Download as pdf or txt
You might also like
- Ide To 6 Classification AlgorithmsDocument34 pagesIde To 6 Classification AlgorithmsAssy GlendaNo ratings yet
- Prediction of Heart Disease Final-1-20 April - Jupyter NotebookDocument10 pagesPrediction of Heart Disease Final-1-20 April - Jupyter NotebookRushabh JainNo ratings yet
- Heart DieseseDocument9 pagesHeart DieseseSuhani ShindeNo ratings yet
- Heart Dataset AnalysisDocument24 pagesHeart Dataset Analysiseseoghene emebraduNo ratings yet
- QUIZ Week 2 CART Practice PDFDocument10 pagesQUIZ Week 2 CART Practice PDFNagarajan ThandayuthamNo ratings yet
- Heart Attacks AnalysisDocument10 pagesHeart Attacks AnalysisNarasimhaNo ratings yet
- Heart: Our "Goal" Predict The Presence of Heart Disease in The PatientDocument73 pagesHeart: Our "Goal" Predict The Presence of Heart Disease in The Patientaditya b100% (1)
- Heart Failure PredictionDocument41 pagesHeart Failure PredictionAKKALA VIJAYGOUD100% (1)
- Python SolutionDocument30 pagesPython SolutionMile MileNo ratings yet
- Seaborn - Plots - Jupyter NotebookDocument36 pagesSeaborn - Plots - Jupyter NotebookLahari BanalaNo ratings yet
- Week - 6 - SWI - MLP - LogisticRegression - Ipynb - ColaboratoryDocument15 pagesWeek - 6 - SWI - MLP - LogisticRegression - Ipynb - ColaboratoryMeer HassanNo ratings yet
- B 4 HeartDocument9 pagesB 4 HeartSuhani ShindeNo ratings yet
- Heart Attack Risk Assessment ModelDocument13 pagesHeart Attack Risk Assessment ModelmbowejNo ratings yet
- Statistical Analysis Using R Cia - 2 MBADocument35 pagesStatistical Analysis Using R Cia - 2 MBAJEFFREY WILLIAMS P M 20221013No ratings yet
- Lab 3. Linear Regression 230223Document7 pagesLab 3. Linear Regression 230223ruso100% (1)
- Import As From Import From Import From Import From Import From Import From Import From Import From Import From Import From Import Import AsDocument8 pagesImport As From Import From Import From Import From Import From Import From Import From Import From Import From Import From Import Import Asvince.lachicaNo ratings yet
- Au953721103009 FontDocument26 pagesAu953721103009 Fonttommyshelby.gr1No ratings yet
- Logistic Regression 205Document8 pagesLogistic Regression 205Ranadeep DeyNo ratings yet
- Heart Disease Prediction - Jupyter NotebookDocument9 pagesHeart Disease Prediction - Jupyter Notebookkavya100% (1)
- Shailesh020902@gmail - Com 1Document1 pageShailesh020902@gmail - Com 1Shailendra chaudharyNo ratings yet
- Haberman Datasets Analysis - Ipynb - ColaboratoryDocument13 pagesHaberman Datasets Analysis - Ipynb - ColaboratoryShyamal HazarikaNo ratings yet
- Heart Disease Classification ML Assignment - Jupyter NotebookDocument7 pagesHeart Disease Classification ML Assignment - Jupyter Notebookfurole sammyceNo ratings yet
- Logistic - Ipynb - ColaboratoryDocument6 pagesLogistic - Ipynb - ColaboratoryAkansha UniyalNo ratings yet
- Linear Regression: Data ExplorationDocument12 pagesLinear Regression: Data ExplorationFèdríck SämùélNo ratings yet
- Assignments - Day 2 - Jupyter NotebookDocument6 pagesAssignments - Day 2 - Jupyter NotebookSrinAdh YadavNo ratings yet
- C2M4 - Assignment: 1 Cox Proportional Hazards and Random Survival ForestsDocument18 pagesC2M4 - Assignment: 1 Cox Proportional Hazards and Random Survival ForestsSarah MendesNo ratings yet
- Logistic Regression in RDocument7 pagesLogistic Regression in RPratik GugliyaNo ratings yet
- SVM - RF - Diabetes - CSV - 26 - 6 - 2023.ipynb - ColaboratoryDocument8 pagesSVM - RF - Diabetes - CSV - 26 - 6 - 2023.ipynb - Colaboratoryutsavarora1912No ratings yet
- K Means AlgorithmDocument1 pageK Means AlgorithmROHAN G ANo ratings yet
- Loading The Dataset: 'Diabetes - CSV'Document4 pagesLoading The Dataset: 'Diabetes - CSV'Divyani ChavanNo ratings yet
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsDocument38 pagesC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- Sunbase Data AssignmentDocument11 pagesSunbase Data Assignmentfanrock281No ratings yet
- EDA HabermanDatasetDocument15 pagesEDA HabermanDatasetgopisaiNo ratings yet
- Lecture Material 8Document9 pagesLecture Material 8Ali NaseerNo ratings yet
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Linear RegressionDocument10 pagesLinear RegressionWONDYE DESTANo ratings yet
- Logistic RegressionDocument12 pagesLogistic RegressionKagade AjinkyaNo ratings yet
- Hypothesis Testing PDFDocument9 pagesHypothesis Testing PDFmdkashif1299No ratings yet
- Desarrollo Solemne 3 - ..Ipynb - ColaboratoryDocument4 pagesDesarrollo Solemne 3 - ..Ipynb - ColaboratoryCarola Araya100% (2)
- MBA SectionD MBA20235 PranayGupta Assignment RDocument16 pagesMBA SectionD MBA20235 PranayGupta Assignment RSomesh RoyNo ratings yet
- B - 59 - SMA - Exp 4Document9 pagesB - 59 - SMA - Exp 4Ritz FernandesNo ratings yet
- Decision Tree Algorithm 1677030641Document9 pagesDecision Tree Algorithm 1677030641juanNo ratings yet
- COMP5318Document42 pagesCOMP5318cheng011015No ratings yet
- 18MIS7020 - Lab 4Document20 pages18MIS7020 - Lab 4Abhinav GNo ratings yet
- Logistic RegressionDocument10 pagesLogistic RegressionC TNo ratings yet
- Dsbda 10Document3 pagesDsbda 10monaliauti2No ratings yet
- Tensorflow Logistic RegressionDocument10 pagesTensorflow Logistic RegressionC TNo ratings yet
- Import As Import As: "Iris - CSV"Document4 pagesImport As Import As: "Iris - CSV"avinashNo ratings yet
- Name: MANOGNA GV Email Id: Major Project: Diabetes Prediction Let's Import Required Libraries!Document4 pagesName: MANOGNA GV Email Id: Major Project: Diabetes Prediction Let's Import Required Libraries!Manogna GvNo ratings yet
- AGNES and SPECTRAL CLUSTERING IN R PDFDocument1 pageAGNES and SPECTRAL CLUSTERING IN R PDFSahas ParabNo ratings yet
- Dsbda 4Document4 pagesDsbda 4Arbaz ShaikhNo ratings yet
- Haberman Data Set Ed ADocument10 pagesHaberman Data Set Ed AVarun AkuthotaNo ratings yet
- Mla - 2 (Cia - 3) - 20221013Document21 pagesMla - 2 (Cia - 3) - 20221013JEFFREY WILLIAMS P M 20221013No ratings yet
- Capstone Project 2Document15 pagesCapstone Project 2DavidNo ratings yet
- Arbol de Decisiones XGBoosDocument7 pagesArbol de Decisiones XGBoosJaizo Jesus Diaz MoraNo ratings yet
- Assign10.Ipynb - ColabDocument8 pagesAssign10.Ipynb - Colabatharvapudale0608No ratings yet
- 4-10 AimlDocument25 pages4-10 AimlGuna SeelanNo ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- ML Practical 04Document20 pagesML Practical 04whitehouse2202No ratings yet
- CPH CHPTR 8 Revisednon Communicable DiseasesDocument24 pagesCPH CHPTR 8 Revisednon Communicable DiseasesJerlyn Francheska RodrinNo ratings yet
- Kuliah 16 Cor PulmonaleDocument41 pagesKuliah 16 Cor PulmonalecaturwiraNo ratings yet
- 7.vital SignDocument44 pages7.vital SignRobiatulAdawiyahNo ratings yet
- L TEST SERIES - 4Document24 pagesL TEST SERIES - 4Dr-Sanjay SinghaniaNo ratings yet
- AurasDocument6 pagesAurasCarol CampbellNo ratings yet
- Amlodipine Drug StudyDocument2 pagesAmlodipine Drug StudyKevin Aliasas100% (3)
- Chest Pain Algorithm Clinical Case Scenarios PDF 243970669Document28 pagesChest Pain Algorithm Clinical Case Scenarios PDF 243970669Romelu MartialNo ratings yet
- Acute Coronary Syndrome (G4)Document6 pagesAcute Coronary Syndrome (G4)Francis Josh DagohoyNo ratings yet
- CIRCULANDocument5 pagesCIRCULANapi-3805007100% (2)
- 50 Emergency DrugsDocument70 pages50 Emergency DrugsderizNo ratings yet
- Ucs551 GRP ProjectDocument34 pagesUcs551 GRP ProjectmohdsaifullahsazukiNo ratings yet
- Prep U Exam #1 Adult 1Document14 pagesPrep U Exam #1 Adult 1Adriana RemedioNo ratings yet
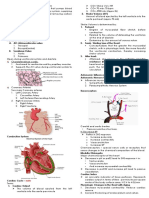
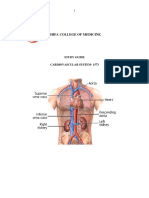
- Cardiovascular SystemDocument8 pagesCardiovascular SystemDawnmurph Dharlene Wag-eNo ratings yet
- AdrenalineDocument11 pagesAdrenalineAli AkhtarNo ratings yet
- Apply Medical First Aid On Board ShipDocument11 pagesApply Medical First Aid On Board ShipWosf TanagraNo ratings yet
- Pharmaceutical Care 5: Clinical Pharmacy Coronary Artery DiseaseDocument80 pagesPharmaceutical Care 5: Clinical Pharmacy Coronary Artery DiseaseJerson Aizpuro SuplementoNo ratings yet
- Pathology Ple SamplexDocument5 pagesPathology Ple SamplexdawnparkNo ratings yet
- Case Study With ECG Reading OcañaDocument3 pagesCase Study With ECG Reading OcañaNicole Chloe OcanaNo ratings yet
- Coronary Artery Revascularization in Stable Patients With Diabetes Mellitus - UpToDateDocument22 pagesCoronary Artery Revascularization in Stable Patients With Diabetes Mellitus - UpToDateAnca StanNo ratings yet
- Intro To Pharmacology Study GuideDocument93 pagesIntro To Pharmacology Study GuideMichelle Morgan LongstrethNo ratings yet
- CVS Study Guide 2023Document28 pagesCVS Study Guide 2023Muhammad SulamanNo ratings yet
- Mi 2Document8 pagesMi 2Aiman ArifinNo ratings yet
- Frenle Revie Np3 and Np4-1Document49 pagesFrenle Revie Np3 and Np4-1erjen gamingNo ratings yet
- Complete - OSCE - Skills - For Medical and Surgical FinalsDocument321 pagesComplete - OSCE - Skills - For Medical and Surgical FinalsSanjeewa de AlwisNo ratings yet
- Appropriate Use Criteria Coronary Angiogram 2012Document33 pagesAppropriate Use Criteria Coronary Angiogram 2012DanielTanNgNo ratings yet
- Athero 2 Dr. Raquid 2021Document93 pagesAthero 2 Dr. Raquid 2021oreaNo ratings yet
- Four Systems For Happy YogaDocument109 pagesFour Systems For Happy YogaAwanish PandeyNo ratings yet
- Nursing Care - Roxana BucurDocument40 pagesNursing Care - Roxana BucurMarin AndreiNo ratings yet
- DobutaminDocument15 pagesDobutaminInnocence AmandaNo ratings yet