Download as pdf or txt
You might also like
- Generative AI With Python and TensorFlow 2 Create Images, Text, and Music With VAEs, GANs, LSTMS, Transformer Models (Joseph Babcock, Raghav Bali) (Z-Library) PDFDocument569 pagesGenerative AI With Python and TensorFlow 2 Create Images, Text, and Music With VAEs, GANs, LSTMS, Transformer Models (Joseph Babcock, Raghav Bali) (Z-Library) PDFDeepak prasadNo ratings yet
- Dynamic PMSM ModellingDocument24 pagesDynamic PMSM Modellingdirekap280No ratings yet
- Restricted Boltzmann Machines: AbstractDocument21 pagesRestricted Boltzmann Machines: AbstractNasreenNo ratings yet
- تقرير تحليلاتDocument6 pagesتقرير تحليلاتAreej AdeebNo ratings yet
- RTRBMDocument8 pagesRTRBMMoshe AlonsoNo ratings yet
- BM Pars TacsDocument13 pagesBM Pars TacsJ Luis MlsNo ratings yet
- MATLAB Vibración Armónica LibreDocument27 pagesMATLAB Vibración Armónica Librenicole larrereNo ratings yet
- 3PS - Test 2 - 2021 - QuestionDocument2 pages3PS - Test 2 - 2021 - QuestionMandlenkosi GumedeNo ratings yet
- Grid Synchronization Method Based On A Quasi-Ideal Low-Pass Filter Stage and A Phase-Locked LoopDocument6 pagesGrid Synchronization Method Based On A Quasi-Ideal Low-Pass Filter Stage and A Phase-Locked LoopEdsonNo ratings yet
- Amm 303-306 1706Document5 pagesAmm 303-306 1706Ahmed MohsenNo ratings yet
- Final 6711 F07 SolsDocument4 pagesFinal 6711 F07 SolsSongya PanNo ratings yet
- Design of An Audio Amplifier2Document14 pagesDesign of An Audio Amplifier2Catalina DragomirNo ratings yet
- Mccdma Vs OwssDocument5 pagesMccdma Vs OwssnemsrajbhandariNo ratings yet
- Ortho TRX LineDocument16 pagesOrtho TRX LineAliOucharNo ratings yet
- The Discrete-Time Bounded-Real Lemma in Digital FilteringDocument7 pagesThe Discrete-Time Bounded-Real Lemma in Digital FilteringGabriela AlvaradoNo ratings yet
- Lab 3-CS-LabDocument12 pagesLab 3-CS-Labهاشمی دانشNo ratings yet
- EEE 309 Communication Systems I: Dr. Md. Forkan Uddin Associate Professor Dept. of EEE, BUET, Dhaka 1205Document35 pagesEEE 309 Communication Systems I: Dr. Md. Forkan Uddin Associate Professor Dept. of EEE, BUET, Dhaka 1205Raihan AliNo ratings yet
- ns3-TR UniversityOfWashingtonDocument20 pagesns3-TR UniversityOfWashingtonyuliar yuliarNo ratings yet
- Adaptive Nonlinear Control of A Ball and Beam System Using The Centrifugal Force TerDocument11 pagesAdaptive Nonlinear Control of A Ball and Beam System Using The Centrifugal Force TerdiegoNo ratings yet
- Communication Systems 3Document42 pagesCommunication Systems 3Zain AhmedNo ratings yet
- Generation: of Nakagami-M Fading ChannelsDocument6 pagesGeneration: of Nakagami-M Fading ChannelsSourav DebnathNo ratings yet
- Permanent Magnet Linear Synchronous Motor (PM LSM) : Dr. M. El-Nemr Faculty of Engineering-Tanta University, EgyptDocument7 pagesPermanent Magnet Linear Synchronous Motor (PM LSM) : Dr. M. El-Nemr Faculty of Engineering-Tanta University, EgyptMohamed NafeaNo ratings yet
- Communication SystemsDocument42 pagesCommunication Systemstalha4400573No ratings yet
- Communication SystemsDocument53 pagesCommunication SystemsKinza MallickNo ratings yet
- CS 224D: Deep Learning For NLP: Lecture Notes: Part IV Spring 2015Document12 pagesCS 224D: Deep Learning For NLP: Lecture Notes: Part IV Spring 2015Kumar JNo ratings yet
- Research On SVPWM OkDocument6 pagesResearch On SVPWM OkAnonymous 1D3dCWNcNo ratings yet
- Direct Semi-Blind MMSE Equalization For Space Time Block Coding SystemsDocument11 pagesDirect Semi-Blind MMSE Equalization For Space Time Block Coding SystemsdhullparveenNo ratings yet
- Capacitor Voltage BalancingDocument7 pagesCapacitor Voltage Balancingbipul ahmedNo ratings yet
- Deep Learning ModelsDocument21 pagesDeep Learning Modelssajid8887570788No ratings yet
- Ultra Reliable Communication in B5G Mmwave Networks Risk Beam Alignment GameDocument2 pagesUltra Reliable Communication in B5G Mmwave Networks Risk Beam Alignment GameElaouni AbdessamadNo ratings yet
- Analyzing Static Noise Margin For Sub-Threshold SRAM in 65nm CMOSDocument4 pagesAnalyzing Static Noise Margin For Sub-Threshold SRAM in 65nm CMOSBhavana ChaurasiaNo ratings yet
- Transmission Lines PDFDocument44 pagesTransmission Lines PDFkajariNo ratings yet
- NeurIPS 2021 Probabilistic Transformer For Time Series Analysis PaperDocument17 pagesNeurIPS 2021 Probabilistic Transformer For Time Series Analysis PaperĐức PhúNo ratings yet
- Conceptual Models of HTS Levitation and Linear Propulsion SystemDocument5 pagesConceptual Models of HTS Levitation and Linear Propulsion SystemJulioNo ratings yet
- Lecture 09Document7 pagesLecture 09Dr. Rami HalloushNo ratings yet
- Parameter and Spectrum EstimationDocument10 pagesParameter and Spectrum Estimationhu jackNo ratings yet
- Chapter 3. The Lorentz System - Paul TobinDocument55 pagesChapter 3. The Lorentz System - Paul TobinN DNo ratings yet
- ECE 461: Digital Communication Lecture 8b: Pulse Shaping and SamplingDocument9 pagesECE 461: Digital Communication Lecture 8b: Pulse Shaping and SamplingShounak DasguptaNo ratings yet
- Lecture 5&6Document24 pagesLecture 5&6elneelNo ratings yet
- Modal AnalysisDocument14 pagesModal Analysismichael_r_reid652No ratings yet
- Week 3 Dimensional AnalysisDocument19 pagesWeek 3 Dimensional AnalysisRenzNo ratings yet
- FHMM MLDocument31 pagesFHMM MLHeru PraptonoNo ratings yet
- Optimal Chebyshev Multisection Maching Transformer Design in Wipl-DDocument13 pagesOptimal Chebyshev Multisection Maching Transformer Design in Wipl-DYURLEY ACEVEDO PEREZNo ratings yet
- Chapter 2Document10 pagesChapter 2mani kandanNo ratings yet
- Pipelining and Parallel ProcessingDocument16 pagesPipelining and Parallel ProcessingBilgaNo ratings yet
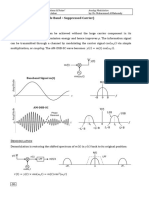
- 3.2.2 DSB-SC (Double Side Band - Suppressed Carrier) : OdulationDocument4 pages3.2.2 DSB-SC (Double Side Band - Suppressed Carrier) : Odulationprojects allNo ratings yet
- 73 483 2 PBDocument10 pages73 483 2 PBKundan karnNo ratings yet
- The Direct-Quadrature-Zero (DQ0) Transformation: Yoash Levron Juri BelikovDocument21 pagesThe Direct-Quadrature-Zero (DQ0) Transformation: Yoash Levron Juri BelikovSani1248No ratings yet
- Lab 3. Spectral Analysis in Matlab - Part IILab 3. Spectral Analysis in Matlab - Part IIDocument12 pagesLab 3. Spectral Analysis in Matlab - Part IILab 3. Spectral Analysis in Matlab - Part IIvilukNo ratings yet
- Analysis of Capacitively Coupled Microstrip-Ring Resonator Based On Spectral Domain Method R. Rezaiesarlak and F. HodjatkashaniDocument9 pagesAnalysis of Capacitively Coupled Microstrip-Ring Resonator Based On Spectral Domain Method R. Rezaiesarlak and F. HodjatkashaniAhmed JavedNo ratings yet
- Simplified Space Vector PWM Algorithm For A Three Level InverterDocument8 pagesSimplified Space Vector PWM Algorithm For A Three Level InverterGanesh ChallaNo ratings yet
- M H M M F C - P: Ultiscale Idden Arkov Odels OR O Variance RedictionDocument17 pagesM H M M F C - P: Ultiscale Idden Arkov Odels OR O Variance RedictionpukkapadNo ratings yet
- 4 AnalogLogic VigodaDocument11 pages4 AnalogLogic VigodaAbdul AzizNo ratings yet
- Power Quality Improvement by Using Shunt Hybrid Active Power FilterDocument6 pagesPower Quality Improvement by Using Shunt Hybrid Active Power FilterPENUBAAKU BALAIAH EEENo ratings yet
- Ch4 Amplitude ModulationDocument55 pagesCh4 Amplitude ModulationsrijanNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Graphs with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")From EverandGraphs with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")Rating: 4 out of 5 stars4/5 (2)
- The Spectral Theory of Toeplitz Operators. (AM-99), Volume 99From EverandThe Spectral Theory of Toeplitz Operators. (AM-99), Volume 99No ratings yet
- Density Estimation Using Real NVPDocument32 pagesDensity Estimation Using Real NVPYacov LewisNo ratings yet
- Artificial Intelligence & Neural Networks Unit-5 Basics of NNDocument16 pagesArtificial Intelligence & Neural Networks Unit-5 Basics of NNMukesh50% (2)
- Expert Systems With Applications: ReviewDocument29 pagesExpert Systems With Applications: ReviewmemoNo ratings yet
- DLunit 5Document17 pagesDLunit 5EXAMCELL - H4No ratings yet
- Deep Learning Methods and Applications For Electrical Power Systems A Comprehensive ReviewDocument22 pagesDeep Learning Methods and Applications For Electrical Power Systems A Comprehensive ReviewAminaNo ratings yet
- DLT Unit 5Document27 pagesDLT Unit 5venkata rajeshNo ratings yet
- CL7204-Soft Computing TechniquesDocument13 pagesCL7204-Soft Computing TechniquesDr. A.umaraniNo ratings yet
- Restricted Boltzmann Machines (RBMS)Document13 pagesRestricted Boltzmann Machines (RBMS)groverwaliaNo ratings yet
- Why We Use Sigmoid and ReLu in RBMDocument11 pagesWhy We Use Sigmoid and ReLu in RBMankur.cse23No ratings yet
- Introduction To Boltzmann LearningDocument2 pagesIntroduction To Boltzmann LearningnvbondNo ratings yet
- Lect3 UWA PDFDocument73 pagesLect3 UWA PDFअंकित शर्माNo ratings yet
- Quantum Boltzmann MachineDocument10 pagesQuantum Boltzmann MachineLakshika RathiNo ratings yet
- A Fast Learning Algorithm For Deep Belief Nets PDFDocument208 pagesA Fast Learning Algorithm For Deep Belief Nets PDFChikalNo ratings yet
- Deep LearningDocument3 pagesDeep LearningAnu M100% (1)
- Deep Learning Interview QuestionsDocument17 pagesDeep Learning Interview QuestionsSumathi MNo ratings yet
- Unit - II: Recurrent Neural NetworkDocument75 pagesUnit - II: Recurrent Neural NetworkLovely LianaNo ratings yet
- Deep Learning Basics Lecture 8 Autoencoder & DBMDocument28 pagesDeep Learning Basics Lecture 8 Autoencoder & DBMbarisNo ratings yet
- Multimodal Emotion Recognition Using Deep Learning ArchitecturesDocument9 pagesMultimodal Emotion Recognition Using Deep Learning ArchitecturesRaja KumarNo ratings yet
- Stochastic Neural Networks v2.0c PDFDocument65 pagesStochastic Neural Networks v2.0c PDFNando93No ratings yet
- The Traveling Salesman Problem: A Neural Network PerspectiveDocument60 pagesThe Traveling Salesman Problem: A Neural Network PerspectiveWafa ElgalhoudNo ratings yet
- Taxonomy: Research Project: Thermodynamical Interpretation of (Artificial) IntelligenceDocument9 pagesTaxonomy: Research Project: Thermodynamical Interpretation of (Artificial) IntelligenceRaphaella NiemannNo ratings yet
- 13 Useful Deep Learning Interview Questions and AnswerDocument6 pages13 Useful Deep Learning Interview Questions and AnswerMD. SHAHIDUL ISLAMNo ratings yet
- Chapter 3Document57 pagesChapter 3toon townNo ratings yet
- Generative Modelling With Tensor NetworksDocument103 pagesGenerative Modelling With Tensor NetworksMartin MolnarNo ratings yet
- Word Embedding For Understanding Natural Language: A Survey: Yang Li Tao YangDocument13 pagesWord Embedding For Understanding Natural Language: A Survey: Yang Li Tao YangĐoàn Tiến ĐạtNo ratings yet
- A Survey On Deep Learning For Data-Driven Soft SensorsDocument14 pagesA Survey On Deep Learning For Data-Driven Soft SensorsHriday GoelNo ratings yet
- Full Chapter Artificial Intelligence Engines A Tutorial Introduction To The Mathematics of Deep Learning 1St Edition James Stone PDFDocument54 pagesFull Chapter Artificial Intelligence Engines A Tutorial Introduction To The Mathematics of Deep Learning 1St Edition James Stone PDFkaren.inda786100% (8)
- Session 03 - Neural NetworksDocument21 pagesSession 03 - Neural NetworksHGE05No ratings yet
- Deep Learning - Ian GoodfellowDocument789 pagesDeep Learning - Ian GoodfellowAshwinikumar PatilNo ratings yet