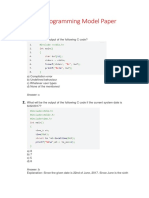
Download as pdf or txt
You might also like
- Random Motors Project Submission: Name - Surendranath KolachalamDocument10 pagesRandom Motors Project Submission: Name - Surendranath KolachalamSurendranath Kolachalam92% (13)
- Linear Regression AssignmentDocument8 pagesLinear Regression Assignmentkdeepika2704No ratings yet
- Question BankDocument14 pagesQuestion BankVinayak PhutaneNo ratings yet
- SP18 CS182 Midterm Solutions - EditedDocument14 pagesSP18 CS182 Midterm Solutions - EditedHasimNo ratings yet
- MT1SP19Document13 pagesMT1SP19HasimNo ratings yet
- MCQs DL Mid I R20 2023 With AnswersDocument3 pagesMCQs DL Mid I R20 2023 With AnswersNaga vijayNo ratings yet
- Exercises INF 5860: Exercise 1 Linear RegressionDocument5 pagesExercises INF 5860: Exercise 1 Linear RegressionPatrick O'RourkeNo ratings yet
- Cs230exam spr21 SolnDocument21 pagesCs230exam spr21 SolnMOHAMMADNo ratings yet
- Computer Vision Intern Position - Set 2Document3 pagesComputer Vision Intern Position - Set 24219- RupaNo ratings yet
- CENG400-Final-Fall 2014Document11 pagesCENG400-Final-Fall 2014Mohamad IssaNo ratings yet
- cs230exam_spr21Document16 pagescs230exam_spr21toluei.s29No ratings yet
- Lecture 2: Introduction To PytorchDocument7 pagesLecture 2: Introduction To PytorchNilesh ChaudharyNo ratings yet
- MT1 SP19 SolutionsDocument14 pagesMT1 SP19 SolutionsHasimNo ratings yet
- Neural Networks and Fuzzy Logic Question PaperDocument2 pagesNeural Networks and Fuzzy Logic Question PaperJhumur SantraNo ratings yet
- Assignment 1Document2 pagesAssignment 1Arnav YadavNo ratings yet
- Neural Network PDFDocument84 pagesNeural Network PDFMks KhanNo ratings yet
- cs230exam_win21Document21 pagescs230exam_win21toluei.s29No ratings yet
- CUDA Implementation of A Biologically Inspired Object Recognition SystemDocument5 pagesCUDA Implementation of A Biologically Inspired Object Recognition Systemproxymo1No ratings yet
- Solutions PDFDocument6 pagesSolutions PDFahmad zreegatNo ratings yet
- Syllabus For Amcat Programming Questions: Topic SubtopicsDocument10 pagesSyllabus For Amcat Programming Questions: Topic SubtopicsSanchit GuptaNo ratings yet
- National University of Computer and Emerging Sciences, Lahore CampusDocument9 pagesNational University of Computer and Emerging Sciences, Lahore Campusfaizan majidNo ratings yet
- GATE Study Material, Forum, Downloads, Discussions & More!Document17 pagesGATE Study Material, Forum, Downloads, Discussions & More!himani23No ratings yet
- Dsebl ZG522Document4 pagesDsebl ZG522Raju DNANo ratings yet
- Machine Learning Unit 2 MCQDocument17 pagesMachine Learning Unit 2 MCQHarsh Preet SinghNo ratings yet
- 2019S IP QuestionDocument40 pages2019S IP QuestionNJ DegomaNo ratings yet
- Examen Deep LearningDocument8 pagesExamen Deep LearningArij Boudhina100% (1)
- Deep Neural Nets - 33 Years Ago and 33 Years From NowDocument17 pagesDeep Neural Nets - 33 Years Ago and 33 Years From Nowtxboxi23No ratings yet
- A Simplified Generative Model Based On Gradient Descent and Mean Square ErrorDocument8 pagesA Simplified Generative Model Based On Gradient Descent and Mean Square ErrorOmar Lopez-RinconNo ratings yet
- TCS NQT Programming Logic Questions and AnswersDocument6 pagesTCS NQT Programming Logic Questions and Answersshreyasi.majumderNo ratings yet
- Efficient Net B0Document4 pagesEfficient Net B0NavyaNo ratings yet
- Unit 3Document4 pagesUnit 3Nikhil SainiNo ratings yet
- DL MCQDocument13 pagesDL MCQVinayak PhutaneNo ratings yet
- Computer Vision Intern Position - Set 1 (1) 354Document3 pagesComputer Vision Intern Position - Set 1 (1) 3544219- RupaNo ratings yet
- Autoencoder Assignment PDFDocument5 pagesAutoencoder Assignment PDFpraveen kandulaNo ratings yet
- Multi-Branch Network With Dynamically Matching Algorithm in Person Re-IdentificationDocument5 pagesMulti-Branch Network With Dynamically Matching Algorithm in Person Re-IdentificationThien ThaiNo ratings yet
- Time: 3 Hours Maximum Marks: 100 (Weightage: 75%) Question Number Is and Carries 40 Marks. Attempt Any Questions From The RestDocument3 pagesTime: 3 Hours Maximum Marks: 100 (Weightage: 75%) Question Number Is and Carries 40 Marks. Attempt Any Questions From The RestAbhijeetNo ratings yet
- ENSC427 Midterm2 1211Document2 pagesENSC427 Midterm2 1211wei996886No ratings yet
- Exam2b s11Document13 pagesExam2b s11serhatandic42No ratings yet
- Name:-Time Allowed: - 3 Hours: Artificial Neural Networks ExamDocument11 pagesName:-Time Allowed: - 3 Hours: Artificial Neural Networks ExamahmedNo ratings yet
- End SemDocument8 pagesEnd SemSamaira SinghNo ratings yet
- Theory Questions For Exam Advanced Modelling and SimulationDocument3 pagesTheory Questions For Exam Advanced Modelling and SimulationAndreaNo ratings yet
- Networking Mid-Semester Exam - 2004-5 Semester 1Document4 pagesNetworking Mid-Semester Exam - 2004-5 Semester 1abraha gebruNo ratings yet
- Bits F464 1339 C 2017 1Document4 pagesBits F464 1339 C 2017 1ashishNo ratings yet
- Homework DL 5GI Sheet1Document5 pagesHomework DL 5GI Sheet1Simon MengongNo ratings yet
- Pattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkDocument5 pagesPattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkEkin RafiaiNo ratings yet
- TCS Model Placement PaperDocument6 pagesTCS Model Placement PaperGaurav YadavNo ratings yet
- Assignment - Week 6 (Neural Networks) Type of Question: MCQ/MSQDocument4 pagesAssignment - Week 6 (Neural Networks) Type of Question: MCQ/MSQSURENDRAN D CS085No ratings yet
- Semester Suggestion SolutionDocument26 pagesSemester Suggestion SolutionNir (iPhone)No ratings yet
- Final Exam Update HuaweiDocument13 pagesFinal Exam Update HuaweiJonafe PiamonteNo ratings yet
- Deep Learning Week 12Document3 pagesDeep Learning Week 1221atharvaghodekarNo ratings yet
- CSCE 636: Deep Learning (Fall 2019) Assignment #2 Due 10/4/2019Document2 pagesCSCE 636: Deep Learning (Fall 2019) Assignment #2 Due 10/4/2019BPNo ratings yet
- Homework 5 Due April 24, 2017: Computer Vision CS 543 / ECE 549Document3 pagesHomework 5 Due April 24, 2017: Computer Vision CS 543 / ECE 549lbenitesanchezNo ratings yet
- 8 N 5 Nha 6 Qycd 0 F 3 TXDB 5 TJ 13 Ip 2 DXSN 7 LDocument10 pages8 N 5 Nha 6 Qycd 0 F 3 TXDB 5 TJ 13 Ip 2 DXSN 7 Lmahdi.alsaadi7No ratings yet
- NPTEL Online Certification Courses Indian Institute of Technology KharagpurDocument4 pagesNPTEL Online Certification Courses Indian Institute of Technology KharagpurSURENDRAN D CS085No ratings yet
- Gshard Scaling Giant Models WiDocument23 pagesGshard Scaling Giant Models Wigsvl2207No ratings yet
- Digital Image Processing QB 2017 - 18Document9 pagesDigital Image Processing QB 2017 - 18PrakherGuptaNo ratings yet
- AP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceFrom EverandAP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceNo ratings yet
- Mesh Generation: Advances and Applications in Computer Vision Mesh GenerationFrom EverandMesh Generation: Advances and Applications in Computer Vision Mesh GenerationNo ratings yet
- Keras to Kubernetes: The Journey of a Machine Learning Model to ProductionFrom EverandKeras to Kubernetes: The Journey of a Machine Learning Model to ProductionNo ratings yet
- Schaum’s Outline of Computer Graphics 2/EFrom EverandSchaum’s Outline of Computer Graphics 2/ERating: 3.5 out of 5 stars3.5/5 (6)
- Multi View Three Dimensional Reconstruction: Advanced Techniques for Spatial Perception in Computer VisionFrom EverandMulti View Three Dimensional Reconstruction: Advanced Techniques for Spatial Perception in Computer VisionNo ratings yet
- HW 1Document3 pagesHW 1ferdyNo ratings yet
- (COMP4332) (2021) (S) Final P6a03t 90367Document14 pages(COMP4332) (2021) (S) Final P6a03t 90367ferdyNo ratings yet
- (ECON2123) (2020) (S) Midterm Pcidkjhz 56218Document4 pages(ECON2123) (2020) (S) Midterm Pcidkjhz 56218ferdyNo ratings yet
- FerdyDocument1 pageFerdyferdyNo ratings yet
- Desty Menu Itroduction FebrindoDocument23 pagesDesty Menu Itroduction FebrindoferdyNo ratings yet
- Chapter 1 & 2 PDFDocument15 pagesChapter 1 & 2 PDF11D3 CHUA , Jasmine B.No ratings yet
- Artificial Neural Networks Kluniversity Course HandoutDocument18 pagesArtificial Neural Networks Kluniversity Course HandoutHarish ParuchuriNo ratings yet
- Sta347 MidtermDocument6 pagesSta347 MidtermHelen LiuNo ratings yet
- Statistical Hydrology PDFDocument41 pagesStatistical Hydrology PDFAlexandre HesslerNo ratings yet
- Stat 512 Final Project 12 10 16Document11 pagesStat 512 Final Project 12 10 16api-369102829No ratings yet
- Basic Econometrics Intro MujahedDocument57 pagesBasic Econometrics Intro MujahedYammanuri VenkyNo ratings yet
- AL-UoS BABSFY S3 Numeracy and Data Analysis Assignment April - June 2020 For Sep 2019 - IntakeDocument15 pagesAL-UoS BABSFY S3 Numeracy and Data Analysis Assignment April - June 2020 For Sep 2019 - IntakeZERO TO VARIABLE50% (2)
- Basic Estimation Techniques: Ninth Edition Ninth EditionDocument16 pagesBasic Estimation Techniques: Ninth Edition Ninth EditionNiraj SharmaNo ratings yet
- KDE - Direct Plug-In MethodDocument5 pagesKDE - Direct Plug-In MethodNumXL ProNo ratings yet
- RecapDocument75 pagesRecapBack UpNo ratings yet
- Conceptual-Framework ExampleDocument2 pagesConceptual-Framework ExampleaiyahnuevaNo ratings yet
- CP / CPK Calculation Sheet: SpecificationDocument6 pagesCP / CPK Calculation Sheet: Specificationjulian12345No ratings yet
- Cultures and Organizations: Software of The MindDocument14 pagesCultures and Organizations: Software of The MindAyhan NurselNo ratings yet
- Implementation of SPC Techniques in Automotive Industry: A Case StudyDocument15 pagesImplementation of SPC Techniques in Automotive Industry: A Case StudysushmaxNo ratings yet
- Internship Project - YogitaDocument51 pagesInternship Project - YogitaYogitaNo ratings yet
- TA Hypothesis TestingDocument8 pagesTA Hypothesis TestingstudentofstudentNo ratings yet
- Sta1101 - Group AssignmentDocument2 pagesSta1101 - Group AssignmentxiiaooahNo ratings yet
- Converting Daily Rainfall Data To Sub DaDocument11 pagesConverting Daily Rainfall Data To Sub DaAli AhmadNo ratings yet
- Literature Review Cafs IrpDocument5 pagesLiterature Review Cafs Irpaflstjdhs100% (1)
- TY BA EconomicsDocument10 pagesTY BA Economicsuma kaleNo ratings yet
- Analisis Hubungan Kualitas Pelayanan Front Office Department Dan Citra HotelDocument9 pagesAnalisis Hubungan Kualitas Pelayanan Front Office Department Dan Citra HotelMuhammad RizaldiNo ratings yet
- Mann Whitney U TestDocument13 pagesMann Whitney U TestddualloNo ratings yet
- My451 PDFDocument264 pagesMy451 PDFdariaNo ratings yet
- Module 1Document15 pagesModule 1Floree Emily Dela CruzNo ratings yet
- Psychophysical Motivational Effects of Music On Competitive SwimmingDocument8 pagesPsychophysical Motivational Effects of Music On Competitive SwimmingRicardo RochaNo ratings yet
- List of Focal Point ECOWAS Data Migration GroupDocument2 pagesList of Focal Point ECOWAS Data Migration GroupTamba KendemaNo ratings yet
- Eighth Edition Elementary Statistics: Bluman MC Graw HillDocument23 pagesEighth Edition Elementary Statistics: Bluman MC Graw HillAisah ReemNo ratings yet
- wst03 01 Que 2023.01Document28 pageswst03 01 Que 2023.01baojia chenNo ratings yet