Download as pdf or txt
You might also like
- How To Secure PhilGEPS Certificate of RegistrationDocument2 pagesHow To Secure PhilGEPS Certificate of Registrationacheron_p91% (35)
- Sample Questions Mathematics Category 2Document8 pagesSample Questions Mathematics Category 2Rufat Asgarov100% (1)
- Assignment: Peer Assessment: Module 1 Client/Brand Analysis: Task 1Document7 pagesAssignment: Peer Assessment: Module 1 Client/Brand Analysis: Task 1MihailNo ratings yet
- Basic Mathematics MCQsDocument25 pagesBasic Mathematics MCQsanon_237089856100% (1)
- Lecture19 20 DijkstraDocument23 pagesLecture19 20 DijkstraMr. Hussain SarganaNo ratings yet
- MCQ Unit 4 PDFDocument10 pagesMCQ Unit 4 PDFपंकज काळेNo ratings yet
- UNIT 5 Dijkstra's AlgorithmDocument18 pagesUNIT 5 Dijkstra's AlgorithmTansu GangopadhyayNo ratings yet
- Dijkstra's Algorithm: Slide Courtesy: Uwash, UTDocument31 pagesDijkstra's Algorithm: Slide Courtesy: Uwash, UTAbskNo ratings yet
- (Fall14) DijkstraDocument31 pages(Fall14) DijkstraMayank SinghNo ratings yet
- Teoria de Exponentes IIDocument1 pageTeoria de Exponentes IIjanetcsjhonNo ratings yet
- Uk2 Maths f3 2020Document9 pagesUk2 Maths f3 2020anisNo ratings yet
- Mathematics Test 1 Answer KeyDocument7 pagesMathematics Test 1 Answer KeyhiNo ratings yet
- Homework #3 Solution: Department of Electrical and Computer Engineering University of Wisconsin - MadisonDocument7 pagesHomework #3 Solution: Department of Electrical and Computer Engineering University of Wisconsin - MadisonPRAKRITI SANKHLANo ratings yet
- Homework ThreeDocument4 pagesHomework ThreeAnuj JainNo ratings yet
- Model ExamDocument7 pagesModel ExamhamzaademNo ratings yet
- Calcutechniques Part2Document20 pagesCalcutechniques Part2John Archie SerranoNo ratings yet
- Pentaksiran Sumatif Akhir Tahun Tingkatan 3 2020Document14 pagesPentaksiran Sumatif Akhir Tahun Tingkatan 3 2020Sharizad Shaari100% (1)
- PART TEST-4 (JM-2022) 25-03-2022 (F22 MDP-Seniors) QPDocument11 pagesPART TEST-4 (JM-2022) 25-03-2022 (F22 MDP-Seniors) QPsunny meenuNo ratings yet
- Chap06 Test A EquationsDocument7 pagesChap06 Test A EquationsAshmita KumarNo ratings yet
- Missing Term in The FigureDocument7 pagesMissing Term in The FigureShivam GoyalNo ratings yet
- 12 Pure Maths Trial 2021Document20 pages12 Pure Maths Trial 2021t.thuktennorbuNo ratings yet
- Roots: Find The Sum of The Roots of - A. 2 B. 3 C. 4 D. 5Document19 pagesRoots: Find The Sum of The Roots of - A. 2 B. 3 C. 4 D. 5John Paul Marin ManzanoNo ratings yet
- BNB Hs. 2002 E.C 2nd Sem. (II) Model ExamDocument112 pagesBNB Hs. 2002 E.C 2nd Sem. (II) Model ExamAbex Mehon SewNo ratings yet
- Mathematics For Economics and Business 6Th Edition Jacques Test Bank Full Chapter PDFDocument27 pagesMathematics For Economics and Business 6Th Edition Jacques Test Bank Full Chapter PDFretailnyas.rjah100% (13)
- CSE20 Lecture 15 Karnaugh Maps: Professor CK Cheng CSE Dept. UC San DiegoDocument17 pagesCSE20 Lecture 15 Karnaugh Maps: Professor CK Cheng CSE Dept. UC San DiegoasifuadNo ratings yet
- FINALEXAMBDocument11 pagesFINALEXAMBElora ChungNo ratings yet
- Mathematics: C: M /D /A /L / N /P /N / B / D # 1Document28 pagesMathematics: C: M /D /A /L / N /P /N / B / D # 1Afiq AhmadNo ratings yet
- Form 3 Mathematics Chapter 1 (Indices) KSSMDocument2 pagesForm 3 Mathematics Chapter 1 (Indices) KSSMBONG TZER WEI MoeNo ratings yet
- REPASO IIIfDocument4 pagesREPASO IIIfAbel Teofano Montenegro De La PisaNo ratings yet
- SM Pei Min 2021 1 Semester Exam Junior 3 Modern MathematicsDocument15 pagesSM Pei Min 2021 1 Semester Exam Junior 3 Modern MathematicsTeng Wei KiangNo ratings yet
- 20MA101 Set 2Document10 pages20MA101 Set 2Dheeraj KumarNo ratings yet
- SinglesDocument7 pagesSinglespara yeswanthNo ratings yet
- Apllied Maths PaperDocument13 pagesApllied Maths PaperNitin BeniwalNo ratings yet
- Math Form5 Pertengahan TahunDocument7 pagesMath Form5 Pertengahan TahunMajidah NajihahNo ratings yet
- Exercise 19 - OLD EXAM, FDTDDocument6 pagesExercise 19 - OLD EXAM, FDTDTantoh RowlandNo ratings yet
- Solutions To Selected Problems and Exercises: Problem 1.5.1Document37 pagesSolutions To Selected Problems and Exercises: Problem 1.5.1hamza malikNo ratings yet
- Multiple Choice Question 1 Q.No. AnswerDocument2 pagesMultiple Choice Question 1 Q.No. Answerjames_imchNo ratings yet
- Multiple Choice Question 1 Q.No. AnswerDocument2 pagesMultiple Choice Question 1 Q.No. Answerjames_imchNo ratings yet
- Multiple Choice Question 1 Q.No. AnswerDocument2 pagesMultiple Choice Question 1 Q.No. Answerjames_imchNo ratings yet
- North Sydney Girls 2010 Year 10 Maths Yearly & SolutionsDocument20 pagesNorth Sydney Girls 2010 Year 10 Maths Yearly & Solutionszs42257156No ratings yet
- RM - Sem 3-4Document3 pagesRM - Sem 3-4Jhem MurphyNo ratings yet
- HXC2021 Trial S2Document7 pagesHXC2021 Trial S2Gurukul AcademyNo ratings yet
- Fort ST 2023 3U Trials & SolutionsDocument25 pagesFort ST 2023 3U Trials & SolutionsSophie ChenNo ratings yet
- Maths 11+ Selection (Practice Paper F: Multiple Choice)Document6 pagesMaths 11+ Selection (Practice Paper F: Multiple Choice)drkhansacademyNo ratings yet
- The Mathematical Grammar School Cup: - MathematicsDocument1 pageThe Mathematical Grammar School Cup: - MathematicsZdravko TodorovicNo ratings yet
- Jesusa Mary Jane L. - BEED 1B - LM 6Document5 pagesJesusa Mary Jane L. - BEED 1B - LM 6mary jane jesusaNo ratings yet
- PAPER 1 Selaras 3 Sem 2 2010 (Final)Document14 pagesPAPER 1 Selaras 3 Sem 2 2010 (Final)canterbury_ebay4937No ratings yet
- MAT3700 Combined Paper OctDocument11 pagesMAT3700 Combined Paper OctNhlanhla NdebeleNo ratings yet
- Test Question Math 10Document4 pagesTest Question Math 10marjorie antonioNo ratings yet
- CPT - 3 - XII IC CF - Mains Paper - 31-05-2021 - KeyDocument16 pagesCPT - 3 - XII IC CF - Mains Paper - 31-05-2021 - KeyARYAN PANDEYNo ratings yet
- GRE Sample QP 1Document28 pagesGRE Sample QP 12281228No ratings yet
- June 2016: Dipiete - Et/Cs (Current & New Scheme)Document3 pagesJune 2016: Dipiete - Et/Cs (Current & New Scheme)surajNo ratings yet
- 8 - Class INTSO Work Sheet - 1 - Exponents and PowersDocument3 pages8 - Class INTSO Work Sheet - 1 - Exponents and Powersyoutuber tanishNo ratings yet
- Math Revison Form 2Document10 pagesMath Revison Form 2Leong Pei QiNo ratings yet
- 25 11 21 Mock Exam Answer KeyDocument1 page25 11 21 Mock Exam Answer Keyepurevsuren795No ratings yet
- Aops Community 1993 Amc 12/ahsmeDocument7 pagesAops Community 1993 Amc 12/ahsmeQFDqNo ratings yet
- Sample Paper For Half Yearly Examination 2008-09 Class - Vii Subject-MathematicsDocument4 pagesSample Paper For Half Yearly Examination 2008-09 Class - Vii Subject-Mathematicssurid1467No ratings yet
- Detailed Solution of GATE-2010 in Electronics&Communication EngineeringDocument14 pagesDetailed Solution of GATE-2010 in Electronics&Communication EngineeringschndNo ratings yet
- Illuminati - 2021: Advanced Mathematics Assignment-13Document7 pagesIlluminati - 2021: Advanced Mathematics Assignment-13Anonymous tricksNo ratings yet
- WMO Practice Set MDocument4 pagesWMO Practice Set MJomar EjedioNo ratings yet
- Supervised-Unsupervised LearningDocument2 pagesSupervised-Unsupervised LearningAysun GüranNo ratings yet
- Numeric Example For PerceptronDocument6 pagesNumeric Example For PerceptronAysun GüranNo ratings yet
- Multilayer Perceptron Algorithm (MLP)Document7 pagesMultilayer Perceptron Algorithm (MLP)Aysun GüranNo ratings yet
- NaiveBayes AlgorithmDocument6 pagesNaiveBayes AlgorithmAysun GüranNo ratings yet
- Email Signature Manager Agent For Mac User GuideDocument5 pagesEmail Signature Manager Agent For Mac User GuideSteve ChungNo ratings yet
- Applications of Computers in AccountingDocument17 pagesApplications of Computers in Accountingdebashis1008100% (8)
- Consulting Specific ResumeDocument6 pagesConsulting Specific Resumeafjwduenevzdaa100% (2)
- Empowerment Technologies Lesson 3Document21 pagesEmpowerment Technologies Lesson 3Em Gongora Jr.No ratings yet
- шпор2Document13 pagesшпор2Dancho KZNo ratings yet
- ANP104 - Massive Predictive Analytics: PublicDocument33 pagesANP104 - Massive Predictive Analytics: PublicjosetxuNo ratings yet
- Zero-Day Exploit DetectionDocument2 pagesZero-Day Exploit DetectionserzhanNo ratings yet
- SAS Programming SkillsDocument19 pagesSAS Programming Skillsstevensap100% (1)
- No TitleDocument6 pagesNo Titlehwh8w6jmzsNo ratings yet
- System Integration EngineerDocument7 pagesSystem Integration EngineerAlexandraIvanNo ratings yet
- Future of Telco ReportDocument27 pagesFuture of Telco ReportMuhammad Fadhilah HanggoroNo ratings yet
- Python Data Structure-Dictionary PDFDocument12 pagesPython Data Structure-Dictionary PDFRajendra BuchadeNo ratings yet
- Intraway Symphonica FinalDocument30 pagesIntraway Symphonica Finallpqa2021No ratings yet
- Introductiontoscala 161222153627Document83 pagesIntroductiontoscala 161222153627loda lasunNo ratings yet
- ReadmeDocument3 pagesReadmeRafenNo ratings yet
- Amiga - Cultivate PC-FloppiesDocument8 pagesAmiga - Cultivate PC-FloppieszuzkaNo ratings yet
- ECDL ICDL IT Security - Syllabus - V2.0 - Sample Part-Test - MSWIN7IE10 - V1 - 0Document9 pagesECDL ICDL IT Security - Syllabus - V2.0 - Sample Part-Test - MSWIN7IE10 - V1 - 0Del NoitNo ratings yet
- 2XVDS ManualDocument226 pages2XVDS ManualNeil McKeeverNo ratings yet
- How Computer Memory Works - Ethan GabrielDocument2 pagesHow Computer Memory Works - Ethan GabrielEthan GabrielNo ratings yet
- The Total Economic Impact of Dell EMC For SapDocument20 pagesThe Total Economic Impact of Dell EMC For SapKiselevNo ratings yet
- PecougDocument114 pagesPecougRA NDYNo ratings yet
- (Win2k12R2) Securing Public Key Infrastructure (PKI)Document125 pages(Win2k12R2) Securing Public Key Infrastructure (PKI)William ChadareNo ratings yet
- Bootstrap Notes For Assignment 02Document27 pagesBootstrap Notes For Assignment 02Radey32167No ratings yet
- Reporter 9.5.1.1 ReleaseNotesDocument12 pagesReporter 9.5.1.1 ReleaseNotesRoland HoNo ratings yet
- Unit II - PerceptronDocument20 pagesUnit II - Perceptronyou • were • trolledNo ratings yet
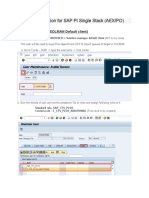
- CTS+ Configuration For SAP PI Single Stack (AEX/PO) : 1. User Creation (In SOLMAN Default Client)Document14 pagesCTS+ Configuration For SAP PI Single Stack (AEX/PO) : 1. User Creation (In SOLMAN Default Client)ramesh bandari bandariNo ratings yet
- CTR07/EVO PH Touch Panel: User Manual Release No.: Rev. 00 20/04/13 Software Version 4.06.0Document21 pagesCTR07/EVO PH Touch Panel: User Manual Release No.: Rev. 00 20/04/13 Software Version 4.06.0Goran LivancicNo ratings yet
- Testingengine: Test4Engine Test Dumps Questions - Free Test Engine Latest VersionDocument13 pagesTestingengine: Test4Engine Test Dumps Questions - Free Test Engine Latest VersionNikitaNo ratings yet