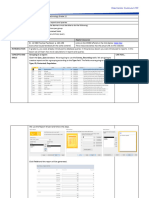
Download as pdf or txt
You might also like
- Arcgis Assignments PDFDocument96 pagesArcgis Assignments PDFSeverodvinsk MasterskayaNo ratings yet
- GISTutorialforArcGISPro2.8 AssignmentsDocument90 pagesGISTutorialforArcGISPro2.8 Assignmentssumalee100% (1)
- Class 12 CS Practical List 2023-24Document31 pagesClass 12 CS Practical List 2023-24bipashadoke2005No ratings yet
- QMM1001 Module 3 (1) Applied ActivityDocument2 pagesQMM1001 Module 3 (1) Applied ActivityIP RanaNo ratings yet
- Homework2 PDFDocument3 pagesHomework2 PDFTeoTheSpazNo ratings yet
- My SopDocument3 pagesMy SophannanNo ratings yet
- AML-2203 Advanced Python AI and ML Tools AssignmentDocument19 pagesAML-2203 Advanced Python AI and ML Tools AssignmentRohit NNo ratings yet
- 2 1 ABAP Basics Data Handling 1Document11 pages2 1 ABAP Basics Data Handling 1srikanthhhhhNo ratings yet
- CAT - Grade 12 T1 W6Document12 pagesCAT - Grade 12 T1 W6Thato Moratuwa MoloantoaNo ratings yet
- Data ProgrammingDocument4 pagesData ProgrammingI211381 Eeman IjazNo ratings yet
- Joint ProjectDocument3 pagesJoint Projectapi-386979696No ratings yet
- Programming Fundamentals Assignment 04Document4 pagesProgramming Fundamentals Assignment 04F219208 Muhammad Ahmad ShakeelNo ratings yet
- Geographic Information System - NotesDocument18 pagesGeographic Information System - Notes36-Rumaisa RaviNo ratings yet
- Computer Engineering: List of ExperimentsDocument2 pagesComputer Engineering: List of ExperimentsMobile MartNo ratings yet
- Excel Group Project 1: Data and Sample CalculationsDocument4 pagesExcel Group Project 1: Data and Sample CalculationsARUN KUMARNo ratings yet
- Opim529 hw1Document3 pagesOpim529 hw1Mohsin IqbalNo ratings yet
- Hands-On Exercise 2Document11 pagesHands-On Exercise 2Abdulfatai YakubNo ratings yet
- WEEK 3 Activity - Assignment 1Document5 pagesWEEK 3 Activity - Assignment 1colelavigne000No ratings yet
- CU-2020 B.A. B.Sc. (Honours) Economics Semester-V Paper-DSE-A-1P Practical QPDocument2 pagesCU-2020 B.A. B.Sc. (Honours) Economics Semester-V Paper-DSE-A-1P Practical QPRiju PrasadNo ratings yet
- Programming Fundamentals AssignmentsDocument4 pagesProgramming Fundamentals AssignmentscutieedivyaNo ratings yet
- Project Work: Class 10Document10 pagesProject Work: Class 10Santosh JhaNo ratings yet
- A05 Logic and Plots: InstructionsDocument7 pagesA05 Logic and Plots: Instructionsbrinda mehtaNo ratings yet
- AUM CE368 - Project - SUMMER2023Document11 pagesAUM CE368 - Project - SUMMER2023Saleh SalehNo ratings yet
- Fahim Ahammed Niyas 10-C: Name: Class: Teacher in ChargeDocument21 pagesFahim Ahammed Niyas 10-C: Name: Class: Teacher in ChargeMadina Niyas AhammedNo ratings yet
- 2004 2 Question PaperDocument9 pages2004 2 Question Papermwaseem2011No ratings yet
- ECON+1274 1248 Project 2023Document4 pagesECON+1274 1248 Project 2023kdoll 29No ratings yet
- Caim PracticalsDocument4 pagesCaim PracticalsShakti dodiya100% (2)
- Lab 5 - InstructionDocument5 pagesLab 5 - InstructionPanagiota BoussiosNo ratings yet
- NFD 153 ProjectDocument2 pagesNFD 153 Projectapi-286063651No ratings yet
- Assignment 1 - 2023springDocument3 pagesAssignment 1 - 2023springKA I LAONo ratings yet
- Unit I TS&FDocument55 pagesUnit I TS&FEugene Berna INo ratings yet
- מצגת תרגול 7Document20 pagesמצגת תרגול 7Gal ZeevNo ratings yet
- Data Visualization in Python: Worksheet 2.6Document1 pageData Visualization in Python: Worksheet 2.6Emely GonzagaNo ratings yet
- Core 1: Computer Fundamentals Unit - IDocument45 pagesCore 1: Computer Fundamentals Unit - IGuna AkhilNo ratings yet
- MATLAB Homework 5: Exercise 5. 1 Load and Convert Data (2pts)Document2 pagesMATLAB Homework 5: Exercise 5. 1 Load and Convert Data (2pts)Riaz AhmadNo ratings yet
- Sliding Puzzle 2024Document5 pagesSliding Puzzle 2024liaojunjian01No ratings yet
- CSC JUNE 2021 Group 3Document4 pagesCSC JUNE 2021 Group 3CiaraNo ratings yet
- Project1 Instructions StatisticsDocument2 pagesProject1 Instructions StatisticsJessica JimenezNo ratings yet
- Assignment For Final 2 PDFDocument4 pagesAssignment For Final 2 PDFcsolutionNo ratings yet
- Test Your Knowledge of Linear Regression and PCA in RDocument7 pagesTest Your Knowledge of Linear Regression and PCA in RChong Jun WeiNo ratings yet
- Reference (1) : Unit I: Computer Fundamentals Unit II: User Computer Interface Chapter 1,2Document11 pagesReference (1) : Unit I: Computer Fundamentals Unit II: User Computer Interface Chapter 1,2Hasan ShahariarNo ratings yet
- Working With DB2 UDB DataDocument32 pagesWorking With DB2 UDB Datashantesh143No ratings yet
- Final Report Remote SensingDocument18 pagesFinal Report Remote SensingFaissalBoziNo ratings yet
- Figure P1.1 The File Structure For Problems A-F: Page 1 of 7Document7 pagesFigure P1.1 The File Structure For Problems A-F: Page 1 of 7Yogavasth ManiNo ratings yet
- Homework 2 AssignmentDocument6 pagesHomework 2 AssignmentKellieLeon0% (2)
- Figure P1.1 The File Structure For Problems A-F: Database Systems Tutorial 1Document7 pagesFigure P1.1 The File Structure For Problems A-F: Database Systems Tutorial 1Yogavasth ManiNo ratings yet
- ProjectDocument4 pagesProjectSameer HussainNo ratings yet
- Block 5 - Excel Classwork TasksDocument10 pagesBlock 5 - Excel Classwork TasksMahmoud A.RaoufNo ratings yet
- Gretl Guide (201 250)Document50 pagesGretl Guide (201 250)Taha NajidNo ratings yet
- University of Derby School of Electronics, Computing and Mathematics In-Course Assignment SpecificationDocument5 pagesUniversity of Derby School of Electronics, Computing and Mathematics In-Course Assignment Specificationسید کاظمیNo ratings yet
- Assignment 1Document1 pageAssignment 1XuanNo ratings yet
- FoxCharts Documentation - A TutorialDocument43 pagesFoxCharts Documentation - A TutorialCristian Ant. Zorrilla Mota100% (1)
- Prduction Assignment-1 MUGUNTHANDocument9 pagesPrduction Assignment-1 MUGUNTHANMugun ThanNo ratings yet
- Assignment3 A20Document3 pagesAssignment3 A20April DingNo ratings yet
- Lab 8 InstructionsDocument1 pageLab 8 Instructionsapi-389057247No ratings yet
- chp13 SomeFinalThoughtsDocument35 pageschp13 SomeFinalThoughtsAshikur RahmanNo ratings yet
- Data Visualization - Day 3 - in Class Exercises - Geospatial Graphs - Solution FinalDocument54 pagesData Visualization - Day 3 - in Class Exercises - Geospatial Graphs - Solution FinalGhulamNo ratings yet
- Ip Practical File Class 12 - B JyotiDocument25 pagesIp Practical File Class 12 - B JyotiMahi SrivastavaNo ratings yet
- Rahulsharma - 03 12 23Document26 pagesRahulsharma - 03 12 23Rahul GautamNo ratings yet
- DB2 11 for z/OS: Intermediate Training for Application DevelopersFrom EverandDB2 11 for z/OS: Intermediate Training for Application DevelopersNo ratings yet
- AP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceFrom EverandAP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceNo ratings yet
- Tips For Writing A Good ReportDocument2 pagesTips For Writing A Good ReportKelly Low100% (1)
- Ii. Ancient Greek Period (500Bc-300Bc)Document4 pagesIi. Ancient Greek Period (500Bc-300Bc)bryanNo ratings yet
- General EDPDocument11 pagesGeneral EDPgetnarendra4uNo ratings yet
- Research Methodology MB0050: Q1. A) Explain The Types of ResearchDocument8 pagesResearch Methodology MB0050: Q1. A) Explain The Types of ResearchBhupendra KarandikarNo ratings yet
- Studies On The Effect of Mixing Time Speed and ConDocument9 pagesStudies On The Effect of Mixing Time Speed and ConMohammad Nazmin Syamsul BahriNo ratings yet
- Schedule-Dates of The Group Research WritingDocument2 pagesSchedule-Dates of The Group Research WritingRodrick Sonajo RamosNo ratings yet
- Turkey Mining 2018 - Web VersionDocument68 pagesTurkey Mining 2018 - Web VersionAnonymous C0lBgO24iNo ratings yet
- Video Based Observational Gait AnalysisDocument77 pagesVideo Based Observational Gait AnalysisRashidkpvldNo ratings yet
- TE-MiniProject Mock 2 PresentationDocument18 pagesTE-MiniProject Mock 2 Presentationganesh.gc8747No ratings yet
- Econ 312-01 Fall 2012 - SyllabusDocument4 pagesEcon 312-01 Fall 2012 - SyllabusSameh SemaryNo ratings yet
- Cat 2009 English Test 110Document4 pagesCat 2009 English Test 110comploreNo ratings yet
- Dark TriadDocument20 pagesDark TriadAnish DevNo ratings yet
- TP 12 Pap PDFDocument7 pagesTP 12 Pap PDFjayant pathakNo ratings yet
- Case Study - PTC FoodsDocument3 pagesCase Study - PTC Foodsdrive8124No ratings yet
- Technical Director or Chief Metallurgist or Technology Manager oDocument3 pagesTechnical Director or Chief Metallurgist or Technology Manager oapi-78679177No ratings yet
- MCQs MBADocument50 pagesMCQs MBAKomal BasantaniNo ratings yet
- Mapping The Scienti Fic Research On Open Data: A Bibliometric ReviewDocument12 pagesMapping The Scienti Fic Research On Open Data: A Bibliometric ReviewJunaid AfzalNo ratings yet
- Merak Peep Ps PDFDocument2 pagesMerak Peep Ps PDFCHALABI FARESNo ratings yet
- Monisse's Research ProposalDocument17 pagesMonisse's Research ProposalQueenie Jade P. DilagNo ratings yet
- Resume Kidwell 2016Document1 pageResume Kidwell 2016api-285907048No ratings yet
- A Premarital Assessment ProgramDocument9 pagesA Premarital Assessment ProgramMuqadas FatimaNo ratings yet
- Conducive Classroom Environment in Schools: Anjali SinghDocument6 pagesConducive Classroom Environment in Schools: Anjali SinghStephany Ann B. SagueNo ratings yet
- Daniel Kahneman - The Riddle of Experience vs. MemoryDocument5 pagesDaniel Kahneman - The Riddle of Experience vs. MemorygiovrosyNo ratings yet
- Researchthesis Luke PrangerDocument44 pagesResearchthesis Luke Prangerapi-583789375No ratings yet
- Exercise 1: STATISTISCS 30001 - CLASSES 15/21Document7 pagesExercise 1: STATISTISCS 30001 - CLASSES 15/21Reyansh SharmaNo ratings yet
- Practical Research 1: Cleve V Arguelles and Luisito Cagandahan AbuegDocument8 pagesPractical Research 1: Cleve V Arguelles and Luisito Cagandahan AbuegKenjin CaponponNo ratings yet
- PHD Thesis MonographDocument8 pagesPHD Thesis Monographafloziubadtypc100% (2)
- BSMM-8320 Course Outline - Section - 2Document8 pagesBSMM-8320 Course Outline - Section - 2HibibiNo ratings yet
- March 2022 E Book 1Document17 pagesMarch 2022 E Book 1Sameer NaikNo ratings yet