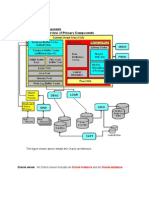
Download as pdf or txt
You might also like
- Creating Cross Platform C Applications With Uno 1801078491 9781801078498 CompressDocument258 pagesCreating Cross Platform C Applications With Uno 1801078491 9781801078498 Compresscan ipek100% (1)
- Performance Optimization in BODSDocument67 pagesPerformance Optimization in BODSisskumar67% (3)
- Manual MODBUS TCP BrabenderDocument7 pagesManual MODBUS TCP BrabenderotavioalcaldeNo ratings yet
- ITSI-4.7.1-Administration ManualDocument353 pagesITSI-4.7.1-Administration ManualLu PhamNo ratings yet
- Database TuningDocument16 pagesDatabase Tuningbstarsgamer34No ratings yet
- 38 - 7 PDF - ES 7.0.2 InstallDocument1 page38 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- Incremental AggregationDocument2 pagesIncremental AggregationgandhidasanNo ratings yet
- CachingDocument7 pagesCachingnikkusonikNo ratings yet
- SAP BW Performance OptimizationDocument11 pagesSAP BW Performance OptimizationHemanth JanyavulaNo ratings yet
- Peoplesoft Data Archival ConfiurationDocument12 pagesPeoplesoft Data Archival ConfiurationBobby YaNo ratings yet
- Performance Tuning Addedinfo OracleDocument49 pagesPerformance Tuning Addedinfo OraclesridkasNo ratings yet
- DatabricksDocument4 pagesDatabricks2041020004.smrutitanayaNo ratings yet
- Database - DesignDocument9 pagesDatabase - Designkushagra.striveNo ratings yet
- Saphelp DAP ContentDocument4 pagesSaphelp DAP ContentMadhav BajjuNo ratings yet
- Interview QuestionsDocument29 pagesInterview QuestionsSreenivasulu Reddy SanamNo ratings yet
- Performance Enhancements in Oracle9iDocument4 pagesPerformance Enhancements in Oracle9iAbhideb BhattacharyaNo ratings yet
- (24 Aug) Mengenal Data Pipeline Untuk Proses Kerja Yang EfisienDocument5 pages(24 Aug) Mengenal Data Pipeline Untuk Proses Kerja Yang EfisienSyirin ShahabNo ratings yet
- SnowflakeDocument16 pagesSnowflakekarangole7074No ratings yet
- 1.physical Storage of DatabasesDocument2 pages1.physical Storage of Databasesjosephowino13101No ratings yet
- Chapter 3. Configuring Data Protection For SQLDocument7 pagesChapter 3. Configuring Data Protection For SQLjeetmajum007No ratings yet
- Oracle Database Utilities Data Pump BP 2019Document9 pagesOracle Database Utilities Data Pump BP 2019Harish NaikNo ratings yet
- Odiess Getting StartedDocument44 pagesOdiess Getting StartedAhamed Shafraz RaufNo ratings yet
- Planning Performance Admin GuideDocument4 pagesPlanning Performance Admin GuidedmdunlapNo ratings yet
- Data Archiving in Enterprise Controlling (EC)Document16 pagesData Archiving in Enterprise Controlling (EC)sf69vNo ratings yet
- Informatica Power Center Best PracticesDocument8 pagesInformatica Power Center Best Practicesrishabh_200No ratings yet
- Paper Infa Optimization PravinDocument14 pagesPaper Infa Optimization PravinBhaskar ReddyNo ratings yet
- Query OptimizationDocument24 pagesQuery OptimizationTaxiNo ratings yet
- SQL DB Toc Fromms01Document85 pagesSQL DB Toc Fromms01Pipe CastilloNo ratings yet
- Azure DatalakeDocument8 pagesAzure DatalakeRahaman AbdulNo ratings yet
- Optimizing Lookup Transformations: Using Optimal Database DriversDocument4 pagesOptimizing Lookup Transformations: Using Optimal Database Driverssiva5256No ratings yet
- Backup Script DocumentationDocument16 pagesBackup Script Documentationmenuselect0% (1)
- Managing Memory in SASDocument17 pagesManaging Memory in SASboggalaNo ratings yet
- SAP BPC Script LogicDocument8 pagesSAP BPC Script LogicsekhardattaNo ratings yet
- PerformanceDocument2 pagesPerformanceShrishaila ShettyNo ratings yet
- Customizing End-To-End SQL Server Monitoring in Solution Manger 7.1Document9 pagesCustomizing End-To-End SQL Server Monitoring in Solution Manger 7.1l3uoNo ratings yet
- Multidimensional AnalysisDocument6 pagesMultidimensional AnalysisR SreenuNo ratings yet
- What Is Dynamic SGADocument5 pagesWhat Is Dynamic SGANadiaNo ratings yet
- Blueprint of Hana SapDocument4 pagesBlueprint of Hana SapHemanth DesettyNo ratings yet
- StatspackDocument12 pagesStatspackbalajismithNo ratings yet
- Splunk IndexesDocument8 pagesSplunk IndexeslilianetazoNo ratings yet
- How To Improve Performance of Sap Bods JobsDocument2 pagesHow To Improve Performance of Sap Bods JobssatishNo ratings yet
- Essbase Aso BsoDocument18 pagesEssbase Aso BsoJitendra KumarNo ratings yet
- DP 203 ExamTopicsDocument47 pagesDP 203 ExamTopicsNacho MullenNo ratings yet
- OraasfsaDocument199 pagesOraasfsabanala.kalyanNo ratings yet
- Esb New FeaturesDocument16 pagesEsb New Featurespuli_prasanna21No ratings yet
- Gathers Schema StatsDocument30 pagesGathers Schema StatsSiddharth ChopraNo ratings yet
- Optimization in EssbaseDocument6 pagesOptimization in EssbaseparmitchoudhuryNo ratings yet
- Oracle ArchitectureDocument102 pagesOracle ArchitecturemanavalanmichaleNo ratings yet
- Oracle Instance ArchitectureDocument28 pagesOracle Instance ArchitecturemonsonNo ratings yet
- What Are The Best Mapping Development Practices and What Are The Different Mapping Design Tips For Informatica?Document29 pagesWhat Are The Best Mapping Development Practices and What Are The Different Mapping Design Tips For Informatica?Prudhvinadh KopparapuNo ratings yet
- A Performance TunningDocument7 pagesA Performance TunningSandéêp DägärNo ratings yet
- IM Ch11 DB Performance Tuning Ed12Document17 pagesIM Ch11 DB Performance Tuning Ed12MohsinNo ratings yet
- Attach Detach Procedure SystemDocument6 pagesAttach Detach Procedure SystemVaibhav GoreNo ratings yet
- Data Archiving With Archive Development Kit (ADK)Document87 pagesData Archiving With Archive Development Kit (ADK)Jesus0% (1)
- APO SNP - Administrative Data - 01Document13 pagesAPO SNP - Administrative Data - 01Mayank AgrawalNo ratings yet
- Taking InterviwDocument15 pagesTaking InterviwA MISHRANo ratings yet
- BPC Currency ConversionDocument23 pagesBPC Currency Conversionsuryapadhi_661715971100% (1)
- Gather Schema Statistics in R12Document30 pagesGather Schema Statistics in R12srinivasNo ratings yet
- Oracle 11g New Tuning Features: Donald K. BurlesonDocument36 pagesOracle 11g New Tuning Features: Donald K. BurlesonSreekar PamuNo ratings yet
- Azure Data FactoryDocument21 pagesAzure Data Factorycloudtraining2023No ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
- 38 - 7 PDF - ES 7.0.2 InstallDocument1 page38 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 34 - 7 PDF - ES 7.0.2 InstallDocument1 page34 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 26 - 7 PDF - ES 7.0.2 InstallDocument1 page26 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 30 - 7 PDF - ES 7.0.2 InstallDocument1 page30 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 22 - 7 PDF - ES 7.0.2 InstallDocument1 page22 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 18 - 7 PDF - ES 7.0.2 InstallDocument1 page18 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 14 - 7 PDF - ES 7.0.2 InstallDocument1 page14 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 8 - 7 PDF - ES 7.0.2 InstallDocument1 page8 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 32 - 7 PDF - ES 7.0.2 InstallDocument1 page32 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 20 - 7 PDF - ES 7.0.2 InstallDocument1 page20 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 16 - 7 PDF - ES 7.0.2 InstallDocument1 page16 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- Splunk Enterprise Security Part1Document1 pageSplunk Enterprise Security Part1hjmclddgbolrlsxbknNo ratings yet
- 6 - 7 PDF - ES 7.0.2 InstallDocument1 page6 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 24 - 7 PDF - ES 7.0.2 InstallDocument1 page24 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 12 - 7 PDF - ES 7.0.2 InstallDocument1 page12 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- 10 - 7 PDF - ES 7.0.2 InstallDocument1 page10 - 7 PDF - ES 7.0.2 InstallhjmclddgbolrlsxbknNo ratings yet
- Datasheet Axis q6075 e PTZ Network Camera en US 388275Document3 pagesDatasheet Axis q6075 e PTZ Network Camera en US 388275aceel fitchNo ratings yet
- 840 DiDocument8 pages840 Diwouter NeirynckNo ratings yet
- Shallow Parsing: Natural Language ProcessingDocument32 pagesShallow Parsing: Natural Language ProcessingAjit SinghNo ratings yet
- UNIT III Introduction To MicrocontrollerDocument118 pagesUNIT III Introduction To MicrocontrollerM VENKATA GANESHNo ratings yet
- Aws Cli PDFDocument94 pagesAws Cli PDFVinu3012No ratings yet
- UntitledDocument85 pagesUntitledFitzpatrick CunananNo ratings yet
- Okk VM-750-960-1260Document16 pagesOkk VM-750-960-1260ChutchawanNo ratings yet
- Editing Systems: Epub (Short For Electronic Publication Alternatively Capitalized As Epub, Epub, Epub, or Epub, WithDocument1 pageEditing Systems: Epub (Short For Electronic Publication Alternatively Capitalized As Epub, Epub, Epub, or Epub, WithPxNo ratings yet
- Data Communicationsch06Document49 pagesData Communicationsch06Prince kumarNo ratings yet
- How To Make Ubuntu Look Like Mac OS VenturaDocument5 pagesHow To Make Ubuntu Look Like Mac OS VenturaDavorin JurišićNo ratings yet
- AWS Certified Solution Architect Associate Study Guide V1.0 Abdul Jaseem VP Release 30 Aug 2020Document235 pagesAWS Certified Solution Architect Associate Study Guide V1.0 Abdul Jaseem VP Release 30 Aug 2020panablues100% (2)
- Cost Function For Logistic RegressionDocument42 pagesCost Function For Logistic RegressionSwapnil BeraNo ratings yet
- Cyclone V Device Handbook Volume 3 Hard Processor System Technical Reference Manual PDFDocument670 pagesCyclone V Device Handbook Volume 3 Hard Processor System Technical Reference Manual PDFMaximiliano NietoNo ratings yet
- IEEE Project Titles 2020Document293 pagesIEEE Project Titles 2020aslanNo ratings yet
- POS - EDC v1.1 UPDATEDocument88 pagesPOS - EDC v1.1 UPDATEseptian fajarNo ratings yet
- Under The Guidance of DR Manohar M: O.Rushikesavareddy-1860340Document16 pagesUnder The Guidance of DR Manohar M: O.Rushikesavareddy-1860340naveen kumar reddy sontireddyNo ratings yet
- Irjet V8i9226Document8 pagesIrjet V8i9226AleNo ratings yet
- Social CRM As A Business StrategyDocument16 pagesSocial CRM As A Business StrategyankitNo ratings yet
- Formes 3D Et Trimesh - Documentation Py5Document13 pagesFormes 3D Et Trimesh - Documentation Py5Edmonico VelonjaraNo ratings yet
- Installation Guide: AP650 Access PointDocument36 pagesInstallation Guide: AP650 Access Pointholman javier perillaNo ratings yet
- Cobra ODE Installation Manual (English) v1.4Document49 pagesCobra ODE Installation Manual (English) v1.4sasa097100% (1)
- Windows 10 With Office 2016: PM Publishers Pvt. LTDDocument176 pagesWindows 10 With Office 2016: PM Publishers Pvt. LTDSlayer God100% (1)
- TTRPG Resources 1.9Document6 pagesTTRPG Resources 1.9PeterNo ratings yet
- Test 1Document102 pagesTest 1Hữu VinhNo ratings yet
- VERIM 4-Manual PDFDocument61 pagesVERIM 4-Manual PDFTatianaPadillaNo ratings yet
- Iexpense in R12Document11 pagesIexpense in R12angra_sandeepNo ratings yet
- Q1. What Are Styles ? What Are The Advantages of Using Styles?Document4 pagesQ1. What Are Styles ? What Are The Advantages of Using Styles?979Niya Noushad50% (2)