Download as pdf or txt
You might also like
- Geometry Moise Downs Answers PDFDocument3 pagesGeometry Moise Downs Answers PDFAndres Palchucan0% (3)
- EN - 840Dsl Kinematic Chain Milling 0408 - 2019-03Document322 pagesEN - 840Dsl Kinematic Chain Milling 0408 - 2019-03F.C100% (1)
- CNN-based and DTW Features For Human Activity Recognition On Depth MapsDocument14 pagesCNN-based and DTW Features For Human Activity Recognition On Depth Mapsjacekt89No ratings yet
- MOMS With Events: Multi-Object Motion Segmentation With Monocular Event CamerasDocument15 pagesMOMS With Events: Multi-Object Motion Segmentation With Monocular Event CamerasSergio Marcelino Trejo FuentesNo ratings yet
- Human Action Recognition Using Key-Frame AttentionDocument20 pagesHuman Action Recognition Using Key-Frame AttentionTâm TrầnNo ratings yet
- GRU-based Attention Mechanism For Human Activity RecognitionDocument6 pagesGRU-based Attention Mechanism For Human Activity RecognitionMusabbir Ahmed ArrafiNo ratings yet
- Human Action Recognition On Raw Depth MapsDocument4 pagesHuman Action Recognition On Raw Depth Mapsjacekt89No ratings yet
- Applied Sciences: Deep Learning Based Human Activity Recognition Using Spatio-Temporal Image Formation of Skeleton JointsDocument24 pagesApplied Sciences: Deep Learning Based Human Activity Recognition Using Spatio-Temporal Image Formation of Skeleton JointsArs Arifur RahmanNo ratings yet
- Human Activity Recognition Based On Time Series Analysis Using U-NetDocument21 pagesHuman Activity Recognition Based On Time Series Analysis Using U-NetEzequiel França Dos SantosNo ratings yet
- Human Activity Recognition Process Using 3-D Posture DataDocument12 pagesHuman Activity Recognition Process Using 3-D Posture DataJojo SeseNo ratings yet
- Aerial Insights Deep Learning-Based Human Action Recognition in Drone ImageryDocument16 pagesAerial Insights Deep Learning-Based Human Action Recognition in Drone Imageryamsquare29No ratings yet
- Pramono Hierarchical Self-Attention Network For Action Localization in Videos ICCV 2019 PaperDocument10 pagesPramono Hierarchical Self-Attention Network For Action Localization in Videos ICCV 2019 Papervishalk172No ratings yet
- Applied Soft Computing Journal: Leiyue Yao, Wei Yang, Wei HuangDocument10 pagesApplied Soft Computing Journal: Leiyue Yao, Wei Yang, Wei HuangFriji RachaNo ratings yet
- Skeleton Based Human Action Recognition Using A Structured-Tree Neural NetworkDocument6 pagesSkeleton Based Human Action Recognition Using A Structured-Tree Neural NetworkArs Arifur RahmanNo ratings yet
- Sensors: Deep Convolutional and LSTM Recurrent Neural Networks For Multimodal Wearable Activity RecognitionDocument25 pagesSensors: Deep Convolutional and LSTM Recurrent Neural Networks For Multimodal Wearable Activity RecognitionKailash ANo ratings yet
- Human Action Recognition On Raw Depth MapsDocument13 pagesHuman Action Recognition On Raw Depth Mapsjacekt89No ratings yet
- Human Key-Point DetectDocument11 pagesHuman Key-Point DetectABờCờNguyễnNo ratings yet
- Convolutional Neural Networks For Human Activity Recognition Using Mobile SensorsDocument18 pagesConvolutional Neural Networks For Human Activity Recognition Using Mobile SensorsAlan BensonNo ratings yet
- Design and Implementation of A Convolutional Neural Network On An Edge Computing Smartphone For Human Activity RecognitionDocument12 pagesDesign and Implementation of A Convolutional Neural Network On An Edge Computing Smartphone For Human Activity Recognitionsdjnsj jnjcdejnewNo ratings yet
- Motion Fused Frames: Data Level Fusion Strategy For Hand Gesture RecognitionDocument9 pagesMotion Fused Frames: Data Level Fusion Strategy For Hand Gesture RecognitionFsha MerhawitNo ratings yet
- Analysis of Walking Pattern Using LRCN For Early Diagnosis of Dementia in Elderly PatientsDocument12 pagesAnalysis of Walking Pattern Using LRCN For Early Diagnosis of Dementia in Elderly PatientsIJRASETPublicationsNo ratings yet
- Ullah 2019Document6 pagesUllah 2019Dinar TASNo ratings yet
- Human Activity Recognition Method Using Joint Deep Learning and Acceleration SignalDocument9 pagesHuman Activity Recognition Method Using Joint Deep Learning and Acceleration SignalIAES IJAINo ratings yet
- Concurrent Activity Recognition With Multimodal CNN-LSTM StructureDocument14 pagesConcurrent Activity Recognition With Multimodal CNN-LSTM StructurefediNo ratings yet
- Wang - Human Action Recognition Algorithm Based On Multi-Feature Map Fusion - 2020Document9 pagesWang - Human Action Recognition Algorithm Based On Multi-Feature Map Fusion - 2020masoud kiaNo ratings yet
- 2 PBDocument5 pages2 PBJulianto SaputroNo ratings yet
- Violence Detection Paper 1Document6 pagesViolence Detection Paper 1Sheetal SonawaneNo ratings yet
- SLFLSDFKSFLDKJDocument3 pagesSLFLSDFKSFLDKJfs12unoNo ratings yet
- Online Detection and Classification of Dynamic Hand Gestures With Recurrent 3D Convolutional Neural NetworksDocument9 pagesOnline Detection and Classification of Dynamic Hand Gestures With Recurrent 3D Convolutional Neural NetworksPawan ChaurasiyaNo ratings yet
- Spatial-Temporal Information Aggregation and Cross-Modality Interactive Learning For RGB-D-Based Human Action RecognitionDocument12 pagesSpatial-Temporal Information Aggregation and Cross-Modality Interactive Learning For RGB-D-Based Human Action RecognitionPrajwal GNo ratings yet
- Embedded Features For 1D CNN-based Action Recognition On Depth MapsDocument13 pagesEmbedded Features For 1D CNN-based Action Recognition On Depth Mapsjacekt89No ratings yet
- Review paper-HARDocument3 pagesReview paper-HARJhalak DeyNo ratings yet
- 2d Convolution ResearchDocument15 pages2d Convolution ResearchisharkNo ratings yet
- 1 PBDocument8 pages1 PBHi ManshuNo ratings yet
- Sensors: New Sensor Data Structuring For Deeper Feature Extraction in Human Activity RecognitionDocument26 pagesSensors: New Sensor Data Structuring For Deeper Feature Extraction in Human Activity RecognitionkirubhaNo ratings yet
- Multi-Stream Siamese and Faster Region-Based Neural Network For Real-Time Object TrackingDocument14 pagesMulti-Stream Siamese and Faster Region-Based Neural Network For Real-Time Object TrackingAnanya SinghNo ratings yet
- Research PaperDocument9 pagesResearch Papersharmaharsh506325No ratings yet
- Spatial-Temporal Fusion Convolutional Neural Network For Simulated Driving Behavior RecognitionDocument7 pagesSpatial-Temporal Fusion Convolutional Neural Network For Simulated Driving Behavior RecognitionBOUMARAF IbtissamNo ratings yet
- Understanding The Motion Adaption of Machine Using Long Short - Term Memory Networks For Voiceless Virtual AssistantDocument8 pagesUnderstanding The Motion Adaption of Machine Using Long Short - Term Memory Networks For Voiceless Virtual Assistantsubhrajit royNo ratings yet
- Convolutional Neural Network For Satellite Image ClassificationDocument14 pagesConvolutional Neural Network For Satellite Image Classificationwilliam100% (1)
- Divya Phase 2 ReportDocument51 pagesDivya Phase 2 ReportMost WantedNo ratings yet
- Human Activity RGDBDocument15 pagesHuman Activity RGDBsushanprazNo ratings yet
- Dop-DenseNet: Densely Convolutional Neural Network-Based Gesture Recognition Using A Micro-Doppler RadarDocument9 pagesDop-DenseNet: Densely Convolutional Neural Network-Based Gesture Recognition Using A Micro-Doppler RadarPhuc HoangNo ratings yet
- Sensors: Semantic Segmentation With Transfer Learning For Off-Road Autonomous DrivingDocument21 pagesSensors: Semantic Segmentation With Transfer Learning For Off-Road Autonomous DrivingHedieh MadahNo ratings yet
- Autonomous Intelligent Surveillance Networks: Richard ComleyDocument5 pagesAutonomous Intelligent Surveillance Networks: Richard ComleyetosidNo ratings yet
- Human Activity Detection Using Deep - 2-1Document8 pagesHuman Activity Detection Using Deep - 2-1Riky Tri YunardiNo ratings yet
- Sequential Deep Learning For Human Action Recognition: 1 Introduction and Related WorkDocument2 pagesSequential Deep Learning For Human Action Recognition: 1 Introduction and Related WorkSHADAKSHARI ARUTAGINo ratings yet
- Tang Deep Progressive Reinforcement CVPR 2018 PaperDocument10 pagesTang Deep Progressive Reinforcement CVPR 2018 PaperTruong GiangNo ratings yet
- Sun Human Action Recognition ICCV 2015 PaperDocument9 pagesSun Human Action Recognition ICCV 2015 PaperMohit KumarNo ratings yet
- QIF Research ProposalDocument5 pagesQIF Research ProposalVipul BaghelNo ratings yet
- 23 AI Crowd A - Cloud-Based - Deep - Learning - Framework - For - Early - Detection - of - Pushing - at - Crowded - Event - EntrancesDocument14 pages23 AI Crowd A - Cloud-Based - Deep - Learning - Framework - For - Early - Detection - of - Pushing - at - Crowded - Event - Entrances20cs068No ratings yet
- Emebedded SkeletonDocument9 pagesEmebedded SkeletonBouhafs AbdelkaderNo ratings yet
- Real Time Object Detection Using CNNDocument5 pagesReal Time Object Detection Using CNNyevanNo ratings yet
- Remotesensing 13 00089 v2Document23 pagesRemotesensing 13 00089 v2Varun GoradiaNo ratings yet
- Mtpose: Human Pose Estimation With High-Resolution Multi-Scale TransformersDocument24 pagesMtpose: Human Pose Estimation With High-Resolution Multi-Scale Transformersleodo5159No ratings yet
- JETIR2209375Document6 pagesJETIR2209375JoyalNo ratings yet
- Tapu A Smartphone-Based Obstacle 2013 ICCV Paper PDFDocument8 pagesTapu A Smartphone-Based Obstacle 2013 ICCV Paper PDFAlejandro ReyesNo ratings yet
- Fast Monocular Hand Pose Estimation On Embedded Systems: A B B A, C DDocument20 pagesFast Monocular Hand Pose Estimation On Embedded Systems: A B B A, C DSpring PrintsNo ratings yet
- 1 s2.0 S0925231223006847 MainDocument12 pages1 s2.0 S0925231223006847 Mainsiddhartha rajNo ratings yet
- Graph TtransferDocument9 pagesGraph TtransferNehaKarunyaNo ratings yet
- SSRN Id4107251Document7 pagesSSRN Id4107251Carmen GheorgheNo ratings yet
- Summary of ProgressDocument9 pagesSummary of ProgressJ SANDHYANo ratings yet
- Application 5600108004Document1 pageApplication 5600108004J SANDHYANo ratings yet
- PRC3Document14 pagesPRC3J SANDHYANo ratings yet
- Msme Idea Hackathon IslDocument2 pagesMsme Idea Hackathon IslJ SANDHYANo ratings yet
- Presentation 1Document3 pagesPresentation 1J SANDHYANo ratings yet
- GANTTPERTChartDocument1 pageGANTTPERTChartJ SANDHYANo ratings yet
- LITERATUREDocument9 pagesLITERATUREJ SANDHYANo ratings yet
- IeeeDocument7 pagesIeeeJ SANDHYANo ratings yet
- Bonafide Format NFSTDocument1 pageBonafide Format NFSTJ SANDHYA100% (1)
- AE2104-Flight Orbital-Slides 14 AnnotatedDocument30 pagesAE2104-Flight Orbital-Slides 14 AnnotatedJ SANDHYANo ratings yet
- Phys320 Lecture07Document15 pagesPhys320 Lecture07J SANDHYANo ratings yet
- Video Based CNN LSTMDocument6 pagesVideo Based CNN LSTMJ SANDHYANo ratings yet
- 3.2.2.a OrbitmechmodelingDocument50 pages3.2.2.a OrbitmechmodelingJ SANDHYANo ratings yet
- DacsignDocument6 pagesDacsignJ SANDHYANo ratings yet
- Staticsign CNNDocument8 pagesStaticsign CNNJ SANDHYANo ratings yet
- Heuristic Search: Dr.M. Nagaratna Professor, Dept - of CSE JntucehDocument54 pagesHeuristic Search: Dr.M. Nagaratna Professor, Dept - of CSE JntucehJ SANDHYANo ratings yet
- R R: G R A: Esnet in Esnet Eneralizing Esidual RchitecturesDocument7 pagesR R: G R A: Esnet in Esnet Eneralizing Esidual RchitecturesJ SANDHYANo ratings yet
- Laplace TransformDocument13 pagesLaplace TransformJ SANDHYANo ratings yet
- Clipping Noise Mitigation Sensing For Recovery of Ofdm SignalsDocument3 pagesClipping Noise Mitigation Sensing For Recovery of Ofdm SignalsJ SANDHYANo ratings yet
- J.Sandhya: PAPER ID: IJCRT1813276Document2 pagesJ.Sandhya: PAPER ID: IJCRT1813276J SANDHYANo ratings yet
- Sentence, Phrase, ClausesDocument7 pagesSentence, Phrase, ClausesMaria Alonica Mae BacoyNo ratings yet
- Mechanics M2: Pearson Edexcel GCEDocument11 pagesMechanics M2: Pearson Edexcel GCE블루2SNo ratings yet
- Assignment 2 (2019) PDFDocument4 pagesAssignment 2 (2019) PDFRishabh ShrivastavaNo ratings yet
- HazardsDocument58 pagesHazardsAshutosh Verma100% (1)
- Notes On PSODocument4 pagesNotes On PSOAllan MarbaniangNo ratings yet
- Kinematics and Dynamics of Machinery - Experiments PDFDocument47 pagesKinematics and Dynamics of Machinery - Experiments PDFUtkarsh SinghNo ratings yet
- The Atiyah-Hirzebruch Spectral Sequence: Caleb JiDocument13 pagesThe Atiyah-Hirzebruch Spectral Sequence: Caleb JiCaleb JiNo ratings yet
- Lecture Notes in Discrete Mathematics - Part 3Document10 pagesLecture Notes in Discrete Mathematics - Part 3Moch DedyNo ratings yet
- Number of K-Combination: Without Repetition, Also Called K-Permutation (But Which Is Not A Permutation of S inDocument5 pagesNumber of K-Combination: Without Repetition, Also Called K-Permutation (But Which Is Not A Permutation of S inYusuf Fadlila RachmanNo ratings yet
- Revised BEED Curriculum 2011 PDFDocument13 pagesRevised BEED Curriculum 2011 PDFmanuelNo ratings yet
- Engr-Phys 216 HW3 F23Document2 pagesEngr-Phys 216 HW3 F23Terra DrakeNo ratings yet
- Chapter 5Document28 pagesChapter 5pavithraNo ratings yet
- Survey Article: Power Equations in Endurance Sports GDocument17 pagesSurvey Article: Power Equations in Endurance Sports Gnico Michou-SaucetNo ratings yet
- 2010 Summer Camp - Week 4 - Projective GeometryDocument6 pages2010 Summer Camp - Week 4 - Projective GeometryTarik Adnan MoonNo ratings yet
- No 1Document7 pagesNo 1Fauziah Karina WNo ratings yet
- Tabel MetStat (Disusun Oleh Matthew Alvian)Document48 pagesTabel MetStat (Disusun Oleh Matthew Alvian)Karintya Aisya100% (1)
- Quiz1 - Probability of Events: IB Mathematics SLDocument1 pageQuiz1 - Probability of Events: IB Mathematics SL凛音No ratings yet
- Module: Linguistics: Linguistics Schools and MovementsDocument43 pagesModule: Linguistics: Linguistics Schools and MovementsMalak0% (1)
- RLC Resonant Circuits: Prepared By: - Zanyar AwezDocument24 pagesRLC Resonant Circuits: Prepared By: - Zanyar AwezSul SyaNo ratings yet
- Semiotics-In-Mathematics-Educat - Radford, Luis PDFDocument284 pagesSemiotics-In-Mathematics-Educat - Radford, Luis PDFsandu.stuff100% (1)
- Behavior of Strip Footing On Geogrid-Reinforced Sand Over A Soft Clay SlopeDocument11 pagesBehavior of Strip Footing On Geogrid-Reinforced Sand Over A Soft Clay SlopevishwaskhatriNo ratings yet
- MySQL Data Types Quick Reference TableDocument3 pagesMySQL Data Types Quick Reference TableBishnu DasNo ratings yet
- 255 SMP Seaa C04L06Document7 pages255 SMP Seaa C04L06alexNo ratings yet
- Lesson 6 Normal DistributionDocument15 pagesLesson 6 Normal DistributionLoe HiNo ratings yet
- Java Project ProgramsDocument53 pagesJava Project ProgramsArihant KumarNo ratings yet
- Pert CPM ExampleDocument22 pagesPert CPM Exampleleodegarioporral0% (1)
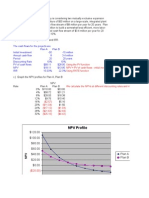
- NPV Profile: Using The PV Function NPV PV of Cash Flows - Initial Investment Using RATE FunctionDocument4 pagesNPV Profile: Using The PV Function NPV PV of Cash Flows - Initial Investment Using RATE FunctionDwayne Mullins100% (2)