S. Unnikrishna Pillai 1 300 181 210AlvaroNo ratings yet
- Tutorial 5Document9 pagesTutorial 5RajMohanNo ratings yet
- Joint Density Function: - , 0 ,), ( y X y X e y X FDocument4 pagesJoint Density Function: - , 0 ,), ( y X y X e y X FRamuroshini GNo ratings yet
- Pair of RVsDocument20 pagesPair of RVsHải Vũ TrầnNo ratings yet
- Differential EquationsDocument3 pagesDifferential Equationsme21b002No ratings yet
- Probability: Problem Set 4 - SolutionsDocument4 pagesProbability: Problem Set 4 - SolutionsMary RomeroNo ratings yet
- Unit II - SjitDocument32 pagesUnit II - SjitShreyaNo ratings yet
- StatIdea Slides 2Document55 pagesStatIdea Slides 2xinmiao wangNo ratings yet
- StatIdea Slides 4Document97 pagesStatIdea Slides 4xinmiao wangNo ratings yet
- StatIdea Slides 3Document86 pagesStatIdea Slides 3xinmiao wangNo ratings yet
- StatIdea Slides 1Document53 pagesStatIdea Slides 1xinmiao wangNo ratings yet
- Guzavicius 2014 - Behavioural Finance - Corporate Social Responsibility ApproachDocument6 pagesGuzavicius 2014 - Behavioural Finance - Corporate Social Responsibility Approachxinmiao wangNo ratings yet
- University of Cebu - Main Campus College of Teacher Education Sanciangko Street, Cebu City SECOND SEMESTER 2020-2021 TC Ec 322 - Enhancement Course 2Document4 pagesUniversity of Cebu - Main Campus College of Teacher Education Sanciangko Street, Cebu City SECOND SEMESTER 2020-2021 TC Ec 322 - Enhancement Course 2FatimaNo ratings yet
- Towards Being A HumanDocument53 pagesTowards Being A HumanlarenNo ratings yet
- Research ProposalDocument19 pagesResearch ProposalNkk Khn100% (1)
- Wildlife CurriculumDocument70 pagesWildlife Curriculumapi-240926941100% (1)
- Stage 1 Name of The Students:: English IiiDocument6 pagesStage 1 Name of The Students:: English IiiRussell Najera RejonNo ratings yet
- Genitive Case Evidence T3Document2 pagesGenitive Case Evidence T3Juan Jose Arcila AlvarezNo ratings yet
- Tony Wagner - 7 SkillsDocument1 pageTony Wagner - 7 SkillsUceda Institute, School of OrlandoNo ratings yet
- Über Den UrkoranDocument5 pagesÜber Den UrkoransamirNo ratings yet
- Answer The Proust QuestionnaireDocument5 pagesAnswer The Proust QuestionnaireYaqing QiNo ratings yet
- CONDITIONALS - TYPE 0+1-More ExercisesDocument29 pagesCONDITIONALS - TYPE 0+1-More ExercisesTú Bí100% (1)
- The Effects of Pulsed Microwaves and Extra Low Frequency Electromagnetic Waves On Human BrainsDocument3 pagesThe Effects of Pulsed Microwaves and Extra Low Frequency Electromagnetic Waves On Human BrainsvalorecoragemNo ratings yet
- Sessions 2 and 3 - Equity Valuation - in Session - Section EDocument88 pagesSessions 2 and 3 - Equity Valuation - in Session - Section EAnurag JainNo ratings yet
- BIO 22 MODULE 1 - Chemical Basis of LifeDocument14 pagesBIO 22 MODULE 1 - Chemical Basis of LifeBryan DGNo ratings yet
- ChatGPT Lords PrayerDocument12 pagesChatGPT Lords PrayerLouis MelgarejoNo ratings yet
- Kmpfe Sedlmeier RenkewitzDocument27 pagesKmpfe Sedlmeier RenkewitzAntonio Mauricio MorenoNo ratings yet
- Some Temporal Parameters of NoDocument123 pagesSome Temporal Parameters of NoPablo StuartNo ratings yet
- Reparando Boot ServerDocument6 pagesReparando Boot ServerErlon TroianoNo ratings yet
- Contesting Immigration Policy in Court: More InformationDocument226 pagesContesting Immigration Policy in Court: More InformationFabio A Marulanda VNo ratings yet
- Asd and SchizophreniaDocument8 pagesAsd and SchizophreniaCarregan AlvarezNo ratings yet
- Term1 GR9 Im P6Document7 pagesTerm1 GR9 Im P6hitarth shahNo ratings yet
- Computer Network Lesson Plan - UpdatedDocument2 pagesComputer Network Lesson Plan - UpdatedAmit Prakash SenNo ratings yet
- Virginia Standards of Learning ObjectiveDocument7 pagesVirginia Standards of Learning ObjectiveHoney Grace CaballesNo ratings yet
- Letter of Justice Renato S PDFDocument2 pagesLetter of Justice Renato S PDFROSE CAMILLE O DE ASISNo ratings yet
- Soc 206 Course Outline January 2024Document5 pagesSoc 206 Course Outline January 2024kotisekhan10No ratings yet
- Stairway To HeavenDocument17 pagesStairway To HeavenFrank gNo ratings yet
- Common Objections at TrialDocument2 pagesCommon Objections at TrialColeen Navarro-RasmussenNo ratings yet
- ISA Assignment December 2012 - Final PDFDocument4 pagesISA Assignment December 2012 - Final PDFiakujiNo ratings yet
- One Way Anova YOVIDocument3 pagesOne Way Anova YOVIYoviNo ratings yet
- Assignment 4Document10 pagesAssignment 4api-584057836No ratings yet



























































































Download as pdf or txt
You might also like
- Dark Demon - Christine FeehanDocument4 pagesDark Demon - Christine Feehantheresa1970No ratings yet
- STAT2011 2017 Exam Formulae PDFDocument3 pagesSTAT2011 2017 Exam Formulae PDFeccentricftw4No ratings yet
- SMA 2231 Probability and Statistics IIIDocument89 pagesSMA 2231 Probability and Statistics III001亗PRÍËšT亗No ratings yet
- StatIdea Slides 2Document55 pagesStatIdea Slides 2xinmiao wangNo ratings yet
- StatIdea Slides 4Document97 pagesStatIdea Slides 4xinmiao wangNo ratings yet
- Cheat SheetDocument2 pagesCheat SheetVarun NagpalNo ratings yet
- Unit 4: PTSP Unit Iv Questions & AnswersDocument10 pagesUnit 4: PTSP Unit Iv Questions & AnswerssrinivasNo ratings yet
- Two Dimensional Random VariableDocument4 pagesTwo Dimensional Random VariableRajaRaman.GNo ratings yet
- Chapter 3Document38 pagesChapter 3Dina AssefaNo ratings yet
- 8mmpjoint AnnotatedDocument25 pages8mmpjoint AnnotatedAntal TóthNo ratings yet
- Lect6 PDFDocument11 pagesLect6 PDFMarco CocchiNo ratings yet
- Slides 2 PDFDocument110 pagesSlides 2 PDFMansoor SaleemNo ratings yet
- P8-Properties of DistributionsDocument12 pagesP8-Properties of Distributionsching chauNo ratings yet
- 1 Probability Density Functions (PDF) : PropertiesDocument6 pages1 Probability Density Functions (PDF) : PropertiesFariza MakhayNo ratings yet
- MCMC: Gibbs Sampling: D K k1 k+1 DDocument7 pagesMCMC: Gibbs Sampling: D K k1 k+1 DDevendraReddyPoreddyNo ratings yet
- Probability Theory - Formula SheetDocument13 pagesProbability Theory - Formula SheettommielombartsNo ratings yet
- Functions of Random VariablesDocument13 pagesFunctions of Random Variablescharlotte.chua03No ratings yet
- Chapter 8Document52 pagesChapter 8islamNo ratings yet
- Functions of Random Variables PDFDocument15 pagesFunctions of Random Variables PDFVatan JhaNo ratings yet
- Chapter 0Document13 pagesChapter 0nargizireNo ratings yet
- 1 What Is A Random Variable (R.V.) ?Document6 pages1 What Is A Random Variable (R.V.) ?Eric VonFreemanNo ratings yet
- Joint Random Variables 1Document11 pagesJoint Random Variables 1Letsogile BaloiNo ratings yet
- Statistics 116 - Fall 2004 Theory of Probability Practice Final # 2 - SolutionsDocument7 pagesStatistics 116 - Fall 2004 Theory of Probability Practice Final # 2 - SolutionsKrishna Chaitanya SrikantaNo ratings yet
- Lecture 2Document43 pagesLecture 2pamelasedimoNo ratings yet
- Lecture 2Document27 pagesLecture 2aman workinehNo ratings yet
- Lecture #11: Distributions With Random ParametersDocument3 pagesLecture #11: Distributions With Random ParametersmohamedNo ratings yet
- Final For MultivariateDocument73 pagesFinal For MultivariateAishwarya RamNo ratings yet
- Notes MTH S 504 (Lecture-02-03 Notes)Document32 pagesNotes MTH S 504 (Lecture-02-03 Notes)Priyanshu GuptaNo ratings yet
- Homework 3 SolutionsDocument6 pagesHomework 3 SolutionsislayerNo ratings yet
- Tutorial Sheet 2Document3 pagesTutorial Sheet 2Psycho MindNo ratings yet
- UW MATH-STAT395 Bivariate-Distributions PDFDocument17 pagesUW MATH-STAT395 Bivariate-Distributions PDFPraney handaNo ratings yet
- Conditional Expectation For Discrete Random Variables: AgendaDocument5 pagesConditional Expectation For Discrete Random Variables: Agendazakir abbasNo ratings yet
- S.Y.B.Sc. Mathematics (MTH - 211) Question BankDocument14 pagesS.Y.B.Sc. Mathematics (MTH - 211) Question BankAbrar MalikNo ratings yet
- My Notes For Discrete and Continuous Distributions 987654Document28 pagesMy Notes For Discrete and Continuous Distributions 987654Shah FahadNo ratings yet
- HW6Document4 pagesHW6Pallavi RaiturkarNo ratings yet
- Problems On Two Dimensional Random VariableDocument15 pagesProblems On Two Dimensional Random VariableBRAHMA REDDY AAKUMAIIA100% (1)
- Stat276 Chapter 6Document9 pagesStat276 Chapter 6Onetwothree Tube100% (2)
- Generalized Linear Models: FX Axb C DX Axb C DXDocument11 pagesGeneralized Linear Models: FX Axb C DX Axb C DXAishat OmotolaNo ratings yet
- M5A42 Applied Stochastic Processes Problem Sheet 1 Solutions Term 1 2010-2011Document8 pagesM5A42 Applied Stochastic Processes Problem Sheet 1 Solutions Term 1 2010-2011paradoxNo ratings yet
- G (X) F (X, Y) : Marginal Distributions Definition 5Document13 pagesG (X) F (X, Y) : Marginal Distributions Definition 5Kimondo KingNo ratings yet
- Prob ReviewDocument19 pagesProb ReviewSiva Kumar GaniNo ratings yet
- E20214 Math Econ 07 Concave Convex Functions Convex Sets Homogeneous FunctionsDocument11 pagesE20214 Math Econ 07 Concave Convex Functions Convex Sets Homogeneous FunctionsJohn ChanNo ratings yet
- HW 2 SolutionDocument7 pagesHW 2 SolutionAnonymous 9qJCv5mC0No ratings yet
- Sma 2201Document35 pagesSma 2201Andrew MutungaNo ratings yet
- Assignment 6 Solutions IIIDocument2 pagesAssignment 6 Solutions IIIindianpinkNo ratings yet
- Joint Distributions: He ShuangchiDocument36 pagesJoint Distributions: He ShuangchiZhengYang ChinNo ratings yet
- Portugaliae Mathematica Vol. 58 Fasc. 2 - 2001 Nova S Erie: Presented by J.P. DiasDocument20 pagesPortugaliae Mathematica Vol. 58 Fasc. 2 - 2001 Nova S Erie: Presented by J.P. DiasVayo SonyNo ratings yet
- Differential Equations 2Document2 pagesDifferential Equations 2Prince WilliamNo ratings yet
- Joint Probability FunctionsDocument7 pagesJoint Probability FunctionsBran RelieveNo ratings yet
- DX Dy y X F W: IndependentDocument13 pagesDX Dy y X F W: IndependentdNo ratings yet
- Simple Linear Regression.: 29.1 Method of Least SquaresDocument4 pagesSimple Linear Regression.: 29.1 Method of Least SquaresDebashis GuptaNo ratings yet
- DSC6132: Probability and Statistical Modelling: Lecture 4: Multivariate Random VariablesDocument55 pagesDSC6132: Probability and Statistical Modelling: Lecture 4: Multivariate Random VariablesJOHNNo ratings yet
- Assignment1 SolDocument4 pagesAssignment1 SolVetreivel KNo ratings yet
- 1.probability Random Variables and Stochastic Processes Athanasios Papoulis S. Unnikrishna Pillai 1 300 181 210Document30 pages1.probability Random Variables and Stochastic Processes Athanasios Papoulis S. Unnikrishna Pillai 1 300 181 210AlvaroNo ratings yet
- Tutorial 5Document9 pagesTutorial 5RajMohanNo ratings yet
- Joint Density Function: - , 0 ,), ( y X y X e y X FDocument4 pagesJoint Density Function: - , 0 ,), ( y X y X e y X FRamuroshini GNo ratings yet
- Pair of RVsDocument20 pagesPair of RVsHải Vũ TrầnNo ratings yet
- Differential EquationsDocument3 pagesDifferential Equationsme21b002No ratings yet
- Probability: Problem Set 4 - SolutionsDocument4 pagesProbability: Problem Set 4 - SolutionsMary RomeroNo ratings yet
- Unit II - SjitDocument32 pagesUnit II - SjitShreyaNo ratings yet
- StatIdea Slides 2Document55 pagesStatIdea Slides 2xinmiao wangNo ratings yet
- StatIdea Slides 4Document97 pagesStatIdea Slides 4xinmiao wangNo ratings yet
- StatIdea Slides 3Document86 pagesStatIdea Slides 3xinmiao wangNo ratings yet
- StatIdea Slides 1Document53 pagesStatIdea Slides 1xinmiao wangNo ratings yet
- Guzavicius 2014 - Behavioural Finance - Corporate Social Responsibility ApproachDocument6 pagesGuzavicius 2014 - Behavioural Finance - Corporate Social Responsibility Approachxinmiao wangNo ratings yet
- University of Cebu - Main Campus College of Teacher Education Sanciangko Street, Cebu City SECOND SEMESTER 2020-2021 TC Ec 322 - Enhancement Course 2Document4 pagesUniversity of Cebu - Main Campus College of Teacher Education Sanciangko Street, Cebu City SECOND SEMESTER 2020-2021 TC Ec 322 - Enhancement Course 2FatimaNo ratings yet
- Towards Being A HumanDocument53 pagesTowards Being A HumanlarenNo ratings yet
- Research ProposalDocument19 pagesResearch ProposalNkk Khn100% (1)
- Wildlife CurriculumDocument70 pagesWildlife Curriculumapi-240926941100% (1)
- Stage 1 Name of The Students:: English IiiDocument6 pagesStage 1 Name of The Students:: English IiiRussell Najera RejonNo ratings yet
- Genitive Case Evidence T3Document2 pagesGenitive Case Evidence T3Juan Jose Arcila AlvarezNo ratings yet
- Tony Wagner - 7 SkillsDocument1 pageTony Wagner - 7 SkillsUceda Institute, School of OrlandoNo ratings yet
- Über Den UrkoranDocument5 pagesÜber Den UrkoransamirNo ratings yet
- Answer The Proust QuestionnaireDocument5 pagesAnswer The Proust QuestionnaireYaqing QiNo ratings yet
- CONDITIONALS - TYPE 0+1-More ExercisesDocument29 pagesCONDITIONALS - TYPE 0+1-More ExercisesTú Bí100% (1)
- The Effects of Pulsed Microwaves and Extra Low Frequency Electromagnetic Waves On Human BrainsDocument3 pagesThe Effects of Pulsed Microwaves and Extra Low Frequency Electromagnetic Waves On Human BrainsvalorecoragemNo ratings yet
- Sessions 2 and 3 - Equity Valuation - in Session - Section EDocument88 pagesSessions 2 and 3 - Equity Valuation - in Session - Section EAnurag JainNo ratings yet
- BIO 22 MODULE 1 - Chemical Basis of LifeDocument14 pagesBIO 22 MODULE 1 - Chemical Basis of LifeBryan DGNo ratings yet
- ChatGPT Lords PrayerDocument12 pagesChatGPT Lords PrayerLouis MelgarejoNo ratings yet
- Kmpfe Sedlmeier RenkewitzDocument27 pagesKmpfe Sedlmeier RenkewitzAntonio Mauricio MorenoNo ratings yet
- Some Temporal Parameters of NoDocument123 pagesSome Temporal Parameters of NoPablo StuartNo ratings yet
- Reparando Boot ServerDocument6 pagesReparando Boot ServerErlon TroianoNo ratings yet
- Contesting Immigration Policy in Court: More InformationDocument226 pagesContesting Immigration Policy in Court: More InformationFabio A Marulanda VNo ratings yet
- Asd and SchizophreniaDocument8 pagesAsd and SchizophreniaCarregan AlvarezNo ratings yet
- Term1 GR9 Im P6Document7 pagesTerm1 GR9 Im P6hitarth shahNo ratings yet
- Computer Network Lesson Plan - UpdatedDocument2 pagesComputer Network Lesson Plan - UpdatedAmit Prakash SenNo ratings yet
- Virginia Standards of Learning ObjectiveDocument7 pagesVirginia Standards of Learning ObjectiveHoney Grace CaballesNo ratings yet
- Letter of Justice Renato S PDFDocument2 pagesLetter of Justice Renato S PDFROSE CAMILLE O DE ASISNo ratings yet
- Soc 206 Course Outline January 2024Document5 pagesSoc 206 Course Outline January 2024kotisekhan10No ratings yet
- Stairway To HeavenDocument17 pagesStairway To HeavenFrank gNo ratings yet
- Common Objections at TrialDocument2 pagesCommon Objections at TrialColeen Navarro-RasmussenNo ratings yet
- ISA Assignment December 2012 - Final PDFDocument4 pagesISA Assignment December 2012 - Final PDFiakujiNo ratings yet
- One Way Anova YOVIDocument3 pagesOne Way Anova YOVIYoviNo ratings yet
- Assignment 4Document10 pagesAssignment 4api-584057836No ratings yet