
Idm Ass3
Idm Ass3
You might also like
- AdaBoostExample PDFDocument2 pagesAdaBoostExample PDFchongj2No ratings yet
- Etl Toolkit by Ralph Kimball PDFDocument2 pagesEtl Toolkit by Ralph Kimball PDFStephen0% (2)
- GRE - Quantitative Reasoning: QuickStudy Laminated Reference GuideFrom EverandGRE - Quantitative Reasoning: QuickStudy Laminated Reference GuideNo ratings yet
- Associate Traditional Web Developer Certification Detail Sheet - enDocument4 pagesAssociate Traditional Web Developer Certification Detail Sheet - enNavneet SharmaNo ratings yet
- Functional SpecificationDocument18 pagesFunctional SpecificationTom Marks0% (1)
- Oracle EBs Apps Blog of Mahfuz, OPM Consultant, Bangladesh - Reopen Closed PeriodDocument7 pagesOracle EBs Apps Blog of Mahfuz, OPM Consultant, Bangladesh - Reopen Closed PeriodNgọc Hoàng Trần100% (1)
- Idm Assignment 3 22735Document8 pagesIdm Assignment 3 22735Hamza FaisalNo ratings yet
- Definitions: Convergent and Divergent Series: S A A A ADocument4 pagesDefinitions: Convergent and Divergent Series: S A A A ARajeev RaiNo ratings yet
- % Creates A New Competitive Learning Neural Network % Stability Versus Clasticity Dilema % Randomise The Weights To Midvalue of Whole Data-RangeDocument3 pages% Creates A New Competitive Learning Neural Network % Stability Versus Clasticity Dilema % Randomise The Weights To Midvalue of Whole Data-Range510618083 ABHIJNANMAITINo ratings yet
- Solution Manual For Computer Algorithms Introduction To Design and Analysis 3 e 3rd Edition 0201612445Document38 pagesSolution Manual For Computer Algorithms Introduction To Design and Analysis 3 e 3rd Edition 0201612445guadaluperomerojz6s100% (15)
- Indian Institute of Science, Bangalore: Letter Image Recognition Using Neural Network Pattern RecognitionDocument6 pagesIndian Institute of Science, Bangalore: Letter Image Recognition Using Neural Network Pattern RecognitionArka ChakrabortyNo ratings yet
- ELEN 30104 Polyphase Induction MotorDocument20 pagesELEN 30104 Polyphase Induction MotorBu DakNo ratings yet
- Etapi 1Document5 pagesEtapi 1tinashe murwiraNo ratings yet
- DWMDocument9 pagesDWMmanasi sawantNo ratings yet
- Design and Analysis of Algorithms Loop Correctness: Ade Azurat - Fasilkom UI March 10, 2011Document8 pagesDesign and Analysis of Algorithms Loop Correctness: Ade Azurat - Fasilkom UI March 10, 2011IisAfriyantiNo ratings yet
- Course: Controls and System: Instructor: Raheel AhmedDocument4 pagesCourse: Controls and System: Instructor: Raheel AhmedFocus On ConceptsNo ratings yet
- Tema5 Teoria-2830Document57 pagesTema5 Teoria-2830Luis Alejandro Sanchez SanchezNo ratings yet
- Lecture 18 K Means ClusteringDocument77 pagesLecture 18 K Means ClusteringFasih UllahNo ratings yet
- HWK4 - CorrectversionDocument6 pagesHWK4 - Correctversionaakelley3No ratings yet
- I. Objective:: The Common Emitter AmplifierDocument11 pagesI. Objective:: The Common Emitter AmplifierJohn Joshua MiclatNo ratings yet
- CS174: Note12Document5 pagesCS174: Note12juggleninjaNo ratings yet
- K Mean ClusteringDocument24 pagesK Mean ClusteringdiscodancerhasanNo ratings yet
- RecorDocument6 pagesRecorHariharan.kNo ratings yet
- Sign Test & Wilcoxon Tests: Concept, Procedures and ExamplesDocument31 pagesSign Test & Wilcoxon Tests: Concept, Procedures and ExamplesmengleeNo ratings yet
- Summary and Discussion Of: "Stability Selection"Document7 pagesSummary and Discussion Of: "Stability Selection"GokuNo ratings yet
- Chapter 2 Roots of EquationDocument21 pagesChapter 2 Roots of EquationShyn ClavecillasNo ratings yet
- CS6011: Kernel Methods For Pattern Analysis: Submitted byDocument26 pagesCS6011: Kernel Methods For Pattern Analysis: Submitted byPawan GoyalNo ratings yet
- Lecture 8 - Counting - Updated PDFDocument35 pagesLecture 8 - Counting - Updated PDFMigi AlucradNo ratings yet
- CL Chapter 03 Solutions 5th Ed - EQUATIONS - UPDATED PDFDocument48 pagesCL Chapter 03 Solutions 5th Ed - EQUATIONS - UPDATED PDFTom WeustinkNo ratings yet
- Assignment6 SIE431Document2 pagesAssignment6 SIE431DEBORANo ratings yet
- 2020-Solved PYQDocument6 pages2020-Solved PYQMy PoolNo ratings yet
- Introduction To Neural NetworkDocument20 pagesIntroduction To Neural NetworkSal SaadNo ratings yet
- Fee LW4Document6 pagesFee LW4Артур КултышевNo ratings yet
- Machine LearningDocument56 pagesMachine LearningMani Vrs100% (3)
- ECE 463/514 - Midterm Solution: InstructorDocument10 pagesECE 463/514 - Midterm Solution: InstructorBrian PentonNo ratings yet
- W4-D3 Test and TaskDocument3 pagesW4-D3 Test and TaskJoy Kiruba PNo ratings yet
- Chapter3 PDFDocument25 pagesChapter3 PDFNourheneMbarekNo ratings yet
- 24-Differnce of Proportions-23-03-2024Document20 pages24-Differnce of Proportions-23-03-2024nchivaNo ratings yet
- 6.6 Solving The Equation of State For Z: Example S6.1 Peng-Robinson Solution by Hand CalculationDocument2 pages6.6 Solving The Equation of State For Z: Example S6.1 Peng-Robinson Solution by Hand CalculationAbd Elrahman HamdyNo ratings yet
- Statistical Analysis and Applications SCC234 - Sheet 3 - Model AnswerDocument12 pagesStatistical Analysis and Applications SCC234 - Sheet 3 - Model AnswerAndrew AdelNo ratings yet
- Abstract Algebra: Dyshi@cs - Ecnu.edu - CNDocument30 pagesAbstract Algebra: Dyshi@cs - Ecnu.edu - CNyu yuanNo ratings yet
- 2007 02 01b Janecek PerceptronDocument37 pages2007 02 01b Janecek PerceptronRadenNo ratings yet
- K-Mean Algo. On Iris Data Set - 15129145 PDFDocument7 pagesK-Mean Algo. On Iris Data Set - 15129145 PDFMohammad Waqas Moin SheikhNo ratings yet
- Control System Design - MidtermDocument6 pagesControl System Design - MidtermsameertardaNo ratings yet
- ClusteringDocument36 pagesClusteringKapildev KumarNo ratings yet
- Clustering Analysis: What Is Cluster Analysis?Document5 pagesClustering Analysis: What Is Cluster Analysis?shyamaNo ratings yet
- 1.5 - Elementary Matrices and Finding Inverse of A Matrix-1Document14 pages1.5 - Elementary Matrices and Finding Inverse of A Matrix-1ABU MASROOR AHMEDNo ratings yet
- NUMERICAL ANALYSIS ProjectDocument13 pagesNUMERICAL ANALYSIS ProjectDanyal MataniNo ratings yet
- DA2 Machine Learning Lab: Name: Suprit Darshan Shrestha Reg - No: 19BCE2584Document8 pagesDA2 Machine Learning Lab: Name: Suprit Darshan Shrestha Reg - No: 19BCE2584Suprit D. ShresthaNo ratings yet
- Sematic Representation: Experiment - PyDocument4 pagesSematic Representation: Experiment - PyHuy Vo VanNo ratings yet
- Simple Linear Regression AnalysisDocument21 pagesSimple Linear Regression AnalysisEngr.bilalNo ratings yet
- Intro To PCADocument48 pagesIntro To PCAavant_ganjiNo ratings yet
- Linear RegressionDocument4 pagesLinear RegressionHemant GargNo ratings yet
- Run Information KNN RESULTSDocument55 pagesRun Information KNN RESULTSmarcelorochaNo ratings yet
- Simply Array SumDocument2 pagesSimply Array SumNayana S VNo ratings yet
- Elimination 2 NotesDocument4 pagesElimination 2 Notesapi-310102170No ratings yet
- Btad157 Supplementary DataDocument12 pagesBtad157 Supplementary DataSonam ChauhanNo ratings yet
- Maquinas Electricas EjerciciosDocument13 pagesMaquinas Electricas EjerciciosBrayan veraNo ratings yet
- Mth501 Quiz FNLTRM MRGD FileDocument471 pagesMth501 Quiz FNLTRM MRGD FileAli SaabNo ratings yet
- CSE209 Lab 5Document8 pagesCSE209 Lab 5MR HAQUE0% (1)
- Primality TestingDocument56 pagesPrimality TestingwhatthheckNo ratings yet
- Lab 12Document1 pageLab 12Hamza FaisalNo ratings yet
- Lab11 InheritenceDocument1 pageLab11 InheritenceHamza FaisalNo ratings yet
- Lab10 InheritenceDocument1 pageLab10 InheritenceHamza FaisalNo ratings yet
- Lab14 PolyDocument2 pagesLab14 PolyHamza FaisalNo ratings yet
- Idm Assignment 3 22735Document8 pagesIdm Assignment 3 22735Hamza FaisalNo ratings yet
- Laiba 22989 Assign04Document8 pagesLaiba 22989 Assign04Hamza FaisalNo ratings yet
- Doing Excellent Software Development-1Document29 pagesDoing Excellent Software Development-1Hamza FaisalNo ratings yet
- Quiz 3 Solution Cse309 Summer 2021. OnlineDocument1 pageQuiz 3 Solution Cse309 Summer 2021. OnlineHamza FaisalNo ratings yet
- Quiz 2 Solution Cse309 Summer 2021Document1 pageQuiz 2 Solution Cse309 Summer 2021Hamza FaisalNo ratings yet
- COMMON UI Mistakes-1Document30 pagesCOMMON UI Mistakes-1Hamza FaisalNo ratings yet
- IDM Assignment 2Document10 pagesIDM Assignment 2Hamza FaisalNo ratings yet
- Software Engineering NotesDocument18 pagesSoftware Engineering NotesHamza FaisalNo ratings yet
- DOM ManipulationDocument6 pagesDOM ManipulationHamza FaisalNo ratings yet
- Software Engineering NotesDocument18 pagesSoftware Engineering NotesHamza FaisalNo ratings yet
- Assignment 5Document2 pagesAssignment 5Hamza FaisalNo ratings yet
- My CoursesDocument10 pagesMy CoursesRak KusuNo ratings yet
- Business Analytics - ExcelDocument8 pagesBusiness Analytics - ExcelFERRY SIGNNo ratings yet
- Industrial Training Report On Python NewDocument33 pagesIndustrial Training Report On Python NewKondwaniNo ratings yet
- Class 12 Final NotesDocument111 pagesClass 12 Final NotesHerman PecassaNo ratings yet
- Visa Processing Information SystemDocument4 pagesVisa Processing Information SystemKpsmurugesan KpsmNo ratings yet
- 1 - PPT Module (20 Files Merged)Document714 pages1 - PPT Module (20 Files Merged)harshNo ratings yet
- Datasheet MX-OnE Manager Availability enDocument2 pagesDatasheet MX-OnE Manager Availability enTatiano BrolloNo ratings yet
- Quiz 002 - Attempt Review2 PDFDocument3 pagesQuiz 002 - Attempt Review2 PDFkatherine anne ortizNo ratings yet
- Brent Ozar LicensingDocument41 pagesBrent Ozar LicensingdesaesNo ratings yet
- FusionDocument3 pagesFusionHCIA 2020No ratings yet
- C# Coding Standards and Best Programming PracticesDocument58 pagesC# Coding Standards and Best Programming PracticesKiran PatilNo ratings yet
- 02 01 The Golden Rules of Spreadsheet DesignDocument14 pages02 01 The Golden Rules of Spreadsheet Designnattapol sararakNo ratings yet
- Syllabus-Power BI Training (Basic, Intermediate and Advanced Level)Document5 pagesSyllabus-Power BI Training (Basic, Intermediate and Advanced Level)nikitatayaNo ratings yet
- Change ManagementDocument138 pagesChange ManagementNaveen KumarNo ratings yet
- Internet of ThingsDocument13 pagesInternet of ThingsSai SathguruNo ratings yet
- Dbms Unit 10Document28 pagesDbms Unit 10Krish PatelNo ratings yet
- 03 Imperative PDFDocument27 pages03 Imperative PDFwaqar asgharNo ratings yet
- Introbook v4 enDocument145 pagesIntrobook v4 enGiuliano PertileNo ratings yet
- Baf4201 MohaDocument4 pagesBaf4201 MohaODUNDO JOEL OKWIRINo ratings yet
- Quality Assurance ChecklistDocument11 pagesQuality Assurance ChecklistGTS SS DRSCNo ratings yet
- Collect OS Linux and Windows LogsDocument13 pagesCollect OS Linux and Windows LogslocococineroNo ratings yet
- CLEO ReadMeoewufhewiugfDocument2 pagesCLEO ReadMeoewufhewiugfgsgsggsggNo ratings yet
- Employee Management System: Background StudyDocument71 pagesEmployee Management System: Background Studydeepak_143No ratings yet
- E Business e Cash e WalletDocument34 pagesE Business e Cash e WalletJayapal Hari100% (1)
- CIS Oracle Database 18c Benchmark v1.0.0Document260 pagesCIS Oracle Database 18c Benchmark v1.0.0pablovivasveNo ratings yet
- rdb1 ws0910 v2 2x3 PDFDocument14 pagesrdb1 ws0910 v2 2x3 PDFFarwaNo ratings yet












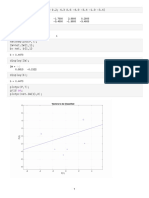


























































































Download as docx, pdf, or txt
You might also like
- AdaBoostExample PDFDocument2 pagesAdaBoostExample PDFchongj2No ratings yet
- Etl Toolkit by Ralph Kimball PDFDocument2 pagesEtl Toolkit by Ralph Kimball PDFStephen0% (2)
- GRE - Quantitative Reasoning: QuickStudy Laminated Reference GuideFrom EverandGRE - Quantitative Reasoning: QuickStudy Laminated Reference GuideNo ratings yet
- Associate Traditional Web Developer Certification Detail Sheet - enDocument4 pagesAssociate Traditional Web Developer Certification Detail Sheet - enNavneet SharmaNo ratings yet
- Functional SpecificationDocument18 pagesFunctional SpecificationTom Marks0% (1)
- Oracle EBs Apps Blog of Mahfuz, OPM Consultant, Bangladesh - Reopen Closed PeriodDocument7 pagesOracle EBs Apps Blog of Mahfuz, OPM Consultant, Bangladesh - Reopen Closed PeriodNgọc Hoàng Trần100% (1)
- Idm Assignment 3 22735Document8 pagesIdm Assignment 3 22735Hamza FaisalNo ratings yet
- Definitions: Convergent and Divergent Series: S A A A ADocument4 pagesDefinitions: Convergent and Divergent Series: S A A A ARajeev RaiNo ratings yet
- % Creates A New Competitive Learning Neural Network % Stability Versus Clasticity Dilema % Randomise The Weights To Midvalue of Whole Data-RangeDocument3 pages% Creates A New Competitive Learning Neural Network % Stability Versus Clasticity Dilema % Randomise The Weights To Midvalue of Whole Data-Range510618083 ABHIJNANMAITINo ratings yet
- Solution Manual For Computer Algorithms Introduction To Design and Analysis 3 e 3rd Edition 0201612445Document38 pagesSolution Manual For Computer Algorithms Introduction To Design and Analysis 3 e 3rd Edition 0201612445guadaluperomerojz6s100% (15)
- Indian Institute of Science, Bangalore: Letter Image Recognition Using Neural Network Pattern RecognitionDocument6 pagesIndian Institute of Science, Bangalore: Letter Image Recognition Using Neural Network Pattern RecognitionArka ChakrabortyNo ratings yet
- ELEN 30104 Polyphase Induction MotorDocument20 pagesELEN 30104 Polyphase Induction MotorBu DakNo ratings yet
- Etapi 1Document5 pagesEtapi 1tinashe murwiraNo ratings yet
- DWMDocument9 pagesDWMmanasi sawantNo ratings yet
- Design and Analysis of Algorithms Loop Correctness: Ade Azurat - Fasilkom UI March 10, 2011Document8 pagesDesign and Analysis of Algorithms Loop Correctness: Ade Azurat - Fasilkom UI March 10, 2011IisAfriyantiNo ratings yet
- Course: Controls and System: Instructor: Raheel AhmedDocument4 pagesCourse: Controls and System: Instructor: Raheel AhmedFocus On ConceptsNo ratings yet
- Tema5 Teoria-2830Document57 pagesTema5 Teoria-2830Luis Alejandro Sanchez SanchezNo ratings yet
- Lecture 18 K Means ClusteringDocument77 pagesLecture 18 K Means ClusteringFasih UllahNo ratings yet
- HWK4 - CorrectversionDocument6 pagesHWK4 - Correctversionaakelley3No ratings yet
- I. Objective:: The Common Emitter AmplifierDocument11 pagesI. Objective:: The Common Emitter AmplifierJohn Joshua MiclatNo ratings yet
- CS174: Note12Document5 pagesCS174: Note12juggleninjaNo ratings yet
- K Mean ClusteringDocument24 pagesK Mean ClusteringdiscodancerhasanNo ratings yet
- RecorDocument6 pagesRecorHariharan.kNo ratings yet
- Sign Test & Wilcoxon Tests: Concept, Procedures and ExamplesDocument31 pagesSign Test & Wilcoxon Tests: Concept, Procedures and ExamplesmengleeNo ratings yet
- Summary and Discussion Of: "Stability Selection"Document7 pagesSummary and Discussion Of: "Stability Selection"GokuNo ratings yet
- Chapter 2 Roots of EquationDocument21 pagesChapter 2 Roots of EquationShyn ClavecillasNo ratings yet
- CS6011: Kernel Methods For Pattern Analysis: Submitted byDocument26 pagesCS6011: Kernel Methods For Pattern Analysis: Submitted byPawan GoyalNo ratings yet
- Lecture 8 - Counting - Updated PDFDocument35 pagesLecture 8 - Counting - Updated PDFMigi AlucradNo ratings yet
- CL Chapter 03 Solutions 5th Ed - EQUATIONS - UPDATED PDFDocument48 pagesCL Chapter 03 Solutions 5th Ed - EQUATIONS - UPDATED PDFTom WeustinkNo ratings yet
- Assignment6 SIE431Document2 pagesAssignment6 SIE431DEBORANo ratings yet
- 2020-Solved PYQDocument6 pages2020-Solved PYQMy PoolNo ratings yet
- Introduction To Neural NetworkDocument20 pagesIntroduction To Neural NetworkSal SaadNo ratings yet
- Fee LW4Document6 pagesFee LW4Артур КултышевNo ratings yet
- Machine LearningDocument56 pagesMachine LearningMani Vrs100% (3)
- ECE 463/514 - Midterm Solution: InstructorDocument10 pagesECE 463/514 - Midterm Solution: InstructorBrian PentonNo ratings yet
- W4-D3 Test and TaskDocument3 pagesW4-D3 Test and TaskJoy Kiruba PNo ratings yet
- Chapter3 PDFDocument25 pagesChapter3 PDFNourheneMbarekNo ratings yet
- 24-Differnce of Proportions-23-03-2024Document20 pages24-Differnce of Proportions-23-03-2024nchivaNo ratings yet
- 6.6 Solving The Equation of State For Z: Example S6.1 Peng-Robinson Solution by Hand CalculationDocument2 pages6.6 Solving The Equation of State For Z: Example S6.1 Peng-Robinson Solution by Hand CalculationAbd Elrahman HamdyNo ratings yet
- Statistical Analysis and Applications SCC234 - Sheet 3 - Model AnswerDocument12 pagesStatistical Analysis and Applications SCC234 - Sheet 3 - Model AnswerAndrew AdelNo ratings yet
- Abstract Algebra: Dyshi@cs - Ecnu.edu - CNDocument30 pagesAbstract Algebra: Dyshi@cs - Ecnu.edu - CNyu yuanNo ratings yet
- 2007 02 01b Janecek PerceptronDocument37 pages2007 02 01b Janecek PerceptronRadenNo ratings yet
- K-Mean Algo. On Iris Data Set - 15129145 PDFDocument7 pagesK-Mean Algo. On Iris Data Set - 15129145 PDFMohammad Waqas Moin SheikhNo ratings yet
- Control System Design - MidtermDocument6 pagesControl System Design - MidtermsameertardaNo ratings yet
- ClusteringDocument36 pagesClusteringKapildev KumarNo ratings yet
- Clustering Analysis: What Is Cluster Analysis?Document5 pagesClustering Analysis: What Is Cluster Analysis?shyamaNo ratings yet
- 1.5 - Elementary Matrices and Finding Inverse of A Matrix-1Document14 pages1.5 - Elementary Matrices and Finding Inverse of A Matrix-1ABU MASROOR AHMEDNo ratings yet
- NUMERICAL ANALYSIS ProjectDocument13 pagesNUMERICAL ANALYSIS ProjectDanyal MataniNo ratings yet
- DA2 Machine Learning Lab: Name: Suprit Darshan Shrestha Reg - No: 19BCE2584Document8 pagesDA2 Machine Learning Lab: Name: Suprit Darshan Shrestha Reg - No: 19BCE2584Suprit D. ShresthaNo ratings yet
- Sematic Representation: Experiment - PyDocument4 pagesSematic Representation: Experiment - PyHuy Vo VanNo ratings yet
- Simple Linear Regression AnalysisDocument21 pagesSimple Linear Regression AnalysisEngr.bilalNo ratings yet
- Intro To PCADocument48 pagesIntro To PCAavant_ganjiNo ratings yet
- Linear RegressionDocument4 pagesLinear RegressionHemant GargNo ratings yet
- Run Information KNN RESULTSDocument55 pagesRun Information KNN RESULTSmarcelorochaNo ratings yet
- Simply Array SumDocument2 pagesSimply Array SumNayana S VNo ratings yet
- Elimination 2 NotesDocument4 pagesElimination 2 Notesapi-310102170No ratings yet
- Btad157 Supplementary DataDocument12 pagesBtad157 Supplementary DataSonam ChauhanNo ratings yet
- Maquinas Electricas EjerciciosDocument13 pagesMaquinas Electricas EjerciciosBrayan veraNo ratings yet
- Mth501 Quiz FNLTRM MRGD FileDocument471 pagesMth501 Quiz FNLTRM MRGD FileAli SaabNo ratings yet
- CSE209 Lab 5Document8 pagesCSE209 Lab 5MR HAQUE0% (1)
- Primality TestingDocument56 pagesPrimality TestingwhatthheckNo ratings yet
- Lab 12Document1 pageLab 12Hamza FaisalNo ratings yet
- Lab11 InheritenceDocument1 pageLab11 InheritenceHamza FaisalNo ratings yet
- Lab10 InheritenceDocument1 pageLab10 InheritenceHamza FaisalNo ratings yet
- Lab14 PolyDocument2 pagesLab14 PolyHamza FaisalNo ratings yet
- Idm Assignment 3 22735Document8 pagesIdm Assignment 3 22735Hamza FaisalNo ratings yet
- Laiba 22989 Assign04Document8 pagesLaiba 22989 Assign04Hamza FaisalNo ratings yet
- Doing Excellent Software Development-1Document29 pagesDoing Excellent Software Development-1Hamza FaisalNo ratings yet
- Quiz 3 Solution Cse309 Summer 2021. OnlineDocument1 pageQuiz 3 Solution Cse309 Summer 2021. OnlineHamza FaisalNo ratings yet
- Quiz 2 Solution Cse309 Summer 2021Document1 pageQuiz 2 Solution Cse309 Summer 2021Hamza FaisalNo ratings yet
- COMMON UI Mistakes-1Document30 pagesCOMMON UI Mistakes-1Hamza FaisalNo ratings yet
- IDM Assignment 2Document10 pagesIDM Assignment 2Hamza FaisalNo ratings yet
- Software Engineering NotesDocument18 pagesSoftware Engineering NotesHamza FaisalNo ratings yet
- DOM ManipulationDocument6 pagesDOM ManipulationHamza FaisalNo ratings yet
- Software Engineering NotesDocument18 pagesSoftware Engineering NotesHamza FaisalNo ratings yet
- Assignment 5Document2 pagesAssignment 5Hamza FaisalNo ratings yet
- My CoursesDocument10 pagesMy CoursesRak KusuNo ratings yet
- Business Analytics - ExcelDocument8 pagesBusiness Analytics - ExcelFERRY SIGNNo ratings yet
- Industrial Training Report On Python NewDocument33 pagesIndustrial Training Report On Python NewKondwaniNo ratings yet
- Class 12 Final NotesDocument111 pagesClass 12 Final NotesHerman PecassaNo ratings yet
- Visa Processing Information SystemDocument4 pagesVisa Processing Information SystemKpsmurugesan KpsmNo ratings yet
- 1 - PPT Module (20 Files Merged)Document714 pages1 - PPT Module (20 Files Merged)harshNo ratings yet
- Datasheet MX-OnE Manager Availability enDocument2 pagesDatasheet MX-OnE Manager Availability enTatiano BrolloNo ratings yet
- Quiz 002 - Attempt Review2 PDFDocument3 pagesQuiz 002 - Attempt Review2 PDFkatherine anne ortizNo ratings yet
- Brent Ozar LicensingDocument41 pagesBrent Ozar LicensingdesaesNo ratings yet
- FusionDocument3 pagesFusionHCIA 2020No ratings yet
- C# Coding Standards and Best Programming PracticesDocument58 pagesC# Coding Standards and Best Programming PracticesKiran PatilNo ratings yet
- 02 01 The Golden Rules of Spreadsheet DesignDocument14 pages02 01 The Golden Rules of Spreadsheet Designnattapol sararakNo ratings yet
- Syllabus-Power BI Training (Basic, Intermediate and Advanced Level)Document5 pagesSyllabus-Power BI Training (Basic, Intermediate and Advanced Level)nikitatayaNo ratings yet
- Change ManagementDocument138 pagesChange ManagementNaveen KumarNo ratings yet
- Internet of ThingsDocument13 pagesInternet of ThingsSai SathguruNo ratings yet
- Dbms Unit 10Document28 pagesDbms Unit 10Krish PatelNo ratings yet
- 03 Imperative PDFDocument27 pages03 Imperative PDFwaqar asgharNo ratings yet
- Introbook v4 enDocument145 pagesIntrobook v4 enGiuliano PertileNo ratings yet
- Baf4201 MohaDocument4 pagesBaf4201 MohaODUNDO JOEL OKWIRINo ratings yet
- Quality Assurance ChecklistDocument11 pagesQuality Assurance ChecklistGTS SS DRSCNo ratings yet
- Collect OS Linux and Windows LogsDocument13 pagesCollect OS Linux and Windows LogslocococineroNo ratings yet
- CLEO ReadMeoewufhewiugfDocument2 pagesCLEO ReadMeoewufhewiugfgsgsggsggNo ratings yet
- Employee Management System: Background StudyDocument71 pagesEmployee Management System: Background Studydeepak_143No ratings yet
- E Business e Cash e WalletDocument34 pagesE Business e Cash e WalletJayapal Hari100% (1)
- CIS Oracle Database 18c Benchmark v1.0.0Document260 pagesCIS Oracle Database 18c Benchmark v1.0.0pablovivasveNo ratings yet
- rdb1 ws0910 v2 2x3 PDFDocument14 pagesrdb1 ws0910 v2 2x3 PDFFarwaNo ratings yet