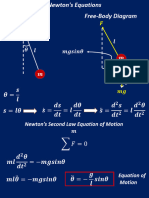
Download as docx, pdf, or txt
You might also like
- Hassan K. Khalil - Complete Solution Manual For Nonlinear SystemsDocument241 pagesHassan K. Khalil - Complete Solution Manual For Nonlinear SystemsDavid Mesa100% (6)
- Applied NLPDocument8 pagesApplied NLPkapiljain198950% (2)
- Data Lab AnswersDocument7 pagesData Lab AnswersdryzhkoNo ratings yet
- Data Cleaning Data Integration Data Selection Data Transformation Data Mining Pattern Evaluation Knowledge PresentationDocument3 pagesData Cleaning Data Integration Data Selection Data Transformation Data Mining Pattern Evaluation Knowledge PresentationbaskarchennaiNo ratings yet
- Latihan Analisis VariansDocument4 pagesLatihan Analisis VariansJessica Loong100% (1)
- Unit III Data Mining TechniquesDocument17 pagesUnit III Data Mining TechniquesAjit RautNo ratings yet
- Ch15multilevel Association Rules PDFDocument11 pagesCh15multilevel Association Rules PDFTeja Krishna MutluriNo ratings yet
- Clustering: Dr. Md. Al-Amin BhuiyanDocument6 pagesClustering: Dr. Md. Al-Amin BhuiyanRaihan Mastafa KhiljeeNo ratings yet
- MMWChapter4 6Document66 pagesMMWChapter4 6Camelia CanamanNo ratings yet
- ML Ch-3 Unsupervised LearningDocument31 pagesML Ch-3 Unsupervised LearningNasis DerejeNo ratings yet
- UNIT 3 DWDM NotesDocument32 pagesUNIT 3 DWDM NotesDivyanshNo ratings yet
- Datamining Fifth LectureDocument65 pagesDatamining Fifth LecturepoonamNo ratings yet
- Unit-3 DWDM 7TH Sem CseDocument54 pagesUnit-3 DWDM 7TH Sem CseNavdeep KhubberNo ratings yet
- DWM 5Document9 pagesDWM 5waghjayesh07No ratings yet
- Unit 2: Scs5623 - Data Mining and WarehousingDocument9 pagesUnit 2: Scs5623 - Data Mining and WarehousingAYAAN SatkutNo ratings yet
- DWDM Unit 3Document15 pagesDWDM Unit 3sri charanNo ratings yet
- Clustering - The Data EnsembleDocument4 pagesClustering - The Data EnsembleDaniel N Sherine FooNo ratings yet
- Dmbi Unit-4Document18 pagesDmbi Unit-4Paras SharmaNo ratings yet
- DWH Final PrepDocument17 pagesDWH Final PrepShamila SaleemNo ratings yet
- Predictive Analytics Unsupervised Module 4Document49 pagesPredictive Analytics Unsupervised Module 4Sree LakshmiNo ratings yet
- ClusteringDocument37 pagesClusteringRafaelNo ratings yet
- Mining Various Kinds of Association RulesDocument11 pagesMining Various Kinds of Association RulesJay MehtaNo ratings yet
- DataMining Aug2021Document49 pagesDataMining Aug2021sakshi narang100% (2)
- ML Unit - IiiDocument64 pagesML Unit - IiitejasviponugotiNo ratings yet
- Iv Unit DMDocument26 pagesIv Unit DMVishwanth BavireddyNo ratings yet
- What Is Clustering?: Points To RememberDocument10 pagesWhat Is Clustering?: Points To RememberUBSHimanshu KumarNo ratings yet
- DM UNIT-1 Question and AnswerDocument25 pagesDM UNIT-1 Question and AnswerPooja ReddyNo ratings yet
- Overview of Clustering:: UNIT-5Document27 pagesOverview of Clustering:: UNIT-5Kalyan VarmaNo ratings yet
- Discussion For Today: Probability Sampling Non Probability Sampling QuestionnaireDocument31 pagesDiscussion For Today: Probability Sampling Non Probability Sampling QuestionnaireSheraz AhmedNo ratings yet
- Classification Algorithm in Machine LearningDocument7 pagesClassification Algorithm in Machine Learningsumit ChauhanNo ratings yet
- MLunit 2 MynotesDocument15 pagesMLunit 2 MynotesVali BhashaNo ratings yet
- DM Lecture 06Document32 pagesDM Lecture 06Sameer AhmadNo ratings yet
- Data Mining SlidesDocument65 pagesData Mining SlidesKriwaczfNo ratings yet
- Decision TreesDocument14 pagesDecision TreesJustin Russo Harry50% (2)
- Cluster Is A Group of Objects That Belongs To The Same ClassDocument12 pagesCluster Is A Group of Objects That Belongs To The Same ClasskalpanaNo ratings yet
- Unit 4 - Machine Learning - WWW - Rgpvnotes.in PDFDocument27 pagesUnit 4 - Machine Learning - WWW - Rgpvnotes.in PDFYouth MakerNo ratings yet
- CO3 TopicwiseDocument37 pagesCO3 TopicwiseVV PRAVEENNo ratings yet
- Agglomerative Is A Bottom-Up Technique, But Divisive Is A Top-Down TechniqueDocument8 pagesAgglomerative Is A Bottom-Up Technique, But Divisive Is A Top-Down Techniquetirth patelNo ratings yet
- Decision Tree Algorithm: and Classification Problems TooDocument12 pagesDecision Tree Algorithm: and Classification Problems TooAva WhiteNo ratings yet
- Data Analytics QuestionsDocument40 pagesData Analytics Questionsankitraj318No ratings yet
- Exam SummaryDocument15 pagesExam SummaryLaurin KnödlerNo ratings yet
- DWM 5Document17 pagesDWM 5Shivraj JadhavNo ratings yet
- Assignment: Q1. Explain Data Collection by Mailed Questionnaires With Its Merits and Demerits? Ans 1Document8 pagesAssignment: Q1. Explain Data Collection by Mailed Questionnaires With Its Merits and Demerits? Ans 1shwetasingh048No ratings yet
- Lecture2 DataMiningFunctionalitiesDocument18 pagesLecture2 DataMiningFunctionalitiesinsaanNo ratings yet
- Data Science Crash CourseDocument32 pagesData Science Crash CourseAbhinandan ChatterjeeNo ratings yet
- Practical Software TestingDocument3 pagesPractical Software Testingralliart artNo ratings yet
- M.L. 3,5,6 Unit 3Document6 pagesM.L. 3,5,6 Unit 3atharv moreNo ratings yet
- Decision Tree Algorithm, Explained-1-22Document22 pagesDecision Tree Algorithm, Explained-1-22shylaNo ratings yet
- ClusteringDocument6 pagesClusteringdhruu2503No ratings yet
- Unit 4Document74 pagesUnit 4Sai ManasaNo ratings yet
- Data Mining and Its TechniquesDocument20 pagesData Mining and Its TechniquesvasupahujaNo ratings yet
- Mining Using Genitic AlgorithmsDocument7 pagesMining Using Genitic AlgorithmsChandu ChandanaNo ratings yet
- Data Mining (Viva)Document18 pagesData Mining (Viva)Anubhav ShrivastavaNo ratings yet
- Assignment 4Document40 pagesAssignment 4Aditya BossNo ratings yet
- Online Course AssignmentsDocument8 pagesOnline Course Assignmentsmsc csNo ratings yet
- Data Mining-Unit IVDocument15 pagesData Mining-Unit IVDrishti GuptaNo ratings yet
- Data Science Intervieew QuestionsDocument16 pagesData Science Intervieew QuestionsSatyam Anand100% (1)
- Data Mining: Kabith Sivaprasad (BE/1234/2009) Rimjhim (BE/1134/2009) Utkarsh Ahuja (BE/1226/2009)Document32 pagesData Mining: Kabith Sivaprasad (BE/1234/2009) Rimjhim (BE/1134/2009) Utkarsh Ahuja (BE/1226/2009)Rule2No ratings yet
- DM - 01 - 02 - Data Mining Functionalities PDFDocument63 pagesDM - 01 - 02 - Data Mining Functionalities PDFshouryaraj batraNo ratings yet
- The Elements of Statistical Learning NotesDocument3 pagesThe Elements of Statistical Learning Notesmuhtaqi786No ratings yet
- 2 - 2022 - Advanced Bio2 - ClustereddataDocument58 pages2 - 2022 - Advanced Bio2 - ClustereddataMartin Panashe ChirindaNo ratings yet
- Machine Learning QNADocument1 pageMachine Learning QNApratikmovie999No ratings yet
- UNIT 3 Data MiningDocument11 pagesUNIT 3 Data MiningmahiNo ratings yet
- Local VolatilityDocument87 pagesLocal VolatilityClaudio Cuevas PazosNo ratings yet
- Lecture 17: General Quantum Errors CSS Codes: CPSC 519/619: Quantum Computation John Watrous, University of CalgaryDocument7 pagesLecture 17: General Quantum Errors CSS Codes: CPSC 519/619: Quantum Computation John Watrous, University of CalgaryarcchemNo ratings yet
- IS Lab MannualDocument26 pagesIS Lab Mannualvasudha sankpalNo ratings yet
- 10.1016 J.engfracmech.2017.08.004 Minimum Energy Multiple Crack Propagation Part III XFEM Computer Implementation and ApplicationsDocument43 pages10.1016 J.engfracmech.2017.08.004 Minimum Energy Multiple Crack Propagation Part III XFEM Computer Implementation and Applicationshamid rezaNo ratings yet
- AI IntroductionDocument376 pagesAI IntroductionjNo ratings yet
- Sri 4a, B, C 5a, B StatementDocument6 pagesSri 4a, B, C 5a, B StatementSai VarmaNo ratings yet
- Ppt-2 Blockchain StructureDocument36 pagesPpt-2 Blockchain StructureJitin JitinNo ratings yet
- Mid Semester: ExaminationDocument5 pagesMid Semester: ExaminationLekha PylaNo ratings yet
- Cse497b Lecture 6 Cryptography PDFDocument20 pagesCse497b Lecture 6 Cryptography PDFBelaliaNo ratings yet
- Codings 1Document12 pagesCodings 1Nagaraja RaoNo ratings yet
- 5th Sem ADA ManualDocument41 pages5th Sem ADA ManualManjunath GmNo ratings yet
- Graph Theory and Algorithms Assignment 1: ×M Matrix. Consider A Graph G Whose Vertices Are The EntriesDocument2 pagesGraph Theory and Algorithms Assignment 1: ×M Matrix. Consider A Graph G Whose Vertices Are The EntriesSanjoy PanditNo ratings yet
- Why Do We Use Cross Validation Set in Our Models?Document2 pagesWhy Do We Use Cross Validation Set in Our Models?vinay kumarNo ratings yet
- Lecture 2-Data ScienceDocument25 pagesLecture 2-Data ScienceAmal ObeidallhNo ratings yet
- SVD SlidesDocument26 pagesSVD Slidesashish ranjanNo ratings yet
- Cheat Sheet: Python For Data ScienceDocument4 pagesCheat Sheet: Python For Data ScienceEVELIN VERANo ratings yet
- GEM - 111 - Module 1 (Chapter 1)Document21 pagesGEM - 111 - Module 1 (Chapter 1)Aberin Andoyo AlimbonNo ratings yet
- Residue Number System: Dr. Arunachalam V Associate Professor, SENSEDocument13 pagesResidue Number System: Dr. Arunachalam V Associate Professor, SENSEAnil Kumar GorantalaNo ratings yet
- Lab2 - TMC-đã G PDocument41 pagesLab2 - TMC-đã G PHuỳnh Huy Thịnh VõNo ratings yet
- Cs6702 Graph Theory and Applications Question Bank Unit I Introduction Part - ADocument6 pagesCs6702 Graph Theory and Applications Question Bank Unit I Introduction Part - Avidhya_bineeshNo ratings yet
- Sample Data Sets For Linear Regression1Document6 pagesSample Data Sets For Linear Regression1Thảo NguyễnNo ratings yet
- CS 70 Discrete Mathematics and Probability Theory Spring 2012 Alistair Sinclair Note 1 Course OutlineDocument6 pagesCS 70 Discrete Mathematics and Probability Theory Spring 2012 Alistair Sinclair Note 1 Course Outlineshogun2fire4424No ratings yet
- Simple Pendulum Modelling Simulation 1686477167Document12 pagesSimple Pendulum Modelling Simulation 1686477167durssiNo ratings yet
- Measurement and Data Processing: I. Uncertainties and Errors in Measurement and ResultsDocument6 pagesMeasurement and Data Processing: I. Uncertainties and Errors in Measurement and ResultsKip 2No ratings yet
- Special Theory of Relativity (Solution)Document5 pagesSpecial Theory of Relativity (Solution)Neeraj MeenaNo ratings yet
- Anonymous - Thus Spake Professor Michael Witzel A Harvard University Case Study in PrejudiceDocument2 pagesAnonymous - Thus Spake Professor Michael Witzel A Harvard University Case Study in Prejudiceshaun_marvin_1No ratings yet