Download as pdf or txt
You might also like
- Rio Tinto - Supplier Code - en - EXPDocument8 pagesRio Tinto - Supplier Code - en - EXPEnkhee bNo ratings yet
- WK1 Optimal Warehouse Design Literature Review and Case Study ApplicationDocument13 pagesWK1 Optimal Warehouse Design Literature Review and Case Study ApplicationElie Abi JaoudeNo ratings yet
- Case-Based Reinforcement Learning For Dynamic Inventory Control in A Multi-Agent Supply-Chain SystemDocument7 pagesCase-Based Reinforcement Learning For Dynamic Inventory Control in A Multi-Agent Supply-Chain SystemUmang SoniNo ratings yet
- ..CM in SC-Review ArticleDocument6 pages..CM in SC-Review ArticleKavitha Reddy GurrralaNo ratings yet
- Applications of Operations Research in Supply Chain ManagementDocument8 pagesApplications of Operations Research in Supply Chain ManagementInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Reveiw of LiteratureDocument23 pagesReveiw of Literatureifrah anjumNo ratings yet
- Production Operations Management Muhammad Hammad Alam Bs64 8004 Capacity PlanningDocument2 pagesProduction Operations Management Muhammad Hammad Alam Bs64 8004 Capacity PlanningHammad AlamNo ratings yet
- Uday Inventory Management DocsDocument11 pagesUday Inventory Management Docs3 IdiotsNo ratings yet
- Demand Forecasting and Budget Planning For AutomotDocument8 pagesDemand Forecasting and Budget Planning For AutomotVarshithNo ratings yet
- Mou Barak 2019Document7 pagesMou Barak 2019Rodrigo Lozada PreisingNo ratings yet
- Foad 2021 PaperDocument38 pagesFoad 2021 Papermajid yazdaniNo ratings yet
- PDF Research Paper On Supply Chain ManagementDocument6 pagesPDF Research Paper On Supply Chain ManagementaflbmmmmyNo ratings yet
- Using Reinforcement Learning For A Large Variable-Dimensional Inventory Management ProblemDocument9 pagesUsing Reinforcement Learning For A Large Variable-Dimensional Inventory Management ProblemPhalgun Mukesh Vyas ch19b076No ratings yet
- Quản lý tồn khoDocument23 pagesQuản lý tồn kho22160035No ratings yet
- 2.main Article 2Document14 pages2.main Article 2vothuyhien.159No ratings yet
- Group 2 Ds Project Report FinalDocument20 pagesGroup 2 Ds Project Report FinalDaddy MewariNo ratings yet
- Exploiting Discrete Event Simulation To Improve A Chicken Supply ChainDocument11 pagesExploiting Discrete Event Simulation To Improve A Chicken Supply ChainBOHR International Journal of Advances in Management ResearchNo ratings yet
- Ijiec 2020 25Document14 pagesIjiec 2020 25ajid kosNo ratings yet
- An Improved Demand Forecasting Model Using PDFDocument16 pagesAn Improved Demand Forecasting Model Using PDFArun KumarNo ratings yet
- Jem 1165Document21 pagesJem 1165Sham AntakiaNo ratings yet
- Business & Managerial Ethics Assignment: Application of Theory of Contraints To Parable of Sadhu CaseDocument7 pagesBusiness & Managerial Ethics Assignment: Application of Theory of Contraints To Parable of Sadhu CaseSunit MhasadeNo ratings yet
- Article Summary Ainul PDFDocument4 pagesArticle Summary Ainul PDFAinul mardziahNo ratings yet
- Artcile 1 - Fuzzy-AHP Approach For Warehouse Performance MeasurementDocument5 pagesArtcile 1 - Fuzzy-AHP Approach For Warehouse Performance MeasurementTunENSTAB100% (1)
- 1 s2.0 S2405844023021229 MainDocument19 pages1 s2.0 S2405844023021229 Main21104071No ratings yet
- Andiyappillai 2020 Ijais 451896Document5 pagesAndiyappillai 2020 Ijais 451896Christian CardiñoNo ratings yet
- Dynamic Buffer Management For Raw Material Supply in The Footwear IndustryDocument8 pagesDynamic Buffer Management For Raw Material Supply in The Footwear IndustryChristian Alexander Pilco NuñezNo ratings yet
- Inventory Optimization in Efficient SupplyDocument8 pagesInventory Optimization in Efficient SupplyAndres Felipe Cardozo ForeroNo ratings yet
- Reviewed Ds Project Report For Group 2Document19 pagesReviewed Ds Project Report For Group 2Daddy MewariNo ratings yet
- Benders Decomposition With Special Purpose Method For T - 2019 - Operations ReseDocument9 pagesBenders Decomposition With Special Purpose Method For T - 2019 - Operations ReseEtetu AbeshaNo ratings yet
- Picking Sorting Labeling Packing Loading Units Bill of LadingDocument3 pagesPicking Sorting Labeling Packing Loading Units Bill of LadingRamanRoutNo ratings yet
- Warehouse Design and Planning: A Mathematical Programming ApproachDocument15 pagesWarehouse Design and Planning: A Mathematical Programming ApproachHo Van RoiNo ratings yet
- 10 1109@ieis 2018 8597855Document5 pages10 1109@ieis 2018 8597855Adi ChandraNo ratings yet
- A Simulation Model To Determine Staffing Strategy and Warehouse Capacity For A Local Distribution CenterDocument12 pagesA Simulation Model To Determine Staffing Strategy and Warehouse Capacity For A Local Distribution CenterShivasanggari RamasamyNo ratings yet
- Postponement Strategies For Re-Engineering of Automotive Manufacturing: Knowledge-Management ImplicationsDocument21 pagesPostponement Strategies For Re-Engineering of Automotive Manufacturing: Knowledge-Management ImplicationsMonica DelaluzortizNo ratings yet
- Week 15 Strategic Challenges and Change For Supply ChainsDocument31 pagesWeek 15 Strategic Challenges and Change For Supply ChainsSaiparnNo ratings yet
- The Distribution Free Newsboy Problem: Review and ExtensionsDocument12 pagesThe Distribution Free Newsboy Problem: Review and Extensions백지원No ratings yet
- The Importance of Distribution Component in Supply Chain Management (SCM)Document3 pagesThe Importance of Distribution Component in Supply Chain Management (SCM)Aina SofiaNo ratings yet
- 7 MRP Under Demand UncertaintyDocument20 pages7 MRP Under Demand UncertaintyjseguragaldosNo ratings yet
- This Study Resource Was: Home Work: Chapter 3Document5 pagesThis Study Resource Was: Home Work: Chapter 3Nitin BasoyaNo ratings yet
- Inventory Management DissertationDocument5 pagesInventory Management DissertationCustomCollegePaperSingapore100% (1)
- Computers & Industrial Engineering: Ali Diabat, Effrosyni TheodorouDocument9 pagesComputers & Industrial Engineering: Ali Diabat, Effrosyni TheodorouQuỳnh NguyễnNo ratings yet
- EVA Supply Chain Demand Planning PDFDocument7 pagesEVA Supply Chain Demand Planning PDFEmilio Torres MedinaNo ratings yet
- S ChainDocument4 pagesS Chainsisay.d234No ratings yet
- Ata Allah Taleizadeh, Iman Shokr and Fariborz JoaliDocument31 pagesAta Allah Taleizadeh, Iman Shokr and Fariborz JoaliNafiz AlamNo ratings yet
- Modelling and SimulationDocument13 pagesModelling and Simulationsuresh_ramanujam007100% (1)
- Processes 09 01578Document14 pagesProcesses 09 01578Muhammad Umair AzramNo ratings yet
- 686-Article Text-5383-1-10-20230126Document18 pages686-Article Text-5383-1-10-20230126rui2318921366No ratings yet
- CASE STUDY Warehouse and Distribution OperationsDocument24 pagesCASE STUDY Warehouse and Distribution OperationsArijit DuttaNo ratings yet
- MBA602-POM Activities - Lessons 5 To 9Document15 pagesMBA602-POM Activities - Lessons 5 To 9debbiedimayuga1024No ratings yet
- A Reinforcement Learning Approach For Inventory ReplenishmentDocument11 pagesA Reinforcement Learning Approach For Inventory ReplenishmentSyauqi Hidayat BaihaqiNo ratings yet
- Applying Six Sigma Methodology To Collaborative ForecastingDocument13 pagesApplying Six Sigma Methodology To Collaborative ForecastingSalah HammamiNo ratings yet
- An Enhanced Workflow Reengineering Methodology For SmesDocument15 pagesAn Enhanced Workflow Reengineering Methodology For Smespassme inNo ratings yet
- Ijamt 2008Document13 pagesIjamt 2008Bryan Macedo de LeonNo ratings yet
- Jesa 56.01 09Document8 pagesJesa 56.01 09Pauline JanerolNo ratings yet
- Evaluation of Inventory Cost in Supply Chain Using Case Based ReasoningDocument7 pagesEvaluation of Inventory Cost in Supply Chain Using Case Based ReasoningInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- A Manufacturing Industry Case Study: ABC and HML Analysis For Inventory ManagementDocument4 pagesA Manufacturing Industry Case Study: ABC and HML Analysis For Inventory Management18P917 Vignesh Raja MNo ratings yet
- Case Study: Implementation of 5S Methodology in JCB Assembly Business Unit Material StorageDocument6 pagesCase Study: Implementation of 5S Methodology in JCB Assembly Business Unit Material StorageInnovative Research PublicationsNo ratings yet
- AbhishkeDocument95 pagesAbhishkeAkash GuptaNo ratings yet
- MSI Muhammad DanuriDocument9 pagesMSI Muhammad DanuriHillary Murillo SilesNo ratings yet
- Reading 3Document16 pagesReading 3Trúc LyNo ratings yet
- Military Supply Chain Management: From Deployment to Victory, Mastering the Logistics DanceFrom EverandMilitary Supply Chain Management: From Deployment to Victory, Mastering the Logistics DanceNo ratings yet
- IMSE 710-810 TSP MapDocument1 pageIMSE 710-810 TSP MapSuyashPratapNo ratings yet
- Algorithms 14 00240Document14 pagesAlgorithms 14 00240SuyashPratapNo ratings yet
- Speedaccuracy Trade-Offs For Modern ConvolutionalDocument22 pagesSpeedaccuracy Trade-Offs For Modern ConvolutionalSuyashPratapNo ratings yet
- F20HW2Document3 pagesF20HW2SuyashPratapNo ratings yet
- Example 03-Shipper Problem EOS FormulationDocument3 pagesExample 03-Shipper Problem EOS FormulationSuyashPratapNo ratings yet
- Annual Report of PROTON 2006Document195 pagesAnnual Report of PROTON 2006IzzahAzizNo ratings yet
- Case Analysis WalMart3Document6 pagesCase Analysis WalMart3Pei Wing GanNo ratings yet
- JK ProjectDocument60 pagesJK Projectmilan77100% (8)
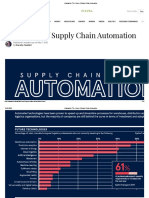
- The Future of Supply Chain AutomationDocument15 pagesThe Future of Supply Chain AutomationAndrey MatusevichNo ratings yet
- Solution Manual For Principles of Information Systems 13th Edition Stair Reynolds 1305971779 9781305971776Document10 pagesSolution Manual For Principles of Information Systems 13th Edition Stair Reynolds 1305971779 9781305971776susanbradygajkznydrf100% (33)
- Isuzu Report - Final Phase 1 ReportDocument75 pagesIsuzu Report - Final Phase 1 Reportapi-394430334No ratings yet
- BA552 Week3Document83 pagesBA552 Week3Reza MohagiNo ratings yet
- Purchasing Management Unit 4Document24 pagesPurchasing Management Unit 4DEREJENo ratings yet
- 10m021 Supply Chain ManagementDocument1 page10m021 Supply Chain Managementarun2386No ratings yet
- Supply Chain Strategy For Super BananaDocument15 pagesSupply Chain Strategy For Super BananaStephen BaronNo ratings yet
- Company Toll GroupDocument1 pageCompany Toll GroupDnyana RaghunathNo ratings yet
- Logistics Supply Chain ManagementDocument3 pagesLogistics Supply Chain ManagementUmesh ThokaleNo ratings yet
- Business and Management HL P2 MsDocument25 pagesBusiness and Management HL P2 MsSharmel Altamirano SancanNo ratings yet
- Session 4: Supply Chain IntegrationDocument32 pagesSession 4: Supply Chain IntegrationWonderkid YHHNo ratings yet
- Supply Chain Management ... Ventura - Academia - EduDocument8 pagesSupply Chain Management ... Ventura - Academia - EdubeatrixNo ratings yet
- Sip PresentationDocument7 pagesSip PresentationKhushank JoshiNo ratings yet
- Smart Manufacturing - National Implementation FrameworkDocument150 pagesSmart Manufacturing - National Implementation FrameworksabetaliNo ratings yet
- Adidas Business ProfileDocument6 pagesAdidas Business Profileapi-339175469No ratings yet
- SONY CSR StrategiesDocument17 pagesSONY CSR StrategiesshrutisandeepNo ratings yet
- L4 Diploma in Procurement and Supply Mar17 PDFDocument3 pagesL4 Diploma in Procurement and Supply Mar17 PDFtapera_mangeziNo ratings yet
- SumberDocument2 pagesSumberreyNo ratings yet
- COVID 19 Pandemic Related Supply CH - 2021 - Transportation Research Part E LogDocument26 pagesCOVID 19 Pandemic Related Supply CH - 2021 - Transportation Research Part E LogPredrag IvkovicNo ratings yet
- CM LVIII 03 210123 Ram SinghDocument6 pagesCM LVIII 03 210123 Ram SinghRoshan DhirsamantNo ratings yet
- Jia 2020Document20 pagesJia 2020Youssef MalekNo ratings yet
- Wholesaling and Logistics PDFDocument12 pagesWholesaling and Logistics PDFErra PeñafloridaNo ratings yet
- Answers - Case AnalysisDocument9 pagesAnswers - Case AnalysisDanelle TamarayNo ratings yet
- Difference Between Logistics and Supply Chain Management (With Comparison Chart) - Key DifferencesDocument19 pagesDifference Between Logistics and Supply Chain Management (With Comparison Chart) - Key DifferencesAlberto Luna100% (1)
- AMUL Case StudyDocument4 pagesAMUL Case StudyRicha Garg60% (5)
- ASCP User Guide 11iDocument450 pagesASCP User Guide 11iRajesh RavulapalliNo ratings yet