Download as docx, pdf, or txt
You might also like
- Reading Comprehension Using Story GrammarDocument4 pagesReading Comprehension Using Story GrammarSharlene Williams100% (1)
- Statistics and Correlation Answer KeyDocument4 pagesStatistics and Correlation Answer KeycharlottedwnNo ratings yet
- AR& Inventory Management AR& Inventory ManagementDocument11 pagesAR& Inventory Management AR& Inventory Managementchesca marie penarandaNo ratings yet
- Data Analysis: Descriptive StatisticsDocument8 pagesData Analysis: Descriptive StatisticsRajja RashadNo ratings yet
- Statistical Parameters: Measures of Central Tendency and VariationDocument23 pagesStatistical Parameters: Measures of Central Tendency and VariationAnonymous 3RT8ZRkPNaNo ratings yet
- MMW Managing DataDocument3 pagesMMW Managing Datashalala16763118No ratings yet
- Statistical Measures&Correlation&It'STypesDocument4 pagesStatistical Measures&Correlation&It'STypesMeenakshi RajputNo ratings yet
- Statistics NotesDocument46 pagesStatistics Noteshsrinivas_7No ratings yet
- Statistics A Gentle Introduction CH - 3Document23 pagesStatistics A Gentle Introduction CH - 3abdal113100% (2)
- Descriptive Statistics MBADocument7 pagesDescriptive Statistics MBAKritika Jaiswal100% (2)
- Unit-2-Business Statistics-Desc StatDocument26 pagesUnit-2-Business Statistics-Desc StatDeepa SelvamNo ratings yet
- Week 13 Central Tendency For Ungrouped DataDocument27 pagesWeek 13 Central Tendency For Ungrouped Datablesstongga2002No ratings yet
- Unit-3 DS StudentsDocument35 pagesUnit-3 DS StudentsHarpreet Singh BaggaNo ratings yet
- Measures of Central TendencyDocument4 pagesMeasures of Central TendencydeepikaajhaNo ratings yet
- Introduction To StatisticsDocument21 pagesIntroduction To Statisticsmayur shettyNo ratings yet
- What Is Central TendencyDocument10 pagesWhat Is Central Tendencycarmela ventanillaNo ratings yet
- Chapter 3 Statistical ParametersDocument22 pagesChapter 3 Statistical ParametersJosé Juan Góngora CortésNo ratings yet
- Descriptive StatisticsDocument4 pagesDescriptive StatisticsRaghad Al QweeflNo ratings yet
- Further Bound ReferenceDocument42 pagesFurther Bound ReferenceEmily LeeNo ratings yet
- Ecs NotesDocument10 pagesEcs Notes55389740No ratings yet
- AP Statistics Study GuideDocument87 pagesAP Statistics Study GuideLoren ChilesNo ratings yet
- Stat VivaDocument10 pagesStat VivaTanjima MahjabinNo ratings yet
- Interpretation of Data Topic: World Cup 2016 Subject: Business Analytics Assignment No 1Document3 pagesInterpretation of Data Topic: World Cup 2016 Subject: Business Analytics Assignment No 1daniyal shaikhNo ratings yet
- Data Analysis Chp9 RMDocument9 pagesData Analysis Chp9 RMnikjadhavNo ratings yet
- Descriptive StatisticsDocument6 pagesDescriptive StatisticsmicahatiensaNo ratings yet
- Measures of Central TendencyDocument6 pagesMeasures of Central TendencyBridget Anne BenitezNo ratings yet
- Mathematics in The Modern WorldDocument13 pagesMathematics in The Modern WorldMary Ann Lastrilla GratuitoNo ratings yet
- Measure of Central TendencyDocument25 pagesMeasure of Central Tendencykinhai_seeNo ratings yet
- AssignmentDocument23 pagesAssignmentLadymae Barneso SamalNo ratings yet
- AssignmentDocument30 pagesAssignmentLadymae Barneso SamalNo ratings yet
- Normal DistributionsDocument11 pagesNormal DistributionsWaseem Javaid SoomroNo ratings yet
- MachineryDocument9 pagesMachineryAditya KumarNo ratings yet
- Stats 3Document12 pagesStats 3Marianne Christie RagayNo ratings yet
- Measures of Central TendencyDocument48 pagesMeasures of Central TendencySheila Mae Guad100% (1)
- Bocalig Act5 MMWDocument6 pagesBocalig Act5 MMWfeaalma.bocaligNo ratings yet
- Module 6 Measures of Central TendencyDocument7 pagesModule 6 Measures of Central TendencyAlayka Mae Bandales LorzanoNo ratings yet
- What Is Descriptive StatisticsDocument6 pagesWhat Is Descriptive StatisticsmunaNo ratings yet
- Stat Chapter 5-9Document32 pagesStat Chapter 5-9asratNo ratings yet
- Statistical Machine LearningDocument12 pagesStatistical Machine LearningDeva Hema100% (1)
- Assignment StatsDocument9 pagesAssignment StatsMishamkhanNo ratings yet
- CH 2Document15 pagesCH 2kumarveeru1268No ratings yet
- Statistical and Probability Tools For Cost EngineeringDocument16 pagesStatistical and Probability Tools For Cost EngineeringAhmed AbdulshafiNo ratings yet
- Edu 208 PDFDocument1 pageEdu 208 PDFmoretzchloe174No ratings yet
- Exploratory Data AnalysisDocument106 pagesExploratory Data AnalysisAbhi Giri100% (1)
- Statistics Is The Study of The Collection, Organization, Analysis, Interpretation, andDocument18 pagesStatistics Is The Study of The Collection, Organization, Analysis, Interpretation, andLyn EscanoNo ratings yet
- Statistics in ResearchDocument26 pagesStatistics in ResearchStevoh100% (2)
- New Microsoft Office Word DocumentDocument10 pagesNew Microsoft Office Word DocumentShafique RahmanNo ratings yet
- Desc ExcelDocument65 pagesDesc ExcelZAIRUL AMIN BIN RABIDIN (FRIM)No ratings yet
- ADDB - Week 2Document46 pagesADDB - Week 2Little ANo ratings yet
- 02 Descriptive StatisticsDocument30 pages02 Descriptive StatisticsWahyu AdilNo ratings yet
- Assignment Linear RegressionDocument10 pagesAssignment Linear RegressionBenita NasncyNo ratings yet
- Unit 1 - Business Statistics & AnalyticsDocument25 pagesUnit 1 - Business Statistics & Analyticsk89794No ratings yet
- Instructions For Chapter 3 Prepared by Dr. Guru-Gharana: Terminology and ConventionsDocument11 pagesInstructions For Chapter 3 Prepared by Dr. Guru-Gharana: Terminology and ConventionsLou RawlsNo ratings yet
- Chapter 2 Descriptive StatisticsDocument15 pagesChapter 2 Descriptive Statistics23985811100% (2)
- DSBDL Asg 3 Write UpDocument6 pagesDSBDL Asg 3 Write UpsdaradeytNo ratings yet
- Central TendencyDocument5 pagesCentral TendencyZÅîb MëýmÖñNo ratings yet
- Descriptive StatDocument13 pagesDescriptive StatJoshrel CieloNo ratings yet
- Measure of Central Tendency Dispersion ADocument8 pagesMeasure of Central Tendency Dispersion Aرؤوف الجبيريNo ratings yet
- List The Importance of Data Analysis in Daily LifeDocument6 pagesList The Importance of Data Analysis in Daily LifeKogilan Bama DavenNo ratings yet
- Measures of Central TendencyDocument8 pagesMeasures of Central TendencyNor HidayahNo ratings yet
- Essentials of Marketing Management - Brand PersonalityDocument6 pagesEssentials of Marketing Management - Brand PersonalityRini DarathyNo ratings yet
- A2 Essentials-of-Marketing DoggoWalkerDocument11 pagesA2 Essentials-of-Marketing DoggoWalkerRini DarathyNo ratings yet
- Essentials of Marketing ManagementDocument4 pagesEssentials of Marketing ManagementRini DarathyNo ratings yet
- Boons and Banes of Business StatisticsDocument1 pageBoons and Banes of Business StatisticsRini DarathyNo ratings yet
- Figurative-Language Power PointDocument39 pagesFigurative-Language Power PointAlan FlorenceNo ratings yet
- How To Counter Jihadist Appeal Among Western European MuslimsDocument4 pagesHow To Counter Jihadist Appeal Among Western European MuslimsThe Wilson CenterNo ratings yet
- TLM 6006 (Logistics and Transportation Management) Assignment Ma Wah Wah Khaing TLM - 74 (Section B)Document4 pagesTLM 6006 (Logistics and Transportation Management) Assignment Ma Wah Wah Khaing TLM - 74 (Section B)Wah KhaingNo ratings yet
- Jackson, David - Fragments - of - A - Golden - Manuscript - of - Sa - Skya Pandita Works 1991Document18 pagesJackson, David - Fragments - of - A - Golden - Manuscript - of - Sa - Skya Pandita Works 1991Bella ChaoNo ratings yet
- Potential Development of Substitute Products: Fred R. David Prentice Hall Ch.3-1Document17 pagesPotential Development of Substitute Products: Fred R. David Prentice Hall Ch.3-1Kashif ImranNo ratings yet
- 100 Best-Selling Cases: The Case For LearningDocument29 pages100 Best-Selling Cases: The Case For LearningSultan KhanNo ratings yet
- Free Cash Flow ValuationDocument46 pagesFree Cash Flow ValuationLayNo ratings yet
- Romeo and Juliet 2023 WorkbookDocument62 pagesRomeo and Juliet 2023 WorkbooklstewardNo ratings yet
- Final SW 4020 Organizational Analysis DemaraDocument21 pagesFinal SW 4020 Organizational Analysis Demaraapi-311012291No ratings yet
- AJAX Toolkit Developer Guide: Version 39.0, Spring '17Document48 pagesAJAX Toolkit Developer Guide: Version 39.0, Spring '17JagadeeshNo ratings yet
- ProvRem - DM WenceslaoDocument3 pagesProvRem - DM WenceslaoKath LimNo ratings yet
- Eth Adapter CN User ManualDocument34 pagesEth Adapter CN User Manualfahim47No ratings yet
- Grade 1 Pattern of LV Diastolic FillingDocument3 pagesGrade 1 Pattern of LV Diastolic FillingNicoleNo ratings yet
- Historical Greek Coins - Hill (1906)Document238 pagesHistorical Greek Coins - Hill (1906)Babilonia CruzNo ratings yet
- Self Worth SpeechDocument1 pageSelf Worth SpeechAbigail Fritz GoloNo ratings yet
- Place Label Below: Tmsca Middle School Number Sense Regional Test© M A R C H 2 7, 2 0 2 1Document5 pagesPlace Label Below: Tmsca Middle School Number Sense Regional Test© M A R C H 2 7, 2 0 2 1DougNo ratings yet
- RUDS Presents FAMEDocument12 pagesRUDS Presents FAMERUDSdrama0% (1)
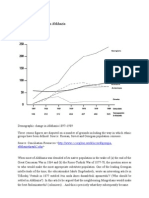
- Demographic Change in AbkhaziaDocument3 pagesDemographic Change in AbkhaziacircassianworldNo ratings yet
- Sinhala Quran Chapters 58 To 66Document66 pagesSinhala Quran Chapters 58 To 66Michael WestNo ratings yet
- Remedial Intervention For Slow Learner1Document2 pagesRemedial Intervention For Slow Learner1Stephanie FloresNo ratings yet
- Dynapac Complete Range Brochure enDocument24 pagesDynapac Complete Range Brochure enJovanka JadrovskaNo ratings yet
- Ficha de Revisao Ingles - Mar2019Document5 pagesFicha de Revisao Ingles - Mar2019anamariasmNo ratings yet
- Cap Round 2 AllotmentDocument8 pagesCap Round 2 AllotmentHarshwardhan G1No ratings yet
- A Guide To Transformer Maintenance by S D Myers J J Kelly R H Parrish 0939320002Document5 pagesA Guide To Transformer Maintenance by S D Myers J J Kelly R H Parrish 0939320002N4Y CHANNELNo ratings yet
- Designing Data Science: Rohan Raghavan Gavin SeewooruttunDocument12 pagesDesigning Data Science: Rohan Raghavan Gavin SeewooruttunNicolás Galavis VelandiaNo ratings yet
- (Maa 3.5) Sin, Cos, Tan On The Unit Circle - Identities - SolutionsDocument6 pages(Maa 3.5) Sin, Cos, Tan On The Unit Circle - Identities - Solutionsrogchen666No ratings yet
- Design Elements and PrinciplesDocument14 pagesDesign Elements and PrinciplesJaisurya SharmaNo ratings yet
- By: Jason C. SobrevegaDocument16 pagesBy: Jason C. SobrevegaJason SobrevegaNo ratings yet