Download as pdf or txt
You might also like
- ContentDocument12 pagesContentPrashanth ShettyNo ratings yet
- Uber - Analysis - Jupyter - NotebookDocument10 pagesUber - Analysis - Jupyter - NotebookAnurag Singh100% (1)
- Assignment 2 PDFDocument25 pagesAssignment 2 PDFBoni HalderNo ratings yet
- S7-200 Programmable Controller - Step 7 Micro WinDocument482 pagesS7-200 Programmable Controller - Step 7 Micro Winapi-3704887100% (2)
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- Sales ForecastingDocument10 pagesSales ForecastingSharath Shetty100% (1)
- Stock AnalysisDocument16 pagesStock AnalysisAbhisek KeshariNo ratings yet
- MatplotlibDocument8 pagesMatplotlibMahevish FatimaNo ratings yet
- Midas Gen: Project TitleDocument5 pagesMidas Gen: Project TitleGooddayBybsNo ratings yet
- Vineet DataanalystDocument5 pagesVineet DataanalystVineet AgarwalNo ratings yet
- Knn1 HouseVotesDocument2 pagesKnn1 HouseVotesJoe1No ratings yet
- Sunbase Data AssignmentDocument11 pagesSunbase Data Assignmentfanrock281No ratings yet
- Marvel Vs DCDocument1 pageMarvel Vs DCManoj MNo ratings yet
- PDF NotebookDocument5 pagesPDF NotebookKrunal KalariyaNo ratings yet
- HUAWEI - 05 Python ExerciseDocument5 pagesHUAWEI - 05 Python ExercisePierpaolo VergatiNo ratings yet
- Hints and AnswersDocument13 pagesHints and Answersashishamitav123No ratings yet
- ProjeDocument140 pagesProjeMurat ÖzaydınNo ratings yet
- Amazon 1677074169Document15 pagesAmazon 1677074169Disha MittalNo ratings yet
- Sklearn Tutorial: DNN On Boston DataDocument9 pagesSklearn Tutorial: DNN On Boston DatahopkeinstNo ratings yet
- PandasDocument21 pagesPandasShubham dattatray koteNo ratings yet
- Bitwise cst383 Final ProjectDocument17 pagesBitwise cst383 Final Projectapi-635181702No ratings yet
- Assignment - 1.ipynb - ColaboratoryDocument4 pagesAssignment - 1.ipynb - ColaboratoryTishbian MeshachNo ratings yet
- 017) Pandas - Batch 2 - Day 017Document47 pages017) Pandas - Batch 2 - Day 017saaraappambuNo ratings yet
- Practica 9Document24 pagesPractica 92marlenehh2003No ratings yet
- Tarea 8Document7 pagesTarea 8Marcela BernalNo ratings yet
- Database Design Concepts - June 2014Document5 pagesDatabase Design Concepts - June 2014Ashen WickremasingheNo ratings yet
- Manipulating Dataframes With Pandas: Categoricals and GroupbyDocument41 pagesManipulating Dataframes With Pandas: Categoricals and GroupbyCristian DiazNo ratings yet
- Filtering Pandas DataFramesDocument1 pageFiltering Pandas DataFramessergio vargasNo ratings yet
- K Means ClusteringDocument10 pagesK Means ClusteringWalid Sassi100% (1)
- Week 4 LABDocument26 pagesWeek 4 LABtarunbinjadagi18No ratings yet
- 02-Linear Regression Project - SolutionsDocument12 pages02-Linear Regression Project - SolutionsHellem BiersackNo ratings yet
- Trabajo EurostatDocument7 pagesTrabajo Eurostatjosedaniel.correaNo ratings yet
- Movie NotebookDocument91 pagesMovie NotebookpatNo ratings yet
- Chapter7 ScriptsDocument8 pagesChapter7 ScriptsDele Jnr EriboNo ratings yet
- Lab 3 Create DatabaseDocument5 pagesLab 3 Create DatabaseSyuhaida IeqaNo ratings yet
- CH2 Descriptive Analytics QA PDFDocument25 pagesCH2 Descriptive Analytics QA PDFgecNo ratings yet
- Practical 2 51Document5 pagesPractical 2 51Royal EmpireNo ratings yet
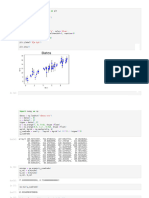
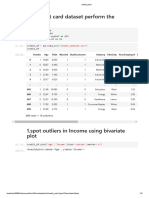
- Know Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730Document1 pageKnow Your Dataset: Season Holiday Weekday Workingday CNT 726 727 728 729 730SHANTI ROKKANo ratings yet
- 3 Creating Features - KaggleDocument14 pages3 Creating Features - KagglePrujith Muthu RamNo ratings yet
- I041 NLP Assignment5Document12 pagesI041 NLP Assignment5Devesh PawarNo ratings yet
- Patternz Screener-RT 5minsDocument1 pagePatternz Screener-RT 5minsRuhul IslamNo ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- 01 54 55Document14 pages01 54 55steven liuNo ratings yet
- Assignment 1Document4 pagesAssignment 1M SANJAYNo ratings yet
- Stock Price Prediction Project Utilizing LSTM TechniquesDocument14 pagesStock Price Prediction Project Utilizing LSTM TechniquesNisAr AhmadNo ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Patternz Screener - EODDocument1 pagePatternz Screener - EODRuhul IslamNo ratings yet
- Year End ExaminationDocument9 pagesYear End ExaminationUSHA PERUMALNo ratings yet
- The Series Data Structure: Import Pandas As PDDocument8 pagesThe Series Data Structure: Import Pandas As PDBhanu JhaNo ratings yet
- ML#07Document21 pagesML#07Kiki NhabindeNo ratings yet
- Methodes Pour DataframesDocument10 pagesMethodes Pour DataframesWalid MaheriNo ratings yet
- Ejercicio Forecast PDFDocument4 pagesEjercicio Forecast PDFJose MariaNo ratings yet
- Efficient Python Tricks and Tools For Data ScientistsDocument23 pagesEfficient Python Tricks and Tools For Data ScientistsMaheshBirajdar100% (1)
- Airfare ML - Predicting Flight FaresDocument21 pagesAirfare ML - Predicting Flight FaresDavid NovaNo ratings yet
- Topic 2. Visual Data Analysis in Python: Mlcourse - Ai (Https://mlcourse - Ai)Document15 pagesTopic 2. Visual Data Analysis in Python: Mlcourse - Ai (Https://mlcourse - Ai)rastamanrmNo ratings yet
- Untitled5: WarningsDocument26 pagesUntitled5: WarningsMaxi GarzonNo ratings yet
- Pandas PlotsDocument14 pagesPandas PlotsASHUTOSH TRIVEDINo ratings yet
- UntitledDocument7,985 pagesUntitledAllesteir AlfrediNo ratings yet
- Load Dataset: Import AsDocument8 pagesLoad Dataset: Import AsZESTYNo ratings yet
- Logistic Multiclass ClassificationDocument2 pagesLogistic Multiclass Classificationjaymehta1444No ratings yet
- Azan Block 1Document2 pagesAzan Block 1Maximus AranhaNo ratings yet
- IeeeDocument1 pageIeeeMaximus AranhaNo ratings yet
- Multiple Integral Cartesian PolarDocument19 pagesMultiple Integral Cartesian PolarMaximus AranhaNo ratings yet
- Announcements 1600010787Document1 pageAnnouncements 1600010787Maximus AranhaNo ratings yet
- ADocument3 pagesAMaximus AranhaNo ratings yet
- 6th Ap (Ril M, Ed Repor Wilson AACE Scanner - 2024 - 04 - 08Document1 page6th Ap (Ril M, Ed Repor Wilson AACE Scanner - 2024 - 04 - 08Maximus AranhaNo ratings yet
- CSE (DS) Scheme 2023-2024Document11 pagesCSE (DS) Scheme 2023-2024Maximus AranhaNo ratings yet
- Gamma FunctionDocument10 pagesGamma FunctionMaximus AranhaNo ratings yet
- MentorApp Golden Template AY 2022-23-1 2 Compressed 1687926099903Document28 pagesMentorApp Golden Template AY 2022-23-1 2 Compressed 1687926099903Maximus AranhaNo ratings yet
- Medical Certificate 18Document1 pageMedical Certificate 18Maximus AranhaNo ratings yet
- Cao Assignment 51.Document1 pageCao Assignment 51.Maximus AranhaNo ratings yet
- YMXzlCEuTdyGA9xnO3s2 - PRO Athlete HandbookDocument20 pagesYMXzlCEuTdyGA9xnO3s2 - PRO Athlete HandbookMaximus AranhaNo ratings yet
- U-4 Resume, Cover Letter, Job Application LetterDocument3 pagesU-4 Resume, Cover Letter, Job Application LetterMaximus AranhaNo ratings yet
- AbDocument13 pagesAbMaximus AranhaNo ratings yet
- CSEDs Maximus 51Document2 pagesCSEDs Maximus 51Maximus AranhaNo ratings yet
- Checked DCFM PractDocument10 pagesChecked DCFM PractMaximus AranhaNo ratings yet
- Sec B CeDocument2 pagesSec B CeMaximus AranhaNo ratings yet
- Class 11 - Introduction To Data StructuresDocument50 pagesClass 11 - Introduction To Data StructuresMaximus AranhaNo ratings yet
- Fy - Cse (DS)Document5 pagesFy - Cse (DS)Maximus AranhaNo ratings yet
- Class 16 - Doubly Linked ListDocument15 pagesClass 16 - Doubly Linked ListMaximus AranhaNo ratings yet
- Class 12 - Sorting AlgorithmsDocument54 pagesClass 12 - Sorting AlgorithmsMaximus AranhaNo ratings yet
- Class 13 - StackDocument16 pagesClass 13 - StackMaximus AranhaNo ratings yet
- TSA 9 Week Intermediate ProgramDocument20 pagesTSA 9 Week Intermediate ProgramMaximus AranhaNo ratings yet
- Sylvesters TheoremDocument3 pagesSylvesters TheoremMaximus AranhaNo ratings yet
- Nabil 201 Chap 06Document37 pagesNabil 201 Chap 06Maximus AranhaNo ratings yet
- Attendance Below 75%Document1 pageAttendance Below 75%Maximus AranhaNo ratings yet
- Properties of Eigen ValuesDocument1 pageProperties of Eigen ValuesMaximus AranhaNo ratings yet
- 4Document6 pages4Maximus AranhaNo ratings yet
- ClickHouse Cloud Live - Feb 8 2024Document55 pagesClickHouse Cloud Live - Feb 8 2024avilancheeNo ratings yet
- Lab 2 Tutorial PDFDocument16 pagesLab 2 Tutorial PDFasdNo ratings yet
- Peripherals and InterfacesDocument42 pagesPeripherals and InterfacesImran AbbasNo ratings yet
- Eve Cook Book 1.0Document197 pagesEve Cook Book 1.0msamuelfNo ratings yet
- Presentation 1Document9 pagesPresentation 1421243No ratings yet
- NVRAM Initialization: CautionDocument1 pageNVRAM Initialization: CautionDaniel LopezNo ratings yet
- SR 92Document18 pagesSR 92Harshith Gowda RNo ratings yet
- Programacion PLC51Document69 pagesProgramacion PLC51erickkelvinNo ratings yet
- Lecture 1 (IoT)Document26 pagesLecture 1 (IoT)Dilawaz MemonNo ratings yet
- Apache Is Not Running From XAMPP Control Panel - Stack OverflowDocument4 pagesApache Is Not Running From XAMPP Control Panel - Stack OverflowkokoberiNo ratings yet
- Kubernetes SecurityDocument34 pagesKubernetes SecurityAmit SharmaNo ratings yet
- Efficient Pattern Matching Algorithm For Memory ArchitectureDocument9 pagesEfficient Pattern Matching Algorithm For Memory ArchitecturevamsiNo ratings yet
- 9.2.1.3 Lab - Designing and Implementing A Subnetted IPv4 Addressing SchemeDocument7 pages9.2.1.3 Lab - Designing and Implementing A Subnetted IPv4 Addressing Schemeamimul137480% (2)
- Amazon DynamoDB vs. Elasticsearch ComparisonDocument4 pagesAmazon DynamoDB vs. Elasticsearch ComparisonNilesh KumarNo ratings yet
- Student Guidelines For Respondus Proctoring SoftwareDocument6 pagesStudent Guidelines For Respondus Proctoring SoftwareNevin TomNo ratings yet
- Ec m2035dn PN m2035dn L m2535dn L Entb1ladr1Document15 pagesEc m2035dn PN m2035dn L m2535dn L Entb1ladr1Luis Santi Herrera SanandresNo ratings yet
- Receipt Printer Install InstructionsDocument10 pagesReceipt Printer Install InstructionsLin MaceNo ratings yet
- Mscit Syllabus 08 09Document30 pagesMscit Syllabus 08 09visalatchi2No ratings yet
- 2017 - InTouch - ModernAppGuideDocument40 pages2017 - InTouch - ModernAppGuideefNo ratings yet
- Samsung's New Midrange Galaxy A55 Arrives With Improved Security and MaterialDocument4 pagesSamsung's New Midrange Galaxy A55 Arrives With Improved Security and Materialremo meinNo ratings yet
- OCFS2: The Oracle Clustered File System, Version 2Document13 pagesOCFS2: The Oracle Clustered File System, Version 2loroowNo ratings yet
- Wincc Da ServerDocument96 pagesWincc Da ServerEngr. Nabeel Ahmad KhanNo ratings yet
- Enum and ConstantsDocument6 pagesEnum and ConstantsJobin SebastianNo ratings yet
- VSS - Virtual Switching Systems: ContentDocument10 pagesVSS - Virtual Switching Systems: ContentVeeji SwamyNo ratings yet
- CP2000 Oper EmergencialDocument9 pagesCP2000 Oper Emergencialgl.automacaoNo ratings yet
- Quote Everything': Burning - Shearing - Sawing - DrillingDocument6 pagesQuote Everything': Burning - Shearing - Sawing - DrillingJimmy MyNo ratings yet
- Question On DatatypesDocument47 pagesQuestion On Datatypesvishal kumarNo ratings yet
- Avoid Food Waste 14.03.2019Document31 pagesAvoid Food Waste 14.03.2019Marimuthu Murugan80% (5)
- TDS-V8 Modbus Instruction Manual PDFDocument22 pagesTDS-V8 Modbus Instruction Manual PDFAlejandro DallosNo ratings yet