
SFA - Group 10 - Assignment
SFA - Group 10 - Assignment
You might also like
- HW7Document6 pagesHW7Clement Runtung100% (2)
- Problem-Solving and Data Analysis-Evaluating Statistical Claims - Observational Studies and ExperimentsDocument8 pagesProblem-Solving and Data Analysis-Evaluating Statistical Claims - Observational Studies and Experimentsttttvvv8No ratings yet
- MA in Political Economy - Handbook - 2016 (KCL)Document15 pagesMA in Political Economy - Handbook - 2016 (KCL)Hon Wai LaiNo ratings yet
- National Institute of Technology, Tiruchirappalli MBA Trimester Examination, Basic Data Analytic Marathon ExamDocument22 pagesNational Institute of Technology, Tiruchirappalli MBA Trimester Examination, Basic Data Analytic Marathon ExamArjun Jinumon PootharaNo ratings yet
- Group Number X - MACR - AssignmentDocument7 pagesGroup Number X - MACR - AssignmentRohitNo ratings yet
- Group 3 Glossier Case AnalysisDocument11 pagesGroup 3 Glossier Case AnalysisRohitNo ratings yet
- BdaDocument24 pagesBdaAbinNo ratings yet
- Credit-Scoring-CASEDocument29 pagesCredit-Scoring-CASEreach2ghoshNo ratings yet
- Super Bowl PredictionDocument34 pagesSuper Bowl PredictionAddy DamNo ratings yet
- Logistic RegressionDocument41 pagesLogistic RegressionMonica100% (1)
- D (I, J) R+s Q +R +S+TDocument5 pagesD (I, J) R+s Q +R +S+TNitish NehraNo ratings yet
- Corporate Risk EstimatesDocument21 pagesCorporate Risk EstimatesRahul sardanaNo ratings yet
- Smart PDFDocument6 pagesSmart PDFHardiyansahNo ratings yet
- Examples Correation and RegressionDocument29 pagesExamples Correation and RegressionMinahil FatimaNo ratings yet
- Knowledge Management Processes 5: Silvia Martelo-Landroguez and Gabriel Cepeda-CarriónDocument2 pagesKnowledge Management Processes 5: Silvia Martelo-Landroguez and Gabriel Cepeda-CarriónDani JaramilloNo ratings yet
- Session 1-Discriminant Analysis-1Document52 pagesSession 1-Discriminant Analysis-1devaki reddyNo ratings yet
- Assignment Module 1Document30 pagesAssignment Module 1Priyanka SindhwaniNo ratings yet
- Attribute Coeffs S.E. Wald Z P-ValueDocument8 pagesAttribute Coeffs S.E. Wald Z P-Valuesarthak mendirattaNo ratings yet
- Tablas de Distribucion de Probabilidad PDFDocument27 pagesTablas de Distribucion de Probabilidad PDFdanielNo ratings yet
- Assignment 8 6331 PDFDocument11 pagesAssignment 8 6331 PDFALIKNFNo ratings yet
- Lecture 3 Logistic RegressionDocument14 pagesLecture 3 Logistic Regressioniamboss086No ratings yet
- The SAS System The SAS System: The CORR Procedure The CORR ProcedureDocument1 pageThe SAS System The SAS System: The CORR Procedure The CORR ProcedureNakshtra DasNo ratings yet
- Newton Raphson Submission FileDocument9 pagesNewton Raphson Submission Fileshailesh upadhyayNo ratings yet
- Analytics Report: Gray Hunter and John Mcclintock Yamelle Gonzalez Dummy Variables APRIL 14, 2020Document4 pagesAnalytics Report: Gray Hunter and John Mcclintock Yamelle Gonzalez Dummy Variables APRIL 14, 2020api-529885888No ratings yet
- Computation of Multipliers: Specify The Survival Column, L (X), and The Cost of Care at Each AgeDocument7 pagesComputation of Multipliers: Specify The Survival Column, L (X), and The Cost of Care at Each AgeJay WhiteNo ratings yet
- Exam 1Document6 pagesExam 1Danien LopesNo ratings yet
- Econometric Analysis: DR Alka Chadha IIM TrichyDocument29 pagesEconometric Analysis: DR Alka Chadha IIM TrichyChintu KumarNo ratings yet
- Generate Unifrom DistributionDocument11 pagesGenerate Unifrom Distributionajaykum14No ratings yet
- Financial Management-1 Project ReportDocument6 pagesFinancial Management-1 Project ReportNakulesh VijayvargiyaNo ratings yet
- Mgt555 - Individual Assignment 2Document6 pagesMgt555 - Individual Assignment 22021230564100% (1)
- Primary Objective: A Study of The Shopping Behavior of Mobile Phone Users inDocument3 pagesPrimary Objective: A Study of The Shopping Behavior of Mobile Phone Users inIranshah MakerNo ratings yet
- Assignment 11 Team 4 Date 11/19/2018 Ananth Ramesh Qian Ciu Shikhar Goyal Tanish Gupta Vinay Sagar MudlapurDocument45 pagesAssignment 11 Team 4 Date 11/19/2018 Ananth Ramesh Qian Ciu Shikhar Goyal Tanish Gupta Vinay Sagar MudlapurAnanth RameshNo ratings yet
- Exercise 1Document9 pagesExercise 1Meryem LamhamdiNo ratings yet
- Askaria f1051151052 Modul UjiDocument27 pagesAskaria f1051151052 Modul UjiAskaria FahrezaNo ratings yet
- Capital Budgeting BSNLDocument10 pagesCapital Budgeting BSNLAşhwįnį GawasNo ratings yet
- Credit Risk Dataset AnalysisDocument7 pagesCredit Risk Dataset Analysisakothcathrine062No ratings yet
- Note 4Document18 pagesNote 4nuthan manideepNo ratings yet
- BUS270 Assignment 2Document28 pagesBUS270 Assignment 2Bharat KoiralaNo ratings yet
- The Bisection Algorithm: Either No Solutions or Multiple Solutions Between Left and Right BoundsDocument1 pageThe Bisection Algorithm: Either No Solutions or Multiple Solutions Between Left and Right BoundsAhmadMoaazNo ratings yet
- Ideality FactorDocument8 pagesIdeality FactorJeptha LalawmpuiaNo ratings yet
- Example Factor AnalysisDocument1 pageExample Factor AnalysisFCNo ratings yet
- Experimental CalculationsDocument5 pagesExperimental CalculationsmomenNo ratings yet
- Nama: Ersa Kusumawardani NPM: 0115103003/reg B2/C Mata Kuliah: Statistik Multivariat Tugas Eviews 1Document9 pagesNama: Ersa Kusumawardani NPM: 0115103003/reg B2/C Mata Kuliah: Statistik Multivariat Tugas Eviews 1ersa kusumawardaniNo ratings yet
- ODE 1st Order Ex1Document4 pagesODE 1st Order Ex1______.________No ratings yet
- Monserrat2D Activity6 AE9Document5 pagesMonserrat2D Activity6 AE9Jerome MonserratNo ratings yet
- Critical Analysis Of: Multiple Regression ModelDocument12 pagesCritical Analysis Of: Multiple Regression Modelsanket patilNo ratings yet
- Fogler Prob 6 14Document8 pagesFogler Prob 6 14Romero E MayrlaNo ratings yet
- REGRESSIONDocument2 pagesREGRESSIONUtkarsh VikramNo ratings yet
- Managerial Economics: Lecture 17 - Decision Making Under Risk Prof. Thiagu RanganathanDocument21 pagesManagerial Economics: Lecture 17 - Decision Making Under Risk Prof. Thiagu RanganathanAshishKushwahaNo ratings yet
- X EXP Serie Signo Serie Real Suma Error RelativoDocument8 pagesX EXP Serie Signo Serie Real Suma Error RelativoMargiori Supo PerezNo ratings yet
- Calculos Lab 3Document6 pagesCalculos Lab 3Esquivel Bocanegra Pablo HosmarNo ratings yet
- Structural Change in Developing Countries Has It Decreased Gender InequalityDocument12 pagesStructural Change in Developing Countries Has It Decreased Gender Inequalitylifetips6786No ratings yet
- I V Characterstics of PN Junction DiodeDocument10 pagesI V Characterstics of PN Junction Diodeمعاً إلى الجنةNo ratings yet
- Gaussian QuadratureDocument4 pagesGaussian Quadratureredeemer90No ratings yet
- Assignment 2 20L-2373 Abdul HaseebDocument12 pagesAssignment 2 20L-2373 Abdul Haseebsarwat abbasNo ratings yet
- 333 PDFDocument3 pages333 PDFMaicol Pulido RuizNo ratings yet
- X EXP Serie Signo Serie Real Suma Error RelativoDocument8 pagesX EXP Serie Signo Serie Real Suma Error RelativoMargiori Supo PerezNo ratings yet
- NR Report 1Document10 pagesNR Report 1shailesh upadhyayNo ratings yet
- Research MethodologyDocument6 pagesResearch MethodologyMANSHI RAINo ratings yet
- System Modelling and SimulationDocument19 pagesSystem Modelling and Simulationtve21ie060No ratings yet
- FR2202mock ExamDocument6 pagesFR2202mock ExamSunny LeNo ratings yet
- Probabilistic GradingDocument5 pagesProbabilistic GradingSeung Pyo SonNo ratings yet
- HW ExplanationDocument20 pagesHW ExplanationMysara MunneeNo ratings yet
- Statistical Analysis Using Microsoft ExcelDocument11 pagesStatistical Analysis Using Microsoft ExcelNithi AyyaluNo ratings yet
- Analyisis ResultsDocument11 pagesAnalyisis ResultsQasim ShahNo ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- Group 10 - HRM - Group AssignmentDocument16 pagesGroup 10 - HRM - Group AssignmentRohitNo ratings yet
- Group 6 - IBB - The Future AirportsDocument8 pagesGroup 6 - IBB - The Future AirportsRohitNo ratings yet
- CCDCV - D.light - Situation AnalysisDocument1 pageCCDCV - D.light - Situation AnalysisRohitNo ratings yet
- OD SimulationDocument1 pageOD SimulationRohitNo ratings yet
- Group 6 - IBB - Leveraging Blockchain in Land Registry - Real Estate SectorDocument9 pagesGroup 6 - IBB - Leveraging Blockchain in Land Registry - Real Estate SectorRohitNo ratings yet
- Rohit Satarke 2022EPGP042 LAB AssignmentDocument19 pagesRohit Satarke 2022EPGP042 LAB AssignmentRohitNo ratings yet
- 8) Multilevel AnalysisDocument41 pages8) Multilevel AnalysisMulusewNo ratings yet
- JL and Lucille CRD Stat2Document8 pagesJL and Lucille CRD Stat2Jevelyn Mendoza FarroNo ratings yet
- Laerd Statistics 2013Document3 pagesLaerd Statistics 2013Rene John Bulalaque Escal100% (1)
- Community Participation and Sustainable Management of Central Forest Reserve Research ProposalDocument46 pagesCommunity Participation and Sustainable Management of Central Forest Reserve Research ProposalKamira Sulait Kyepa75% (4)
- IIIDocument3 pagesIIIClarilyn TrivinoNo ratings yet
- Diskriminasi Aitem & Reliabilitas: Reliability StatisticsDocument10 pagesDiskriminasi Aitem & Reliabilitas: Reliability StatisticsDrizzle zleNo ratings yet
- Linear Discriminant AnalysisDocument33 pagesLinear Discriminant AnalysisNaman JainNo ratings yet
- Automation in Construction: R.S. Adhikari, O. Moselhi, A. BagchiDocument15 pagesAutomation in Construction: R.S. Adhikari, O. Moselhi, A. BagchisoujanaNo ratings yet
- Practical Research 1 Concept Mastery I. Multiple Choice: Choose The Letter of The Correct AnswerDocument3 pagesPractical Research 1 Concept Mastery I. Multiple Choice: Choose The Letter of The Correct AnswerSanta Dumlao0% (1)
- AStudyon Dataminingtechniquestoimprovestudentsperformancein Higher EducationDocument7 pagesAStudyon Dataminingtechniquestoimprovestudentsperformancein Higher Educationddol36899No ratings yet
- JMP Stat Graph GuideDocument1,068 pagesJMP Stat Graph Guidekfaulk1100% (4)
- Data Latihan AnovaDocument15 pagesData Latihan AnovaNuraini MeinaNo ratings yet
- EPM 1173 Day 6A-Unit 5-MSP-ResourcesDocument45 pagesEPM 1173 Day 6A-Unit 5-MSP-ResourcesRahul ChawlaNo ratings yet
- The Journal Oct-Dec 2018 PDFDocument104 pagesThe Journal Oct-Dec 2018 PDFDevi Varra Prasad TirunagariNo ratings yet
- DWBI Concepts AllDocument83 pagesDWBI Concepts Allnirmalph100% (3)
- Syllabus-MBAE 0046Document2 pagesSyllabus-MBAE 0046J SujathaNo ratings yet
- Bcom 25 04Document278 pagesBcom 25 04Abila RevathyNo ratings yet
- CH 10 TestDocument23 pagesCH 10 TestDaniel Hunks100% (1)
- Marek Gruszczy Ski - Financial Microeconometrics - A Research Methodology in Corporate Finance and Accounting (2020)Document228 pagesMarek Gruszczy Ski - Financial Microeconometrics - A Research Methodology in Corporate Finance and Accounting (2020)al chemiste100% (1)
- A Meta-Analysis of The Effects of Humor On AdvertisingDocument22 pagesA Meta-Analysis of The Effects of Humor On Advertisingcartegratuita100% (1)
- A Study On Customers Satisfaction Towards Allwin Pipes Private Limited, PerundurDocument27 pagesA Study On Customers Satisfaction Towards Allwin Pipes Private Limited, PerundurCHEIF EDITORNo ratings yet
- Awareness About Plagiarism Amongst University StudentsDocument12 pagesAwareness About Plagiarism Amongst University StudentsNoor AeniNo ratings yet
- Clustering in BioinformaticsDocument110 pagesClustering in BioinformaticstisimpsonNo ratings yet
- Supervised Learning by Fadhlurrohman HenriwanDocument31 pagesSupervised Learning by Fadhlurrohman HenriwanFadhlurrohman HenriwanNo ratings yet
- Assignment - Econometrics (Instrumental Variable Stock Watson)Document10 pagesAssignment - Econometrics (Instrumental Variable Stock Watson)Mutasim BillahNo ratings yet
- SSRN Id3260856Document34 pagesSSRN Id3260856Milton CocaNo ratings yet









































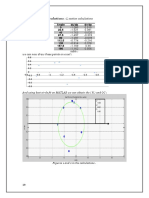























































Download as pdf or txt
You might also like
- HW7Document6 pagesHW7Clement Runtung100% (2)
- Problem-Solving and Data Analysis-Evaluating Statistical Claims - Observational Studies and ExperimentsDocument8 pagesProblem-Solving and Data Analysis-Evaluating Statistical Claims - Observational Studies and Experimentsttttvvv8No ratings yet
- MA in Political Economy - Handbook - 2016 (KCL)Document15 pagesMA in Political Economy - Handbook - 2016 (KCL)Hon Wai LaiNo ratings yet
- National Institute of Technology, Tiruchirappalli MBA Trimester Examination, Basic Data Analytic Marathon ExamDocument22 pagesNational Institute of Technology, Tiruchirappalli MBA Trimester Examination, Basic Data Analytic Marathon ExamArjun Jinumon PootharaNo ratings yet
- Group Number X - MACR - AssignmentDocument7 pagesGroup Number X - MACR - AssignmentRohitNo ratings yet
- Group 3 Glossier Case AnalysisDocument11 pagesGroup 3 Glossier Case AnalysisRohitNo ratings yet
- BdaDocument24 pagesBdaAbinNo ratings yet
- Credit-Scoring-CASEDocument29 pagesCredit-Scoring-CASEreach2ghoshNo ratings yet
- Super Bowl PredictionDocument34 pagesSuper Bowl PredictionAddy DamNo ratings yet
- Logistic RegressionDocument41 pagesLogistic RegressionMonica100% (1)
- D (I, J) R+s Q +R +S+TDocument5 pagesD (I, J) R+s Q +R +S+TNitish NehraNo ratings yet
- Corporate Risk EstimatesDocument21 pagesCorporate Risk EstimatesRahul sardanaNo ratings yet
- Smart PDFDocument6 pagesSmart PDFHardiyansahNo ratings yet
- Examples Correation and RegressionDocument29 pagesExamples Correation and RegressionMinahil FatimaNo ratings yet
- Knowledge Management Processes 5: Silvia Martelo-Landroguez and Gabriel Cepeda-CarriónDocument2 pagesKnowledge Management Processes 5: Silvia Martelo-Landroguez and Gabriel Cepeda-CarriónDani JaramilloNo ratings yet
- Session 1-Discriminant Analysis-1Document52 pagesSession 1-Discriminant Analysis-1devaki reddyNo ratings yet
- Assignment Module 1Document30 pagesAssignment Module 1Priyanka SindhwaniNo ratings yet
- Attribute Coeffs S.E. Wald Z P-ValueDocument8 pagesAttribute Coeffs S.E. Wald Z P-Valuesarthak mendirattaNo ratings yet
- Tablas de Distribucion de Probabilidad PDFDocument27 pagesTablas de Distribucion de Probabilidad PDFdanielNo ratings yet
- Assignment 8 6331 PDFDocument11 pagesAssignment 8 6331 PDFALIKNFNo ratings yet
- Lecture 3 Logistic RegressionDocument14 pagesLecture 3 Logistic Regressioniamboss086No ratings yet
- The SAS System The SAS System: The CORR Procedure The CORR ProcedureDocument1 pageThe SAS System The SAS System: The CORR Procedure The CORR ProcedureNakshtra DasNo ratings yet
- Newton Raphson Submission FileDocument9 pagesNewton Raphson Submission Fileshailesh upadhyayNo ratings yet
- Analytics Report: Gray Hunter and John Mcclintock Yamelle Gonzalez Dummy Variables APRIL 14, 2020Document4 pagesAnalytics Report: Gray Hunter and John Mcclintock Yamelle Gonzalez Dummy Variables APRIL 14, 2020api-529885888No ratings yet
- Computation of Multipliers: Specify The Survival Column, L (X), and The Cost of Care at Each AgeDocument7 pagesComputation of Multipliers: Specify The Survival Column, L (X), and The Cost of Care at Each AgeJay WhiteNo ratings yet
- Exam 1Document6 pagesExam 1Danien LopesNo ratings yet
- Econometric Analysis: DR Alka Chadha IIM TrichyDocument29 pagesEconometric Analysis: DR Alka Chadha IIM TrichyChintu KumarNo ratings yet
- Generate Unifrom DistributionDocument11 pagesGenerate Unifrom Distributionajaykum14No ratings yet
- Financial Management-1 Project ReportDocument6 pagesFinancial Management-1 Project ReportNakulesh VijayvargiyaNo ratings yet
- Mgt555 - Individual Assignment 2Document6 pagesMgt555 - Individual Assignment 22021230564100% (1)
- Primary Objective: A Study of The Shopping Behavior of Mobile Phone Users inDocument3 pagesPrimary Objective: A Study of The Shopping Behavior of Mobile Phone Users inIranshah MakerNo ratings yet
- Assignment 11 Team 4 Date 11/19/2018 Ananth Ramesh Qian Ciu Shikhar Goyal Tanish Gupta Vinay Sagar MudlapurDocument45 pagesAssignment 11 Team 4 Date 11/19/2018 Ananth Ramesh Qian Ciu Shikhar Goyal Tanish Gupta Vinay Sagar MudlapurAnanth RameshNo ratings yet
- Exercise 1Document9 pagesExercise 1Meryem LamhamdiNo ratings yet
- Askaria f1051151052 Modul UjiDocument27 pagesAskaria f1051151052 Modul UjiAskaria FahrezaNo ratings yet
- Capital Budgeting BSNLDocument10 pagesCapital Budgeting BSNLAşhwįnį GawasNo ratings yet
- Credit Risk Dataset AnalysisDocument7 pagesCredit Risk Dataset Analysisakothcathrine062No ratings yet
- Note 4Document18 pagesNote 4nuthan manideepNo ratings yet
- BUS270 Assignment 2Document28 pagesBUS270 Assignment 2Bharat KoiralaNo ratings yet
- The Bisection Algorithm: Either No Solutions or Multiple Solutions Between Left and Right BoundsDocument1 pageThe Bisection Algorithm: Either No Solutions or Multiple Solutions Between Left and Right BoundsAhmadMoaazNo ratings yet
- Ideality FactorDocument8 pagesIdeality FactorJeptha LalawmpuiaNo ratings yet
- Example Factor AnalysisDocument1 pageExample Factor AnalysisFCNo ratings yet
- Experimental CalculationsDocument5 pagesExperimental CalculationsmomenNo ratings yet
- Nama: Ersa Kusumawardani NPM: 0115103003/reg B2/C Mata Kuliah: Statistik Multivariat Tugas Eviews 1Document9 pagesNama: Ersa Kusumawardani NPM: 0115103003/reg B2/C Mata Kuliah: Statistik Multivariat Tugas Eviews 1ersa kusumawardaniNo ratings yet
- ODE 1st Order Ex1Document4 pagesODE 1st Order Ex1______.________No ratings yet
- Monserrat2D Activity6 AE9Document5 pagesMonserrat2D Activity6 AE9Jerome MonserratNo ratings yet
- Critical Analysis Of: Multiple Regression ModelDocument12 pagesCritical Analysis Of: Multiple Regression Modelsanket patilNo ratings yet
- Fogler Prob 6 14Document8 pagesFogler Prob 6 14Romero E MayrlaNo ratings yet
- REGRESSIONDocument2 pagesREGRESSIONUtkarsh VikramNo ratings yet
- Managerial Economics: Lecture 17 - Decision Making Under Risk Prof. Thiagu RanganathanDocument21 pagesManagerial Economics: Lecture 17 - Decision Making Under Risk Prof. Thiagu RanganathanAshishKushwahaNo ratings yet
- X EXP Serie Signo Serie Real Suma Error RelativoDocument8 pagesX EXP Serie Signo Serie Real Suma Error RelativoMargiori Supo PerezNo ratings yet
- Calculos Lab 3Document6 pagesCalculos Lab 3Esquivel Bocanegra Pablo HosmarNo ratings yet
- Structural Change in Developing Countries Has It Decreased Gender InequalityDocument12 pagesStructural Change in Developing Countries Has It Decreased Gender Inequalitylifetips6786No ratings yet
- I V Characterstics of PN Junction DiodeDocument10 pagesI V Characterstics of PN Junction Diodeمعاً إلى الجنةNo ratings yet
- Gaussian QuadratureDocument4 pagesGaussian Quadratureredeemer90No ratings yet
- Assignment 2 20L-2373 Abdul HaseebDocument12 pagesAssignment 2 20L-2373 Abdul Haseebsarwat abbasNo ratings yet
- 333 PDFDocument3 pages333 PDFMaicol Pulido RuizNo ratings yet
- X EXP Serie Signo Serie Real Suma Error RelativoDocument8 pagesX EXP Serie Signo Serie Real Suma Error RelativoMargiori Supo PerezNo ratings yet
- NR Report 1Document10 pagesNR Report 1shailesh upadhyayNo ratings yet
- Research MethodologyDocument6 pagesResearch MethodologyMANSHI RAINo ratings yet
- System Modelling and SimulationDocument19 pagesSystem Modelling and Simulationtve21ie060No ratings yet
- FR2202mock ExamDocument6 pagesFR2202mock ExamSunny LeNo ratings yet
- Probabilistic GradingDocument5 pagesProbabilistic GradingSeung Pyo SonNo ratings yet
- HW ExplanationDocument20 pagesHW ExplanationMysara MunneeNo ratings yet
- Statistical Analysis Using Microsoft ExcelDocument11 pagesStatistical Analysis Using Microsoft ExcelNithi AyyaluNo ratings yet
- Analyisis ResultsDocument11 pagesAnalyisis ResultsQasim ShahNo ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- Group 10 - HRM - Group AssignmentDocument16 pagesGroup 10 - HRM - Group AssignmentRohitNo ratings yet
- Group 6 - IBB - The Future AirportsDocument8 pagesGroup 6 - IBB - The Future AirportsRohitNo ratings yet
- CCDCV - D.light - Situation AnalysisDocument1 pageCCDCV - D.light - Situation AnalysisRohitNo ratings yet
- OD SimulationDocument1 pageOD SimulationRohitNo ratings yet
- Group 6 - IBB - Leveraging Blockchain in Land Registry - Real Estate SectorDocument9 pagesGroup 6 - IBB - Leveraging Blockchain in Land Registry - Real Estate SectorRohitNo ratings yet
- Rohit Satarke 2022EPGP042 LAB AssignmentDocument19 pagesRohit Satarke 2022EPGP042 LAB AssignmentRohitNo ratings yet
- 8) Multilevel AnalysisDocument41 pages8) Multilevel AnalysisMulusewNo ratings yet
- JL and Lucille CRD Stat2Document8 pagesJL and Lucille CRD Stat2Jevelyn Mendoza FarroNo ratings yet
- Laerd Statistics 2013Document3 pagesLaerd Statistics 2013Rene John Bulalaque Escal100% (1)
- Community Participation and Sustainable Management of Central Forest Reserve Research ProposalDocument46 pagesCommunity Participation and Sustainable Management of Central Forest Reserve Research ProposalKamira Sulait Kyepa75% (4)
- IIIDocument3 pagesIIIClarilyn TrivinoNo ratings yet
- Diskriminasi Aitem & Reliabilitas: Reliability StatisticsDocument10 pagesDiskriminasi Aitem & Reliabilitas: Reliability StatisticsDrizzle zleNo ratings yet
- Linear Discriminant AnalysisDocument33 pagesLinear Discriminant AnalysisNaman JainNo ratings yet
- Automation in Construction: R.S. Adhikari, O. Moselhi, A. BagchiDocument15 pagesAutomation in Construction: R.S. Adhikari, O. Moselhi, A. BagchisoujanaNo ratings yet
- Practical Research 1 Concept Mastery I. Multiple Choice: Choose The Letter of The Correct AnswerDocument3 pagesPractical Research 1 Concept Mastery I. Multiple Choice: Choose The Letter of The Correct AnswerSanta Dumlao0% (1)
- AStudyon Dataminingtechniquestoimprovestudentsperformancein Higher EducationDocument7 pagesAStudyon Dataminingtechniquestoimprovestudentsperformancein Higher Educationddol36899No ratings yet
- JMP Stat Graph GuideDocument1,068 pagesJMP Stat Graph Guidekfaulk1100% (4)
- Data Latihan AnovaDocument15 pagesData Latihan AnovaNuraini MeinaNo ratings yet
- EPM 1173 Day 6A-Unit 5-MSP-ResourcesDocument45 pagesEPM 1173 Day 6A-Unit 5-MSP-ResourcesRahul ChawlaNo ratings yet
- The Journal Oct-Dec 2018 PDFDocument104 pagesThe Journal Oct-Dec 2018 PDFDevi Varra Prasad TirunagariNo ratings yet
- DWBI Concepts AllDocument83 pagesDWBI Concepts Allnirmalph100% (3)
- Syllabus-MBAE 0046Document2 pagesSyllabus-MBAE 0046J SujathaNo ratings yet
- Bcom 25 04Document278 pagesBcom 25 04Abila RevathyNo ratings yet
- CH 10 TestDocument23 pagesCH 10 TestDaniel Hunks100% (1)
- Marek Gruszczy Ski - Financial Microeconometrics - A Research Methodology in Corporate Finance and Accounting (2020)Document228 pagesMarek Gruszczy Ski - Financial Microeconometrics - A Research Methodology in Corporate Finance and Accounting (2020)al chemiste100% (1)
- A Meta-Analysis of The Effects of Humor On AdvertisingDocument22 pagesA Meta-Analysis of The Effects of Humor On Advertisingcartegratuita100% (1)
- A Study On Customers Satisfaction Towards Allwin Pipes Private Limited, PerundurDocument27 pagesA Study On Customers Satisfaction Towards Allwin Pipes Private Limited, PerundurCHEIF EDITORNo ratings yet
- Awareness About Plagiarism Amongst University StudentsDocument12 pagesAwareness About Plagiarism Amongst University StudentsNoor AeniNo ratings yet
- Clustering in BioinformaticsDocument110 pagesClustering in BioinformaticstisimpsonNo ratings yet
- Supervised Learning by Fadhlurrohman HenriwanDocument31 pagesSupervised Learning by Fadhlurrohman HenriwanFadhlurrohman HenriwanNo ratings yet
- Assignment - Econometrics (Instrumental Variable Stock Watson)Document10 pagesAssignment - Econometrics (Instrumental Variable Stock Watson)Mutasim BillahNo ratings yet
- SSRN Id3260856Document34 pagesSSRN Id3260856Milton CocaNo ratings yet