Download as pdf or txt
You might also like
- FLIPKART MayankDocument65 pagesFLIPKART MayankNeeraj DwivediNo ratings yet
- Proof of Quicksort CorrectnessDocument6 pagesProof of Quicksort Correctnessbrendan.ritterNo ratings yet
- Algorithmic Designing: Unit 1-1. Time and Space ComplexityDocument5 pagesAlgorithmic Designing: Unit 1-1. Time and Space ComplexityPratik KakaniNo ratings yet
- CS369N: Beyond Worst-Case Analysis Lecture #5: Self-Improving AlgorithmsDocument11 pagesCS369N: Beyond Worst-Case Analysis Lecture #5: Self-Improving AlgorithmsJenny JackNo ratings yet
- Sorting Lower BoundsDocument4 pagesSorting Lower BoundsTrisha NandiNo ratings yet
- SEM5 - ADA - RMSE - Questions Solution1Document58 pagesSEM5 - ADA - RMSE - Questions Solution1DevanshuNo ratings yet
- Blaeser Algorithms and Data StructuresDocument109 pagesBlaeser Algorithms and Data StructuresMaia OsadzeNo ratings yet
- 0.1 Worst and Best Case AnalysisDocument6 pages0.1 Worst and Best Case Analysisshashank dwivediNo ratings yet
- Analysis of Merge SortDocument6 pagesAnalysis of Merge Sortelectrical_hackNo ratings yet
- Basic PRAM Algorithm Design TechniquesDocument13 pagesBasic PRAM Algorithm Design TechniquessandeeproseNo ratings yet
- Lecture 5Document15 pagesLecture 5AbdurroufNo ratings yet
- Mca-4 MC0080 IDocument15 pagesMca-4 MC0080 ISriram ChakrapaniNo ratings yet
- Michelle Bodnar, Andrew Lohr May 5, 2017Document11 pagesMichelle Bodnar, Andrew Lohr May 5, 2017Mm AANo ratings yet
- CS 70 Discrete Mathematics For CS Fall 2003 Wagner Divide-and-Conquer and MergesortDocument4 pagesCS 70 Discrete Mathematics For CS Fall 2003 Wagner Divide-and-Conquer and MergesortmkysonyNo ratings yet
- Probabilistic Analysis and Randomized Quicksort: T T (I) T T (I)Document7 pagesProbabilistic Analysis and Randomized Quicksort: T T (I) T T (I)Sangeeta JainNo ratings yet
- Doa Pvy Mid Sem Imp QueDocument5 pagesDoa Pvy Mid Sem Imp QueNancy KumariNo ratings yet
- 15-852 Randomized Algorithms: Homework # 2 Due: Feb 10, 1997Document2 pages15-852 Randomized Algorithms: Homework # 2 Due: Feb 10, 1997Ramchandran MuthukumarNo ratings yet
- Lecture 3 1Document34 pagesLecture 3 1hallertjohnNo ratings yet
- Construction of RDocument11 pagesConstruction of RdeviiserNo ratings yet
- Space and Time Trade OffDocument8 pagesSpace and Time Trade OffSheshnath HadbeNo ratings yet
- Assissgment - 2 Topic:: Google'S Mehanicsim For Ranking Web Pages AimDocument7 pagesAssissgment - 2 Topic:: Google'S Mehanicsim For Ranking Web Pages AimBOGGARAPU KUSHALKUMAR 15MIS0446No ratings yet
- Guide To Divide-and-Conquer: A Sample Problem: Finding The Non-DuplicateDocument4 pagesGuide To Divide-and-Conquer: A Sample Problem: Finding The Non-DuplicateAlvaro SouzaNo ratings yet
- Daa AnswersDocument9 pagesDaa AnswersLovely ChinnaNo ratings yet
- Dictionar Matematic de Fraze Uzuale R-EDocument91 pagesDictionar Matematic de Fraze Uzuale R-EAlina Maria MiuNo ratings yet
- Advanced Algorithm Lab: Paper Code:-Pgse-292Document16 pagesAdvanced Algorithm Lab: Paper Code:-Pgse-292Promit MohantaNo ratings yet
- Quick Sort Lomu ToDocument4 pagesQuick Sort Lomu ToJesus Moran PerezNo ratings yet
- Unit 2 NotesDocument45 pagesUnit 2 NotesB2No ratings yet
- Shell Sort MitDocument18 pagesShell Sort MitisometricatNo ratings yet
- Markov Chains ErgodicityDocument8 pagesMarkov Chains ErgodicitypiotrpieniazekNo ratings yet
- Construction of RDocument11 pagesConstruction of RRestii Pati MentariiNo ratings yet
- Basic of Algorithms Analysis: Computational TractabilityDocument4 pagesBasic of Algorithms Analysis: Computational TractabilityMengistu KetemaNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 9: 3-SAT: How To Satisfy Most ClausesDocument4 pagesAdvanced Algorithms Course. Lecture Notes. Part 9: 3-SAT: How To Satisfy Most ClausesKasapaNo ratings yet
- Term Paper: Data StructuresDocument6 pagesTerm Paper: Data StructuresInderpal SinghNo ratings yet
- SearchingDocument13 pagesSearchingManisha NankooNo ratings yet
- A Lower Bound For The Worst Case: Theorem 8.1Document2 pagesA Lower Bound For The Worst Case: Theorem 8.1Elisangela da SilvaNo ratings yet
- Cme323 Lec4Document9 pagesCme323 Lec4rajsanadi3432No ratings yet
- Insertion SortDocument9 pagesInsertion SortjavvadiramyaNo ratings yet
- Common Functions Used in AnalysisDocument7 pagesCommon Functions Used in AnalysisCarl Andrew PimentelNo ratings yet
- Kendall Rank Correlation CoefficientDocument6 pagesKendall Rank Correlation CoefficientNTA UGC-NETNo ratings yet
- Functions of Big O NotationDocument1 pageFunctions of Big O NotationSawaira KazmiNo ratings yet
- 3Document392 pages3Daniel CorreaNo ratings yet
- Algorithm QuestionsDocument12 pagesAlgorithm Questionshpresingu8720No ratings yet
- Lecture Notes On Sorting: 15-122: Principles of Imperative Computation Frank Pfenning September 18, 2012Document12 pagesLecture Notes On Sorting: 15-122: Principles of Imperative Computation Frank Pfenning September 18, 2012Pradipta PaulNo ratings yet
- MC Ty Sequences 2009 1 PDFDocument9 pagesMC Ty Sequences 2009 1 PDFluke123456No ratings yet
- Maths RA4 11Document6 pagesMaths RA4 11nitrosc16703No ratings yet
- Algos Cs Cmu EduDocument15 pagesAlgos Cs Cmu EduRavi Chandra Reddy MuliNo ratings yet
- Chaos RandomnessDocument10 pagesChaos RandomnessMax ProctorNo ratings yet
- 38 Permutation FormulaDocument3 pages38 Permutation FormulaCamilo Vargas RomeroNo ratings yet
- Laboration 1-Retur-1Document12 pagesLaboration 1-Retur-1joelwillnNo ratings yet
- Coci Editorial Offfficial PDFDocument4 pagesCoci Editorial Offfficial PDFsreepranad DevarakondaNo ratings yet
- Mathematical Analysis of Nonrecursive AlgorithmsDocument13 pagesMathematical Analysis of Nonrecursive AlgorithmsSindhusaranya PrakashNo ratings yet
- RecursionProbSetA SolnDocument4 pagesRecursionProbSetA SolnManansh Ram Thakur 4-Year B.Tech. Mechanical EngineeringNo ratings yet
- Algorthim Important QuestionsDocument9 pagesAlgorthim Important Questionsganesh moorthiNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 10: HashingDocument4 pagesAdvanced Algorithms Course. Lecture Notes. Part 10: HashingKasapaNo ratings yet
- Algorithmic ComplexityDocument5 pagesAlgorithmic ComplexityJulius ColminasNo ratings yet
- Algorithm Design and AnalysisDocument8 pagesAlgorithm Design and AnalysisDipanwita MallickNo ratings yet
- Binary SearchDocument12 pagesBinary SearchpetejuanNo ratings yet
- Solu 3Document28 pagesSolu 3Aswani Kumar100% (2)
- Permutations and Determinants Math 130 Linear AlgebraDocument3 pagesPermutations and Determinants Math 130 Linear AlgebraCédric MztNo ratings yet
- Mathematical Foundations of Information TheoryFrom EverandMathematical Foundations of Information TheoryRating: 3.5 out of 5 stars3.5/5 (9)
- Teb 6Document1 pageTeb 6raman singh mannaNo ratings yet
- Teb 7Document1 pageTeb 7raman singh mannaNo ratings yet
- Teb 8Document1 pageTeb 8raman singh mannaNo ratings yet
- TB 4Document5 pagesTB 4raman singh mannaNo ratings yet
- Super Sample StackDocument1 pageSuper Sample Stackraman singh mannaNo ratings yet
- Sample Stack 2Document1 pageSample Stack 2raman singh mannaNo ratings yet
- Super Sample Stack2Document1 pageSuper Sample Stack2raman singh mannaNo ratings yet
- My JourneyDocument1 pageMy Journeyraman singh mannaNo ratings yet
- Patanjali ProjectDocument75 pagesPatanjali Projectsouravp95699No ratings yet
- Business Research Assignment - Abdul Khaliq (19mbe002)Document8 pagesBusiness Research Assignment - Abdul Khaliq (19mbe002)Abdul Khaliq ChoudharyNo ratings yet
- Random Variables and Probability DistributionDocument14 pagesRandom Variables and Probability DistributionAyesha Thahanie LucmanNo ratings yet
- Syllabus 1st YrDocument47 pagesSyllabus 1st YrD V Ravi KrishnaNo ratings yet
- SohamDocument19 pagesSohamdebasri_chatterjeeNo ratings yet
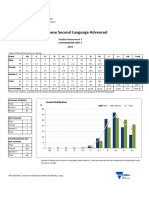
- Chinese SLADocument3 pagesChinese SLAGamer For Kids and AdultsNo ratings yet
- Arenius Minniti 2005Document16 pagesArenius Minniti 2005Sofía AparisiNo ratings yet
- How To Write A Research MethodologyDocument10 pagesHow To Write A Research MethodologyAdrianaNo ratings yet
- Criminology Theory and Practise Notes Topics 1 10Document48 pagesCriminology Theory and Practise Notes Topics 1 10danikaNo ratings yet
- An Organisational Study With Reference To Salisbury Indco Tea Factory, Gudalur FffafactorygudalurDocument74 pagesAn Organisational Study With Reference To Salisbury Indco Tea Factory, Gudalur Fffafactorygudalurdeepasuman220% (1)
- CP CPK Capability Calculation Sheet v3Document6 pagesCP CPK Capability Calculation Sheet v3Nabihah AzronNo ratings yet
- SST408 Sample Surveys Assignment (2021)Document2 pagesSST408 Sample Surveys Assignment (2021)Esekon Geoffrey LokolNo ratings yet
- A Lecture Versus Video Presentation On Knowledge and Skills of First Aid of Barangay Officials and Members of Bag-Ong Dalalguete Mahayag, Zamboanga Del SurDocument14 pagesA Lecture Versus Video Presentation On Knowledge and Skills of First Aid of Barangay Officials and Members of Bag-Ong Dalalguete Mahayag, Zamboanga Del SurJon Alvin M. Selisana0% (1)
- Rivised Proposal NewDocument21 pagesRivised Proposal NewAsrat ShikaNo ratings yet
- Bata Chappals PROJECTDocument58 pagesBata Chappals PROJECTMahesh KumarNo ratings yet
- ResearchDocument34 pagesResearchPreciosa Tobias RubiNo ratings yet
- A STUDY ON SUPPLY CHAIN MANAGEMENT OF Dairy ProductsDocument18 pagesA STUDY ON SUPPLY CHAIN MANAGEMENT OF Dairy ProductsUpadhayayAnkurNo ratings yet
- MINOR DraftDocument34 pagesMINOR Draftkrishna bhandariNo ratings yet
- Elements of Econometrics by Jan Kmenta ZDocument808 pagesElements of Econometrics by Jan Kmenta ZJeetu Sharma0% (1)
- 〈1788.1〉 LIGHT OBSCURATION METHOD FOR THE DETERMINATION OF SUBVISIBLE PARTICULATE MATTERDocument7 pages〈1788.1〉 LIGHT OBSCURATION METHOD FOR THE DETERMINATION OF SUBVISIBLE PARTICULATE MATTERMehran ImaniNo ratings yet
- Ore SamplingDocument8 pagesOre SamplingSunilNo ratings yet
- Grade Mathematics Assessment Assessing Childrens AcquDocument6 pagesGrade Mathematics Assessment Assessing Childrens Acqumajessa.balendresNo ratings yet
- Study On Employee Absenteeism AT Metcut Toolings Pvt. Ltd.Document40 pagesStudy On Employee Absenteeism AT Metcut Toolings Pvt. Ltd.padmavathi311No ratings yet
- Government Job Cover Letter SampleDocument4 pagesGovernment Job Cover Letter Samplekylopuluwob2100% (2)
- Halogen Moisture Analyzer User Manual DSHDocument9 pagesHalogen Moisture Analyzer User Manual DSHerwin surantaNo ratings yet
- Document 17Document35 pagesDocument 17Weiyi LimNo ratings yet
- At Notes (Sir Brad's Lecture)Document31 pagesAt Notes (Sir Brad's Lecture)Alessandra CieloNo ratings yet
- MBCQ721D-Quantitative Techniques For Management Application: Assignment 1Document12 pagesMBCQ721D-Quantitative Techniques For Management Application: Assignment 1Parikshit AgrawalNo ratings yet
- STEM ResearchProposalPaperDocument26 pagesSTEM ResearchProposalPaperIa NavarroNo ratings yet