
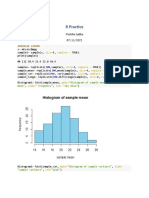
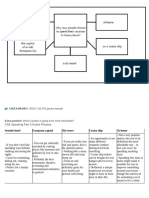
Introduction To Text Mining
Introduction To Text Mining
You might also like
- 03 - CT3S Introduction To Probability Simulation and Gibbs Sampling With R SolutionsDocument270 pages03 - CT3S Introduction To Probability Simulation and Gibbs Sampling With R SolutionsMatt O'Brien100% (1)
- HW4 Text-1Document8 pagesHW4 Text-1Utkarsh ShrivatavaNo ratings yet
- Assignment 2 PDFDocument25 pagesAssignment 2 PDFBoni HalderNo ratings yet
- Capstone Project Data ScienceDocument5 pagesCapstone Project Data SciencedangarciamNo ratings yet
- Genetics 2014 Dec 20 PDFDocument13 pagesGenetics 2014 Dec 20 PDFNico GoldbergNo ratings yet
- Assignment Unit 6Document5 pagesAssignment Unit 6Prakhar Pratap SinghNo ratings yet
- Content htf661Document14 pagesContent htf661Zzati Fida'iyNo ratings yet
- GuideToIRTinvarianceUsingMIRT (ANCHOR)Document10 pagesGuideToIRTinvarianceUsingMIRT (ANCHOR)Ampeh SarokNo ratings yet
- Python For Bioinformatics Cap 4Document16 pagesPython For Bioinformatics Cap 4celialove17No ratings yet
- BigMart PDFDocument42 pagesBigMart PDFjjbrothers creation100% (1)
- Lab 2 1Document5 pagesLab 2 1rishabh7aroraNo ratings yet
- Package Origami': R Topics DocumentedDocument10 pagesPackage Origami': R Topics DocumentedLuis De La Cruz PrietoNo ratings yet
- Ubc Opensees GuideDocument32 pagesUbc Opensees GuideSuyono NtNo ratings yet
- ANOVA in RDocument7 pagesANOVA in Rjubatus.libroNo ratings yet
- Python-Cheatsheet For PrintDocument44 pagesPython-Cheatsheet For PrintCartigayane KeingadaraneNo ratings yet
- JournalDev - How To Take The Samples Using SAMPLE in RDocument6 pagesJournalDev - How To Take The Samples Using SAMPLE in RSílvia AmadoriNo ratings yet
- R PracticeDocument38 pagesR PracticeyoshitaNo ratings yet
- Decision Making ToolsDocument21 pagesDecision Making Toolskaizen87No ratings yet
- Hyperparameter Tuning in XGBoost Using Genetic AlgorithmDocument11 pagesHyperparameter Tuning in XGBoost Using Genetic AlgorithmDubstar Prince Kaushik100% (1)
- Advanced Statistics Group AssignmentDocument7 pagesAdvanced Statistics Group AssignmentSimran SahaNo ratings yet
- An Extensive Step by Step Guide To Exploratory Data AnalysisDocument26 pagesAn Extensive Step by Step Guide To Exploratory Data AnalysisojeifoissyNo ratings yet
- Beginner Guide Matplotlib Data Visualization Exploration PythonDocument13 pagesBeginner Guide Matplotlib Data Visualization Exploration Pythonudayalugolu6363No ratings yet
- A - B Testing - Notes - PracticeDocument13 pagesA - B Testing - Notes - PracticeKrishna kurdekarNo ratings yet
- Natural Language ProcessingDocument22 pagesNatural Language Processingsandeepssn47No ratings yet
- ISYE 6501 Georgia Tech hmwk3.1bDocument5 pagesISYE 6501 Georgia Tech hmwk3.1baletiaNo ratings yet
- CSP Unit 7 Lesson 3 Ramen RadarDocument4 pagesCSP Unit 7 Lesson 3 Ramen Radarabdelrahmanadelm2008No ratings yet
- Package Itemanalysis': R Topics DocumentedDocument7 pagesPackage Itemanalysis': R Topics DocumentedJoko PurwantoNo ratings yet
- Sel FaqDocument33 pagesSel FaqHiranmay MohapatraNo ratings yet
- Script de InvernizziDocument26 pagesScript de InvernizziTeresa QuinteroNo ratings yet
- SE Lab ManualDocument73 pagesSE Lab ManualRajeev BansalNo ratings yet
- Practical Assignment-10 Mini Project Nutrition Calculator - Calculate Nutrition For RecipesDocument16 pagesPractical Assignment-10 Mini Project Nutrition Calculator - Calculate Nutrition For RecipesAbhinav aroraNo ratings yet
- RealSelf - SR Business Analyst Revenue - ExerciseDocument196 pagesRealSelf - SR Business Analyst Revenue - ExerciseBrianna CarterNo ratings yet
- R TutorialDocument11 pagesR Tutorialudhai170819No ratings yet
- CPSC 103 Midterm 2021W2Document13 pagesCPSC 103 Midterm 2021W2kimminwu12No ratings yet
- Nse 2 RDocument14 pagesNse 2 RSatyendra SaratNo ratings yet
- Python Cheat SheetDocument16 pagesPython Cheat SheetdfgeNo ratings yet
- Amazon Product Review - Ipynb - ColaboratoryDocument7 pagesAmazon Product Review - Ipynb - ColaboratoryThomas ShelbyNo ratings yet
- Package Genetics': R Topics DocumentedDocument43 pagesPackage Genetics': R Topics DocumentedmaniiiiiiiiNo ratings yet
- Machine Learning Chapter3Document27 pagesMachine Learning Chapter3Nesma AbdellatifNo ratings yet
- Data Mining Lab ManualDocument40 pagesData Mining Lab Manualxamogoy396No ratings yet
- R Intro STAT5000Document17 pagesR Intro STAT5000vinay kumarNo ratings yet
- ANPQP SPRINT6 PAT ScenariosDocument10 pagesANPQP SPRINT6 PAT Scenariosrajeevanand1991No ratings yet
- Tutorial For MarketingDocument10 pagesTutorial For MarketingNandkumar KhachaneNo ratings yet
- ExcelData2 FilterPivotDocument9 pagesExcelData2 FilterPivotJMFMNo ratings yet
- Video Notebook: Food Portion Size Per 100 Grams EnergyDocument28 pagesVideo Notebook: Food Portion Size Per 100 Grams EnergyAbdulkerim Sultan TemmamNo ratings yet
- S15 Bull TestDocument9 pagesS15 Bull Testpartha_665590810No ratings yet
- LGT 2106 Operation MGT (Yr1 Sem 2)Document42 pagesLGT 2106 Operation MGT (Yr1 Sem 2)CHUN HEI LUKNo ratings yet
- Software Testing Lab 1: DebuggingDocument15 pagesSoftware Testing Lab 1: DebuggingТолганай КыдырмоллаеваNo ratings yet
- Exercise 1. Establishing A Calibration Model Between SensoryDocument5 pagesExercise 1. Establishing A Calibration Model Between SensorybookmoonNo ratings yet
- 4 IntroToPython-ControlFlowStatementsDocument11 pages4 IntroToPython-ControlFlowStatementsHermine KouéNo ratings yet
- PowerShell Optimization and Performance TestingDocument3 pagesPowerShell Optimization and Performance Testingignacio fernandez luengoNo ratings yet
- Ansys ReportDocument34 pagesAnsys ReportTanu RdNo ratings yet
- Ancova in R HandoutDocument8 pagesAncova in R HandoutEduardoNo ratings yet
- Algo QuestionsDocument19 pagesAlgo QuestionsfashionpicksNo ratings yet
- Cakephp TestDocument22 pagesCakephp Testhathanh13No ratings yet
- Python: Advanced Guide to Programming Code with Python: Python Computer Programming, #4From EverandPython: Advanced Guide to Programming Code with Python: Python Computer Programming, #4No ratings yet
- Service Styles Presentation 5Document26 pagesService Styles Presentation 5cheskabiz1No ratings yet
- Unit21 DirectionsDocument35 pagesUnit21 DirectionsHoangLamNo ratings yet
- Session Plan ElynDocument2 pagesSession Plan ElynShiela Marie VergaraNo ratings yet
- Sant Chatwal AssignmentDocument3 pagesSant Chatwal Assignmentcezam486No ratings yet
- The Crumbs Bakery and Sweets: AbeehaDocument7 pagesThe Crumbs Bakery and Sweets: AbeehaMUHAMMAD MUDASSAR TAHIR NCBA&ENo ratings yet
- WORKSHEET 1 PRESENT SIMPLE English I, Rodrigo Torres MancillaDocument6 pagesWORKSHEET 1 PRESENT SIMPLE English I, Rodrigo Torres MancillaRoDoTorresMancillaNo ratings yet
- Succeed in LanguageCert - Level B2 - SELF-STUDY GUIDE-SAMPLE PAGESDocument3 pagesSucceed in LanguageCert - Level B2 - SELF-STUDY GUIDE-SAMPLE PAGESMeena JangraNo ratings yet
- Universidad Tecnologica de Honduras: Exercises. Campus: El Progreso, YoroDocument5 pagesUniversidad Tecnologica de Honduras: Exercises. Campus: El Progreso, YoroElizabeth RamirezNo ratings yet
- Unit 4 TestDocument9 pagesUnit 4 TestAlberto LuisNo ratings yet
- ĐỀ ÔN TẬPDocument8 pagesĐỀ ÔN TẬPLê Kế ThọNo ratings yet
- Soal Olimpiade BING 2019Document8 pagesSoal Olimpiade BING 20190nly XyzaaNo ratings yet
- Review Related LiteratureDocument9 pagesReview Related LiteratureNori Jayne Cosa RubisNo ratings yet
- A Pricing Strategy in Which A Company Prices ItsDocument2 pagesA Pricing Strategy in Which A Company Prices ItsBernadette BautistaNo ratings yet
- CAE Speaking Part 3, Set 4Document2 pagesCAE Speaking Part 3, Set 4Valentina lamannaNo ratings yet
- TRANSPORT HUB - Case StudyDocument28 pagesTRANSPORT HUB - Case StudySneha PatilNo ratings yet
- Chapter-1 Profile of Bikano (Bikanervala)Document16 pagesChapter-1 Profile of Bikano (Bikanervala)SachinGoelNo ratings yet
- УПРАЖНЕНИЯ НА PAST SIMPLEDocument7 pagesУПРАЖНЕНИЯ НА PAST SIMPLEКсения СомоваNo ratings yet
- Blog 3Document2 pagesBlog 3infinityNo ratings yet
- Kiara Di VeroliDocument2 pagesKiara Di Verolidylanmore1223No ratings yet
- The Bridge and Other Love StoriesDocument5 pagesThe Bridge and Other Love Storiesnurullahkokercun1No ratings yet
- Pie Chart (Food)Document3 pagesPie Chart (Food)khuyen phamNo ratings yet
- FCE CK Test 564Document6 pagesFCE CK Test 564Ngân Nguyễn ThiênNo ratings yet
- Grade 5 Pronouns Possessive Relative Indefinite ADocument2 pagesGrade 5 Pronouns Possessive Relative Indefinite AannabellNo ratings yet
- 16 13 77 16122015 170036Document2 pages16 13 77 16122015 170036Vaibhavraj NikamNo ratings yet
- Area-250 SQ.M Kitchen Area - 510 SQ.M Restaurant: SLOPE - 1:10Document1 pageArea-250 SQ.M Kitchen Area - 510 SQ.M Restaurant: SLOPE - 1:10mathivananNo ratings yet
- My Almost Flawless Tokyo Dream Life - Rachel CohnDocument218 pagesMy Almost Flawless Tokyo Dream Life - Rachel Cohnmomovlogs2020No ratings yet
- GR N Voc 7Document7 pagesGR N Voc 7K PrasadNo ratings yet
- Classification of HotelsDocument14 pagesClassification of HotelsJeevesh ViswambharanNo ratings yet
- Enrich Your VocabularyDocument3 pagesEnrich Your VocabularyEquipos GarciaNo ratings yet
























































































Download as pdf or txt
You might also like
- 03 - CT3S Introduction To Probability Simulation and Gibbs Sampling With R SolutionsDocument270 pages03 - CT3S Introduction To Probability Simulation and Gibbs Sampling With R SolutionsMatt O'Brien100% (1)
- HW4 Text-1Document8 pagesHW4 Text-1Utkarsh ShrivatavaNo ratings yet
- Assignment 2 PDFDocument25 pagesAssignment 2 PDFBoni HalderNo ratings yet
- Capstone Project Data ScienceDocument5 pagesCapstone Project Data SciencedangarciamNo ratings yet
- Genetics 2014 Dec 20 PDFDocument13 pagesGenetics 2014 Dec 20 PDFNico GoldbergNo ratings yet
- Assignment Unit 6Document5 pagesAssignment Unit 6Prakhar Pratap SinghNo ratings yet
- Content htf661Document14 pagesContent htf661Zzati Fida'iyNo ratings yet
- GuideToIRTinvarianceUsingMIRT (ANCHOR)Document10 pagesGuideToIRTinvarianceUsingMIRT (ANCHOR)Ampeh SarokNo ratings yet
- Python For Bioinformatics Cap 4Document16 pagesPython For Bioinformatics Cap 4celialove17No ratings yet
- BigMart PDFDocument42 pagesBigMart PDFjjbrothers creation100% (1)
- Lab 2 1Document5 pagesLab 2 1rishabh7aroraNo ratings yet
- Package Origami': R Topics DocumentedDocument10 pagesPackage Origami': R Topics DocumentedLuis De La Cruz PrietoNo ratings yet
- Ubc Opensees GuideDocument32 pagesUbc Opensees GuideSuyono NtNo ratings yet
- ANOVA in RDocument7 pagesANOVA in Rjubatus.libroNo ratings yet
- Python-Cheatsheet For PrintDocument44 pagesPython-Cheatsheet For PrintCartigayane KeingadaraneNo ratings yet
- JournalDev - How To Take The Samples Using SAMPLE in RDocument6 pagesJournalDev - How To Take The Samples Using SAMPLE in RSílvia AmadoriNo ratings yet
- R PracticeDocument38 pagesR PracticeyoshitaNo ratings yet
- Decision Making ToolsDocument21 pagesDecision Making Toolskaizen87No ratings yet
- Hyperparameter Tuning in XGBoost Using Genetic AlgorithmDocument11 pagesHyperparameter Tuning in XGBoost Using Genetic AlgorithmDubstar Prince Kaushik100% (1)
- Advanced Statistics Group AssignmentDocument7 pagesAdvanced Statistics Group AssignmentSimran SahaNo ratings yet
- An Extensive Step by Step Guide To Exploratory Data AnalysisDocument26 pagesAn Extensive Step by Step Guide To Exploratory Data AnalysisojeifoissyNo ratings yet
- Beginner Guide Matplotlib Data Visualization Exploration PythonDocument13 pagesBeginner Guide Matplotlib Data Visualization Exploration Pythonudayalugolu6363No ratings yet
- A - B Testing - Notes - PracticeDocument13 pagesA - B Testing - Notes - PracticeKrishna kurdekarNo ratings yet
- Natural Language ProcessingDocument22 pagesNatural Language Processingsandeepssn47No ratings yet
- ISYE 6501 Georgia Tech hmwk3.1bDocument5 pagesISYE 6501 Georgia Tech hmwk3.1baletiaNo ratings yet
- CSP Unit 7 Lesson 3 Ramen RadarDocument4 pagesCSP Unit 7 Lesson 3 Ramen Radarabdelrahmanadelm2008No ratings yet
- Package Itemanalysis': R Topics DocumentedDocument7 pagesPackage Itemanalysis': R Topics DocumentedJoko PurwantoNo ratings yet
- Sel FaqDocument33 pagesSel FaqHiranmay MohapatraNo ratings yet
- Script de InvernizziDocument26 pagesScript de InvernizziTeresa QuinteroNo ratings yet
- SE Lab ManualDocument73 pagesSE Lab ManualRajeev BansalNo ratings yet
- Practical Assignment-10 Mini Project Nutrition Calculator - Calculate Nutrition For RecipesDocument16 pagesPractical Assignment-10 Mini Project Nutrition Calculator - Calculate Nutrition For RecipesAbhinav aroraNo ratings yet
- RealSelf - SR Business Analyst Revenue - ExerciseDocument196 pagesRealSelf - SR Business Analyst Revenue - ExerciseBrianna CarterNo ratings yet
- R TutorialDocument11 pagesR Tutorialudhai170819No ratings yet
- CPSC 103 Midterm 2021W2Document13 pagesCPSC 103 Midterm 2021W2kimminwu12No ratings yet
- Nse 2 RDocument14 pagesNse 2 RSatyendra SaratNo ratings yet
- Python Cheat SheetDocument16 pagesPython Cheat SheetdfgeNo ratings yet
- Amazon Product Review - Ipynb - ColaboratoryDocument7 pagesAmazon Product Review - Ipynb - ColaboratoryThomas ShelbyNo ratings yet
- Package Genetics': R Topics DocumentedDocument43 pagesPackage Genetics': R Topics DocumentedmaniiiiiiiiNo ratings yet
- Machine Learning Chapter3Document27 pagesMachine Learning Chapter3Nesma AbdellatifNo ratings yet
- Data Mining Lab ManualDocument40 pagesData Mining Lab Manualxamogoy396No ratings yet
- R Intro STAT5000Document17 pagesR Intro STAT5000vinay kumarNo ratings yet
- ANPQP SPRINT6 PAT ScenariosDocument10 pagesANPQP SPRINT6 PAT Scenariosrajeevanand1991No ratings yet
- Tutorial For MarketingDocument10 pagesTutorial For MarketingNandkumar KhachaneNo ratings yet
- ExcelData2 FilterPivotDocument9 pagesExcelData2 FilterPivotJMFMNo ratings yet
- Video Notebook: Food Portion Size Per 100 Grams EnergyDocument28 pagesVideo Notebook: Food Portion Size Per 100 Grams EnergyAbdulkerim Sultan TemmamNo ratings yet
- S15 Bull TestDocument9 pagesS15 Bull Testpartha_665590810No ratings yet
- LGT 2106 Operation MGT (Yr1 Sem 2)Document42 pagesLGT 2106 Operation MGT (Yr1 Sem 2)CHUN HEI LUKNo ratings yet
- Software Testing Lab 1: DebuggingDocument15 pagesSoftware Testing Lab 1: DebuggingТолганай КыдырмоллаеваNo ratings yet
- Exercise 1. Establishing A Calibration Model Between SensoryDocument5 pagesExercise 1. Establishing A Calibration Model Between SensorybookmoonNo ratings yet
- 4 IntroToPython-ControlFlowStatementsDocument11 pages4 IntroToPython-ControlFlowStatementsHermine KouéNo ratings yet
- PowerShell Optimization and Performance TestingDocument3 pagesPowerShell Optimization and Performance Testingignacio fernandez luengoNo ratings yet
- Ansys ReportDocument34 pagesAnsys ReportTanu RdNo ratings yet
- Ancova in R HandoutDocument8 pagesAncova in R HandoutEduardoNo ratings yet
- Algo QuestionsDocument19 pagesAlgo QuestionsfashionpicksNo ratings yet
- Cakephp TestDocument22 pagesCakephp Testhathanh13No ratings yet
- Python: Advanced Guide to Programming Code with Python: Python Computer Programming, #4From EverandPython: Advanced Guide to Programming Code with Python: Python Computer Programming, #4No ratings yet
- Service Styles Presentation 5Document26 pagesService Styles Presentation 5cheskabiz1No ratings yet
- Unit21 DirectionsDocument35 pagesUnit21 DirectionsHoangLamNo ratings yet
- Session Plan ElynDocument2 pagesSession Plan ElynShiela Marie VergaraNo ratings yet
- Sant Chatwal AssignmentDocument3 pagesSant Chatwal Assignmentcezam486No ratings yet
- The Crumbs Bakery and Sweets: AbeehaDocument7 pagesThe Crumbs Bakery and Sweets: AbeehaMUHAMMAD MUDASSAR TAHIR NCBA&ENo ratings yet
- WORKSHEET 1 PRESENT SIMPLE English I, Rodrigo Torres MancillaDocument6 pagesWORKSHEET 1 PRESENT SIMPLE English I, Rodrigo Torres MancillaRoDoTorresMancillaNo ratings yet
- Succeed in LanguageCert - Level B2 - SELF-STUDY GUIDE-SAMPLE PAGESDocument3 pagesSucceed in LanguageCert - Level B2 - SELF-STUDY GUIDE-SAMPLE PAGESMeena JangraNo ratings yet
- Universidad Tecnologica de Honduras: Exercises. Campus: El Progreso, YoroDocument5 pagesUniversidad Tecnologica de Honduras: Exercises. Campus: El Progreso, YoroElizabeth RamirezNo ratings yet
- Unit 4 TestDocument9 pagesUnit 4 TestAlberto LuisNo ratings yet
- ĐỀ ÔN TẬPDocument8 pagesĐỀ ÔN TẬPLê Kế ThọNo ratings yet
- Soal Olimpiade BING 2019Document8 pagesSoal Olimpiade BING 20190nly XyzaaNo ratings yet
- Review Related LiteratureDocument9 pagesReview Related LiteratureNori Jayne Cosa RubisNo ratings yet
- A Pricing Strategy in Which A Company Prices ItsDocument2 pagesA Pricing Strategy in Which A Company Prices ItsBernadette BautistaNo ratings yet
- CAE Speaking Part 3, Set 4Document2 pagesCAE Speaking Part 3, Set 4Valentina lamannaNo ratings yet
- TRANSPORT HUB - Case StudyDocument28 pagesTRANSPORT HUB - Case StudySneha PatilNo ratings yet
- Chapter-1 Profile of Bikano (Bikanervala)Document16 pagesChapter-1 Profile of Bikano (Bikanervala)SachinGoelNo ratings yet
- УПРАЖНЕНИЯ НА PAST SIMPLEDocument7 pagesУПРАЖНЕНИЯ НА PAST SIMPLEКсения СомоваNo ratings yet
- Blog 3Document2 pagesBlog 3infinityNo ratings yet
- Kiara Di VeroliDocument2 pagesKiara Di Verolidylanmore1223No ratings yet
- The Bridge and Other Love StoriesDocument5 pagesThe Bridge and Other Love Storiesnurullahkokercun1No ratings yet
- Pie Chart (Food)Document3 pagesPie Chart (Food)khuyen phamNo ratings yet
- FCE CK Test 564Document6 pagesFCE CK Test 564Ngân Nguyễn ThiênNo ratings yet
- Grade 5 Pronouns Possessive Relative Indefinite ADocument2 pagesGrade 5 Pronouns Possessive Relative Indefinite AannabellNo ratings yet
- 16 13 77 16122015 170036Document2 pages16 13 77 16122015 170036Vaibhavraj NikamNo ratings yet
- Area-250 SQ.M Kitchen Area - 510 SQ.M Restaurant: SLOPE - 1:10Document1 pageArea-250 SQ.M Kitchen Area - 510 SQ.M Restaurant: SLOPE - 1:10mathivananNo ratings yet
- My Almost Flawless Tokyo Dream Life - Rachel CohnDocument218 pagesMy Almost Flawless Tokyo Dream Life - Rachel Cohnmomovlogs2020No ratings yet
- GR N Voc 7Document7 pagesGR N Voc 7K PrasadNo ratings yet
- Classification of HotelsDocument14 pagesClassification of HotelsJeevesh ViswambharanNo ratings yet
- Enrich Your VocabularyDocument3 pagesEnrich Your VocabularyEquipos GarciaNo ratings yet