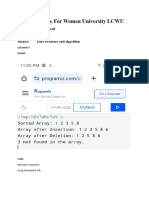
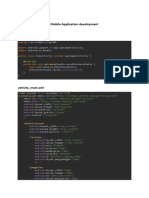
Download as txt, pdf, or txt
You might also like
- 0x16. C - Simple ShellDocument53 pages0x16. C - Simple ShellBenard Bett100% (3)
- PROJECT REPORT (Singly Linked List)Document40 pagesPROJECT REPORT (Singly Linked List)KISHAN KUMAR100% (1)
- Com 124 PracticalDocument25 pagesCom 124 Practicalraheemahmad276No ratings yet
- 25 Array Problems With SolutionsDocument35 pages25 Array Problems With SolutionsRajas PatilNo ratings yet
- A Report About The UnorderedDocument9 pagesA Report About The UnorderedNguyễn Chí TàiNo ratings yet
- Standard Template Library: 1. VectorDocument21 pagesStandard Template Library: 1. VectorJAI SINGHALNo ratings yet
- Rauf Khann C M M FileDocument12 pagesRauf Khann C M M FileAbdul rauf KhanNo ratings yet
- C++ Chapter 6Document5 pagesC++ Chapter 6Ajwa AliNo ratings yet
- int Flag 0 : //linear SearchDocument2 pagesint Flag 0 : //linear SearchAzeem AnsariNo ratings yet
- ARRAYSDocument12 pagesARRAYSavoveNo ratings yet
- Greedy XMDocument11 pagesGreedy XMHugu JujuNo ratings yet
- Adt LabDocument55 pagesAdt LabBhuvaneshNo ratings yet
- C++ STLDocument12 pagesC++ STLChandrahas ReddyNo ratings yet
- Lec20 24 ArraysDocument26 pagesLec20 24 Arraystapendrakumarakodiya.201me359No ratings yet
- Module 4 ArrayDocument14 pagesModule 4 Arrayfacebookdiwakar0No ratings yet
- 14 SortingDocument6 pages14 SortingAmoga LekshmiNo ratings yet
- List of Programs: Course: Design and Analysis of Algorithms Course Id: MCA202Document55 pagesList of Programs: Course: Design and Analysis of Algorithms Course Id: MCA202Rohit KumarNo ratings yet
- Array ProgramsDocument4 pagesArray ProgramssukeerthNo ratings yet
- Assignment 4 FA20 EEE 020Document17 pagesAssignment 4 FA20 EEE 020game zone CPFNo ratings yet
- Intermediate Level C ProgrammingDocument74 pagesIntermediate Level C ProgrammingSARATH KUMAAR J SEC 2020No ratings yet
- 14S Section SolutionDocument6 pages14S Section SolutionKhatia IvanovaNo ratings yet
- Data Structure & MRC AlgorithmsDocument57 pagesData Structure & MRC AlgorithmsSenthilVel PressNo ratings yet
- DATA STRUCTURES Practical FILEDocument85 pagesDATA STRUCTURES Practical FILEKunal MathurNo ratings yet
- Util HammerDocument47 pagesUtil Hammerox5tqgNo ratings yet
- Design and Analysis of Algorithms Lab File: ND THDocument93 pagesDesign and Analysis of Algorithms Lab File: ND THAbhishek KesharvaniNo ratings yet
- OODP WEEK 13 and 14Document11 pagesOODP WEEK 13 and 14VIPUL MANOJ KUMAR (RA2111003010646)No ratings yet
- ListDocument5 pagesListWasiNo ratings yet
- Implementation of Quick Sort and Merge SortDocument24 pagesImplementation of Quick Sort and Merge Sorthalfblood8400No ratings yet
- 10 ProgramsDocument21 pages10 ProgramsAakash KansalNo ratings yet
- Arrays C Example ProgramsDocument11 pagesArrays C Example ProgramsV. Ganesh KarthikeyanNo ratings yet
- Data Structure PracticalsDocument29 pagesData Structure PracticalsDevan Thakur100% (2)
- DaafileDocument40 pagesDaafileSanehNo ratings yet
- 432 - Pract6-8 - Div ADocument21 pages432 - Pract6-8 - Div AKajal GoudNo ratings yet
- Mahedi 4.1 4.2Document7 pagesMahedi 4.1 4.2Mahedi HassanNo ratings yet
- Presentation: Sorting Algorithms (Heap, Shell, Radix, Bucket)Document36 pagesPresentation: Sorting Algorithms (Heap, Shell, Radix, Bucket)Bilal RehmanNo ratings yet
- Lab Task 4Document4 pagesLab Task 4MinahilNo ratings yet
- Theory Paper: Arid Agriculture University, RawalpindiDocument14 pagesTheory Paper: Arid Agriculture University, RawalpindiUmair KhanNo ratings yet
- AdaspamDocument15 pagesAdaspampoori.2819.hapoNo ratings yet
- Lab Assignment 02Document9 pagesLab Assignment 02Vaibhav BhagwatNo ratings yet
- LAB ManualDocument4 pagesLAB ManualSadia FatimaNo ratings yet
- Mobile Application Development OutputDocument30 pagesMobile Application Development OutputKarthik BhargavNo ratings yet
- 051 Garvit GargDocument9 pages051 Garvit GargGarvit GargNo ratings yet
- OopDocument9 pagesOopMohit MalghadeNo ratings yet
- Lab DsaDocument4 pagesLab DsaSafaruzzaman ShovoNo ratings yet
- Design and Analysis of Algorithm (Lab)Document27 pagesDesign and Analysis of Algorithm (Lab)Vinay mauryaNo ratings yet
- SDA Lab 6Document19 pagesSDA Lab 6alibabaoleolaNo ratings yet
- Oop Lab 2Document16 pagesOop Lab 2TalhaNo ratings yet
- ADS Lab IDocument78 pagesADS Lab Itemp tempNo ratings yet
- DownloadfileDocument97 pagesDownloadfileMAHENDRA ZALANo ratings yet
- Sad Lab PracticalsDocument26 pagesSad Lab PracticalsykjewariaNo ratings yet
- Binary Search TreeDocument2 pagesBinary Search TreeChanNo ratings yet
- Data Structure and Analysis Algorithm Lab ManualDocument6 pagesData Structure and Analysis Algorithm Lab Manualouterbank007No ratings yet
- Jay DsDocument41 pagesJay Dsjohn wickNo ratings yet
- XII CS 9 - 10-Data StructureDocument22 pagesXII CS 9 - 10-Data StructureSrirama LakshmiNo ratings yet
- Document 1Document9 pagesDocument 1mahnoorzahiid09No ratings yet
- ADA Lab ManualDocument28 pagesADA Lab Manualharshkaithwas11No ratings yet
- 20CS3L3 Data Structures Laboratory 2.Document85 pages20CS3L3 Data Structures Laboratory 2.Prasanth TNo ratings yet
- Major AssignDocument26 pagesMajor Assign3wpaoNo ratings yet
- Write A C Program For Calculate Area of CircleDocument46 pagesWrite A C Program For Calculate Area of CirclePruthviraj ThakurNo ratings yet
- Operations On Arrays in DSDocument15 pagesOperations On Arrays in DSZEESHAN KHAN NIAZINo ratings yet
- ADA Notes-NEP 2023-1Document17 pagesADA Notes-NEP 2023-1Mohammad NoamaanNo ratings yet
- Data Structures & Algorithm: (CL210) Laboratory ManualDocument4 pagesData Structures & Algorithm: (CL210) Laboratory ManualShahmeer Ali MirzaNo ratings yet
- Chapter - 10: Self Referential Structures and Linked ListsDocument5 pagesChapter - 10: Self Referential Structures and Linked ListsNatnail getachewNo ratings yet
- Bic Easy HardDocument30 pagesBic Easy Hardmaria10018012No ratings yet
- Mid Point CircleDocument14 pagesMid Point Circleejaz123456No ratings yet
- AstarDocument20 pagesAstarPetter PNo ratings yet
- Algorithms To Perform Operations On Two Way Linked ListDocument4 pagesAlgorithms To Perform Operations On Two Way Linked ListtvsnNo ratings yet
- Data Structures Unit 1Document60 pagesData Structures Unit 1divyanshuvaishnav02No ratings yet
- Lecture 01 - IntroDocument20 pagesLecture 01 - Introbillie quantNo ratings yet
- 1.2 Kernel Data StructuresDocument10 pages1.2 Kernel Data StructuresVIJAYA PRABA PNo ratings yet
- New Microsoft Office Word DocumentDocument7 pagesNew Microsoft Office Word DocumentMangisetty SairamNo ratings yet
- Data Structures and Algorithms CS 232Document2 pagesData Structures and Algorithms CS 232Muhammad Arsalan KhanNo ratings yet
- L12 Application of CPMDocument13 pagesL12 Application of CPMPratik SamalNo ratings yet
- Difference Between DFS and BFS?Document14 pagesDifference Between DFS and BFS?ranadip dasNo ratings yet
- Lecture02a Optimization Annotated PDFDocument23 pagesLecture02a Optimization Annotated PDFNing YangNo ratings yet
- MPhasis Assessment - 3-2Document41 pagesMPhasis Assessment - 3-2Pavan ChNo ratings yet
- cmsc420 2020 08 HandoutsDocument53 pagescmsc420 2020 08 HandoutsAnthony-Dimitri ANo ratings yet
- Simplex Method (Minimization Example) : Object FunctionDocument6 pagesSimplex Method (Minimization Example) : Object FunctionDarya MemonNo ratings yet
- Chapter 1Document51 pagesChapter 1abdallah el chakikNo ratings yet
- Design and Analysis of Algorithm: Binary TreeDocument18 pagesDesign and Analysis of Algorithm: Binary TreeAminah AlhazmiNo ratings yet
- (Laurent Lessard) LP DualityDocument28 pages(Laurent Lessard) LP DualityLeonardo Gama AssumpçãoNo ratings yet
- Clustering in RDocument12 pagesClustering in RRenukaNo ratings yet
- Search Algorithms in AIDocument19 pagesSearch Algorithms in AIMuzamil YousafNo ratings yet
- 06 BinsearchDocument15 pages06 BinsearchRajdip PalNo ratings yet
- Search, Insert and Delete in A Sorted Array - GeeksforGeeksDocument9 pagesSearch, Insert and Delete in A Sorted Array - GeeksforGeeksAtul GargNo ratings yet
- 6.2 Sum of Subset, Hamiltonian CycleDocument9 pages6.2 Sum of Subset, Hamiltonian CycleSuraj kumarNo ratings yet
- Data Warehousing, OLAP, Data Mining Practice Questions SolutionsDocument4 pagesData Warehousing, OLAP, Data Mining Practice Questions SolutionsJohn GongNo ratings yet
- Deep LearningDocument189 pagesDeep LearningRajaNo ratings yet
- Assignment # 2 Due Date: 18 / 04 / 2021: Bahria University Department of Computer ScienceDocument2 pagesAssignment # 2 Due Date: 18 / 04 / 2021: Bahria University Department of Computer ScienceMaleeha MasoodNo ratings yet