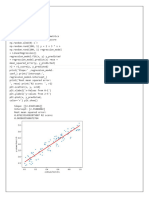
Download as docx, pdf, or txt
You might also like
- Lifecomm ProductDocument9 pagesLifecomm Productphani100% (2)
- Wind Load Calculation ReportDocument26 pagesWind Load Calculation Reportsyed muneeb haiderNo ratings yet
- DM PracticeDocument15 pagesDM Practice66 Rohit PatilNo ratings yet
- Bipin Python ProgrammingDocument21 pagesBipin Python ProgrammingVipin SinghNo ratings yet
- Data Science ManualDocument16 pagesData Science ManualKRISHNAVENI RNo ratings yet
- Python Myssql Programs For Practical File Class 12 IpDocument26 pagesPython Myssql Programs For Practical File Class 12 IpPragyanand SinghNo ratings yet
- Is Lab 7Document7 pagesIs Lab 7Aman BansalNo ratings yet
- Is Lab 7Document7 pagesIs Lab 7Aman BansalNo ratings yet
- Is Lab Aman Agarwal PDFDocument8 pagesIs Lab Aman Agarwal PDFAman BansalNo ratings yet
- Practical File of Machine Learning 1905388Document42 pagesPractical File of Machine Learning 1905388DevanshNo ratings yet
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- AIML Record 56Document28 pagesAIML Record 56saisatwik bikumandlaNo ratings yet
- DWDM Lab AllDocument20 pagesDWDM Lab AllPoojaDevi SharmaNo ratings yet
- Exp 6Document6 pagesExp 6jayNo ratings yet
- Soft Sensor CodeDocument4 pagesSoft Sensor CodeMarvin MartinsNo ratings yet
- Soft Sensor CodeDocument4 pagesSoft Sensor CodeMarvin MartinsNo ratings yet
- Wa0002.Document5 pagesWa0002.sir BryanNo ratings yet
- DS Slips Solutions Sem 5Document23 pagesDS Slips Solutions Sem 5yashm4071No ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- Machine Learning Lab Assignment 2: Name: D.Penchal Reddy Reg. No: 17BCE0918 Class: L31+32Document2 pagesMachine Learning Lab Assignment 2: Name: D.Penchal Reddy Reg. No: 17BCE0918 Class: L31+32Penchal DoggalaNo ratings yet
- PML Ex3 FinalDocument20 pagesPML Ex3 FinalJasmitha BNo ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- ML Lab ManualDocument37 pagesML Lab Manualapekshapandekar01100% (1)
- R FileDocument18 pagesR FileJyoti GodaraNo ratings yet
- Computational Techniques in Statistics: Exercise 1Document5 pagesComputational Techniques in Statistics: Exercise 1وجدان الشداديNo ratings yet
- Naive - Bayes - Ipynb - ColabDocument3 pagesNaive - Bayes - Ipynb - ColabAgi TasyaNo ratings yet
- Advance Python Lab SolutionDocument4 pagesAdvance Python Lab Solutionsachinsingh991127No ratings yet
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- My CodeDocument7 pagesMy Codeoyelekeayomide1No ratings yet
- Prob13: 1 EE16A Homework 13Document23 pagesProb13: 1 EE16A Homework 13Michael ARKNo ratings yet
- MLfullDocument29 pagesMLfullJanvi PatelNo ratings yet
- Linear 81Document2 pagesLinear 817amazon.970No ratings yet
- MLR Example 2predictorsDocument5 pagesMLR Example 2predictorswangshiui2002No ratings yet
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (2)
- Aiml Record From 1 To 10Document10 pagesAiml Record From 1 To 10avsworld1234No ratings yet
- Machinelearning - Alisya Athirah Binti Mohd Huzzainny (Updated)Document26 pagesMachinelearning - Alisya Athirah Binti Mohd Huzzainny (Updated)Alisya AthirahNo ratings yet
- Regresion LInealDocument1 pageRegresion LInealADOLFO NAVARRO CAYONo ratings yet
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- DM Slip-2Document1 pageDM Slip-209.Khadija GharatkarNo ratings yet
- Anemia CodeDocument33 pagesAnemia Codesksharini67No ratings yet
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (2)
- ML LabDocument7 pagesML LabSharan PatilNo ratings yet
- R ProgramsDocument12 pagesR Programssamuel samNo ratings yet
- HOUSE PRICINGDocument15 pagesHOUSE PRICINGsanjana.devarapalli7No ratings yet
- R19C076 - Chanukya Gowda K - Mlda - Assignment-2Document19 pagesR19C076 - Chanukya Gowda K - Mlda - Assignment-2Chanukya Gowda kNo ratings yet
- Urmi ML Practical FileDocument37 pagesUrmi ML Practical Filebekar kaNo ratings yet
- Phython Practical NotebookDocument14 pagesPhython Practical Notebookbabu royNo ratings yet
- Phython Practical Notebook1Document14 pagesPhython Practical Notebook1babu royNo ratings yet
- Handwritten Character Recognition With Neural NetworkDocument12 pagesHandwritten Character Recognition With Neural Networkshreyash sononeNo ratings yet
- Online Payment Fraud Detection Using Machine LearningDocument2 pagesOnline Payment Fraud Detection Using Machine LearningDev Ranjan RautNo ratings yet
- HurairaDocument26 pagesHurairaMuhammad Asim Muhammad ArshadNo ratings yet
- Ad3411 Data Science and Analytics LaboratoryDocument24 pagesAd3411 Data Science and Analytics LaboratoryMohamed Shajid N100% (7)
- PCA ExplainedDocument9 pagesPCA ExplainedRaj kumarNo ratings yet
- Lab-5 ReportDocument11 pagesLab-5 Reportjithentar.cs21No ratings yet
- Stats Practical WJCDocument23 pagesStats Practical WJCBhuvanesh SriniNo ratings yet
- Experiment 10Document4 pagesExperiment 10Ananya KumariNo ratings yet
- Big Data File in RDocument23 pagesBig Data File in RPrabhu GoyalNo ratings yet
- Import Pandas as PdDocument21 pagesImport Pandas as Pdcaptainsaad838No ratings yet
- Da ProgramDocument18 pagesDa Programalishacalista238No ratings yet
- G Pandey PracticalDocument33 pagesG Pandey PracticalSadananda Moirãngthëm Gidi LêïjreNo ratings yet
- Normal Approximation of The Poisson DistributionDocument1 pageNormal Approximation of The Poisson DistributionChooi Jia YueNo ratings yet
- Design of Intelligent Ambulance and Traffic Control RFDocument12 pagesDesign of Intelligent Ambulance and Traffic Control RFBala GaneshNo ratings yet
- EVD Evolution Twin: User ManualDocument68 pagesEVD Evolution Twin: User ManualcamdentownNo ratings yet
- PMSS 25 - Effective Written Communication - PresentationDocument24 pagesPMSS 25 - Effective Written Communication - Presentationcemplon007No ratings yet
- GRZ100 D - Model 0.1Document38 pagesGRZ100 D - Model 0.1krishna mohanNo ratings yet
- Apd4 T88res Install e RevbDocument54 pagesApd4 T88res Install e RevbMSushi MsushispaNo ratings yet
- 20105-AR-GEN-00-004-01 Rev 02Document1 page20105-AR-GEN-00-004-01 Rev 02Bahaa MohamedNo ratings yet
- Windows 7 Data RecoveryDocument8 pagesWindows 7 Data RecoveryAsai NeonNo ratings yet
- Trends: Technology Trend Awareness As A Skill Refers To Being Mindful ofDocument6 pagesTrends: Technology Trend Awareness As A Skill Refers To Being Mindful ofleslie jane archivalNo ratings yet
- Hands On Virtual Computing 9781337101936 1337101931 CompressDocument587 pagesHands On Virtual Computing 9781337101936 1337101931 Compressxinag92686No ratings yet
- Basic Config RouterDocument31 pagesBasic Config RouterNguyễn Hoài TrungNo ratings yet
- Nozomi Networks - OilGas - Solution DeckDocument10 pagesNozomi Networks - OilGas - Solution Deckfateh tiribarkNo ratings yet
- Hover-Net: Simultaneous Segmentation and Classification of Nuclei in Multi-Tissue Histology ImagesDocument19 pagesHover-Net: Simultaneous Segmentation and Classification of Nuclei in Multi-Tissue Histology ImagesAhmed WaelNo ratings yet
- SAP SD Configuration: Project ManagementDocument20 pagesSAP SD Configuration: Project Managementsyed hyder ALINo ratings yet
- MoP MLTN Swap To ML6600Document11 pagesMoP MLTN Swap To ML6600MATAR NIANGNo ratings yet
- The 8051 Microcontroller: Hsabaghianb at Kashanu - Ac.ir 1Document141 pagesThe 8051 Microcontroller: Hsabaghianb at Kashanu - Ac.ir 1amolmule123100% (1)
- FCM Kao DCS - Rev1Document34 pagesFCM Kao DCS - Rev1Izarulhaq AwangNo ratings yet
- Management Information SystemDocument97 pagesManagement Information SystemNORIZA BINTI CHE SOH STUDENTNo ratings yet
- Ai & ML - ModuleDocument35 pagesAi & ML - ModulePrem PatilNo ratings yet
- Alan Annunciator MLD 02Document8 pagesAlan Annunciator MLD 02Srinivasan Srini50% (2)
- Fundamentals of Deep LearningDocument37 pagesFundamentals of Deep LearningAlejandroHerreraGurideChileNo ratings yet
- Iot Based Intelligent TrolleyDocument10 pagesIot Based Intelligent TrolleyHithesh GowdaNo ratings yet
- Chapter 10: Natural Language Processing: Components of NLPDocument3 pagesChapter 10: Natural Language Processing: Components of NLPManish Shrestha100% (1)
- Cs2100 Computer Organisation Lab #10: Using Logisim Ii: (This Document Is Available On Luminus and Module Website)Document3 pagesCs2100 Computer Organisation Lab #10: Using Logisim Ii: (This Document Is Available On Luminus and Module Website)Sourabh RajNo ratings yet
- Veteran2015720pbrrip1gbmkvcage PDFDocument3 pagesVeteran2015720pbrrip1gbmkvcage PDFSamNo ratings yet
- Assignment 2 FingerprintDocument2 pagesAssignment 2 FingerprintElaiza Bave MoqueteNo ratings yet
- Advantech Adam 3600 Intelligent Rtu EbookDocument33 pagesAdvantech Adam 3600 Intelligent Rtu Ebookrusnardi hanif radityaNo ratings yet
- APA ReferencesDocument32 pagesAPA ReferencesAhanaf RashidNo ratings yet