Download as docx, pdf, or txt
You might also like
- Stats With PythonDocument4 pagesStats With PythonAyush Garg100% (3)
- AR Model Session2 Output: Install - Packages ("Forecast")Document30 pagesAR Model Session2 Output: Install - Packages ("Forecast")karthikmaddula007_66No ratings yet
- HW 1Document8 pagesHW 1Malik KhaledNo ratings yet
- YaDocument44 pagesYaapi-361356322No ratings yet
- ###Diagrama de Dispersión###Document7 pages###Diagrama de Dispersión###matiaNo ratings yet
- Problema 2.7 RDocument7 pagesProblema 2.7 RjuanaNo ratings yet
- Problema 2.3 RDocument6 pagesProblema 2.3 RjuanaNo ratings yet
- Euler Explicit Jan2024Document11 pagesEuler Explicit Jan2024getachewbonga09No ratings yet
- ExamenDocument7 pagesExamenOmar GuzmanNo ratings yet
- Pattern - Recognition - 3 - Code With OutputDocument7 pagesPattern - Recognition - 3 - Code With OutputReem NasserNo ratings yet
- # Experiment Name: Introduction To MATLABDocument10 pages# Experiment Name: Introduction To MATLABOmor Hasan Al BoshirNo ratings yet
- Chapter 5Document22 pagesChapter 5Rajat BansalNo ratings yet
- Notite Aplicatii-Matlab Master 2023Document12 pagesNotite Aplicatii-Matlab Master 2023Andrea AndreolliNo ratings yet
- Nama: Asnur Saputra NIM: F1A220034 Kelas: B Prodi: S1 StatistikaDocument7 pagesNama: Asnur Saputra NIM: F1A220034 Kelas: B Prodi: S1 StatistikaAsnur SaputraNo ratings yet
- ADADELTADocument2 pagesADADELTAAbdul Wajid HanjrahNo ratings yet
- Funkcje Bessela Najlepszy Art Z 1957Document3 pagesFunkcje Bessela Najlepszy Art Z 1957Baja BajabajasziNo ratings yet
- Uas Algoritma - Novera SafitriDocument3 pagesUas Algoritma - Novera SafitriNOVERA SAFITRINo ratings yet
- Uas Algoritma - Novera SafitriDocument3 pagesUas Algoritma - Novera SafitriNOVERA SAFITRINo ratings yet
- Kelompok 3 - Latihan 1 Setup Python Dan Aljabar LinierDocument12 pagesKelompok 3 - Latihan 1 Setup Python Dan Aljabar LinierSatrya Budi PratamaNo ratings yet
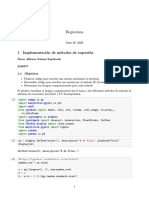
- Regression: 1 Implementación de Métodos de RegresiónDocument11 pagesRegression: 1 Implementación de Métodos de RegresiónÓscar Alfonso Gómez SepúlvedaNo ratings yet
- Selisih Mundur:: Nama: Taubat Nasukha NIM: 21060117130091 Kelas: CDocument4 pagesSelisih Mundur:: Nama: Taubat Nasukha NIM: 21060117130091 Kelas: Cabyan nNo ratings yet
- Matlab (By# Muhammad Usman Arshid) : Q#1 Command WindowDocument39 pagesMatlab (By# Muhammad Usman Arshid) : Q#1 Command Windowlaraib mirzaNo ratings yet
- Hasil Praktikum 5 AnregDocument15 pagesHasil Praktikum 5 AnregSitti Nur AgeNo ratings yet
- Q1 Gauss-Seidel Method ProgramDocument8 pagesQ1 Gauss-Seidel Method ProgramAhmed HwaidiNo ratings yet
- Kerr - Solve IvpDocument8 pagesKerr - Solve Ivpyulieth andrea ramirez romeroNo ratings yet
- MExer01 FinalDocument11 pagesMExer01 Finaljohannie ukaNo ratings yet
- Tarea 5Document6 pagesTarea 5Alejandra Hernández ValenzoNo ratings yet
- 2 and 3Document6 pages2 and 3Radhika KhandelwalNo ratings yet
- Assignment No 8Document17 pagesAssignment No 8264 HAMNA AMIRNo ratings yet
- Assign. No 1Document7 pagesAssign. No 1getachewbonga09No ratings yet
- Analisis Dinamico Eje XDocument24 pagesAnalisis Dinamico Eje XVICTOR MANUEL PAITAN MENDEZNo ratings yet
- Homework Assignment 3 Homework Assignment 3Document10 pagesHomework Assignment 3 Homework Assignment 3Ido AkovNo ratings yet
- HW 6.8,6.12Document5 pagesHW 6.8,6.12AlbertEngNo ratings yet
- Numpy PandasDocument20 pagesNumpy PandasAnish pandeyNo ratings yet
- Practical No 1 AimDocument17 pagesPractical No 1 AimPrachi BorlikarNo ratings yet
- Import As Import As From Import: "Mean Squared Errors: "Document1 pageImport As Import As From Import: "Mean Squared Errors: "ulNo ratings yet
- Stat 500 Assignment 1Document2 pagesStat 500 Assignment 1rahuls5No ratings yet
- Tutorial Pandas Bag-5Document11 pagesTutorial Pandas Bag-5NUR JAYANo ratings yet
- Salamander JagsDocument8 pagesSalamander Jagsapi-499791123No ratings yet
- Tasks A TreesDocument14 pagesTasks A TreesAmos Keli MutuaNo ratings yet
- '/content/data - PKL' 'RB': Open PrintDocument5 pages'/content/data - PKL' 'RB': Open PrintRavi KNo ratings yet
- K MeansDocument15 pagesK MeansJEISON ANDRES GOMEZ PEDRAZANo ratings yet
- R Package Diagram: Visualising Simple Graphs, Flowcharts, and WebsDocument20 pagesR Package Diagram: Visualising Simple Graphs, Flowcharts, and Websdjsavi69No ratings yet
- Gráficas en Matlab Y1 (T) X (4t+1) : FunctionDocument4 pagesGráficas en Matlab Y1 (T) X (4t+1) : FunctionHenry ANo ratings yet
- Python Course Cheat SheetDocument30 pagesPython Course Cheat SheetVinayNo ratings yet
- RDocument4 pagesRutsavp931No ratings yet
- Analisis Data Faktorial-Syifa Fauziyah-20180210175Document8 pagesAnalisis Data Faktorial-Syifa Fauziyah-20180210175wulandariNo ratings yet
- Control Systems Engineering D227 S.A.E. Solutions Tutorial 12 - Digital Systems Self Assessment Exercise No.1Document5 pagesControl Systems Engineering D227 S.A.E. Solutions Tutorial 12 - Digital Systems Self Assessment Exercise No.1cataiceNo ratings yet
- KakuDocument7 pagesKakuDivom SharmaNo ratings yet
- PythonDocument10 pagesPythonSaptangshu RoyNo ratings yet
- MatlfDocument3 pagesMatlfCarlos CabanillasNo ratings yet
- Tugas Analisa Numerik: Fakultas Teknik Jurusan Teknik Sipil Universitas Darma Agung 2019Document6 pagesTugas Analisa Numerik: Fakultas Teknik Jurusan Teknik Sipil Universitas Darma Agung 2019Rio MauritzNo ratings yet
- Introduc) On To MATLAB For Control Engineers: EE 447 Autumn 2008 Eric KlavinsDocument30 pagesIntroduc) On To MATLAB For Control Engineers: EE 447 Autumn 2008 Eric KlavinsChristina HillNo ratings yet
- MPPPS Chapter1Document35 pagesMPPPS Chapter1Umer IshfaqueNo ratings yet
- R For Machine Learning Lab Practical Work: Master of Business Administration in Business AnalyticsDocument9 pagesR For Machine Learning Lab Practical Work: Master of Business Administration in Business AnalyticsGishnu Raj0% (1)
- A2 RahilDocument5 pagesA2 Rahilharsh upadhyayNo ratings yet
- Function: % (Root Finding With Rootsearch)Document6 pagesFunction: % (Root Finding With Rootsearch)Madi YarokahaliNo ratings yet
- R Intro 2011Document115 pagesR Intro 2011marijkepauwelsNo ratings yet
- Parth Suryavanshi (231056) Practical No.1 To No.5Document37 pagesParth Suryavanshi (231056) Practical No.1 To No.5riyachendake007No ratings yet
- SOURCE CODE TelecomDocument30 pagesSOURCE CODE Telecompratik zankeNo ratings yet
- ###Diagrama de Dispersión###Document7 pages###Diagrama de Dispersión###matiaNo ratings yet
- Workbook Natural DisastersDocument2 pagesWorkbook Natural DisastersmatiaNo ratings yet
- EconomaticaDocument236 pagesEconomaticamatiaNo ratings yet
- EconomaticaDocument120 pagesEconomaticamatiaNo ratings yet
- FORMATO - ER - HA EfrainReyesBelloDocument47 pagesFORMATO - ER - HA EfrainReyesBellomatiaNo ratings yet
- Unit-Tech Savvy: Lic - Angela Patricia Berber PimentelDocument5 pagesUnit-Tech Savvy: Lic - Angela Patricia Berber PimentelmatiaNo ratings yet
- Spatial Econometrics With R 2020Document141 pagesSpatial Econometrics With R 2020Raquel Vargas CorreaNo ratings yet
- John Gless Cleof Nmtl01E - Finals ME 301 Activity 2Document2 pagesJohn Gless Cleof Nmtl01E - Finals ME 301 Activity 2Jay LumongsodNo ratings yet
- SC0x LiveEvent2 StatisticsDocument14 pagesSC0x LiveEvent2 StatisticsWellington SilvaNo ratings yet
- Chapter 4 QuizDocument2 pagesChapter 4 QuizMia KulalNo ratings yet
- IAP - Spring 2020 Course 6 - Electrical Engineering and Computer ScienceDocument34 pagesIAP - Spring 2020 Course 6 - Electrical Engineering and Computer Scienceswastik soniNo ratings yet
- Week 2 - Linear RegressionDocument5 pagesWeek 2 - Linear RegressionLuk Ee RenNo ratings yet
- One-Sample Hypothesis Test Examples: (Chapter 10)Document5 pagesOne-Sample Hypothesis Test Examples: (Chapter 10)Han MyoNo ratings yet
- Create Linear Regression Model Using Stepwise Regression - MATLAB Stepwiselm - MathWorks IndiaDocument15 pagesCreate Linear Regression Model Using Stepwise Regression - MATLAB Stepwiselm - MathWorks Indiaaaditya01No ratings yet
- Critical Analysis of Research Report and ArticalDocument18 pagesCritical Analysis of Research Report and Articaldivyani sonawaneNo ratings yet
- The Sign TestDocument12 pagesThe Sign TestRumaisyahNo ratings yet
- Essentials of Modern Business Statistics With Microsoft Office Excel 7th Edition Anderson Test Bank Full Chapter PDFDocument66 pagesEssentials of Modern Business Statistics With Microsoft Office Excel 7th Edition Anderson Test Bank Full Chapter PDFChristopherRosefpzt100% (13)
- Reading 7 Introduction To Linear Regression - AnswersDocument8 pagesReading 7 Introduction To Linear Regression - AnswersgddNo ratings yet
- ForesightDocument10 pagesForesightArunaNo ratings yet
- Assignment 5 PDFDocument4 pagesAssignment 5 PDFschoolgirl7796No ratings yet
- Multiple RegressionDocument30 pagesMultiple Regressionjagdip_barikNo ratings yet
- Correlation 140708105710 Phpapp01Document21 pagesCorrelation 140708105710 Phpapp01sara sibyNo ratings yet
- Simulation System Project ReportDocument36 pagesSimulation System Project ReportAlifa SalsabilaNo ratings yet
- Chapter 01 Data and StatisticsDocument44 pagesChapter 01 Data and StatisticsDieu TruongNo ratings yet
- 2023 Tutorial 11Document7 pages2023 Tutorial 11Đinh Thanh TrúcNo ratings yet
- Statisticspart2 Conf Int 2pDocument11 pagesStatisticspart2 Conf Int 2pNikuBotnariNo ratings yet
- Analysis and Assessment of FMCG Market of IndiaDocument36 pagesAnalysis and Assessment of FMCG Market of Indiaalokjain1987100% (1)
- Data Hasil Pengujian Organoleptik Uji Hedonik Produk Dendeng Daging Sapi (Excell)Document11 pagesData Hasil Pengujian Organoleptik Uji Hedonik Produk Dendeng Daging Sapi (Excell)Rizki Aulia NuzullinaNo ratings yet
- Survival Analysis. Techniques For Censored and Truncated Data (2Nd Ed.)Document3 pagesSurvival Analysis. Techniques For Censored and Truncated Data (2Nd Ed.)irsadNo ratings yet
- ADocument6 pagesAmariacastro2323No ratings yet
- Unit2-Regression NGPDocument81 pagesUnit2-Regression NGPanimehv5500No ratings yet
- Chapter 5 AnovaDocument10 pagesChapter 5 AnovaMuhd NaimNo ratings yet
- Kementerian Kesehatan Politeknik Kesehatan Surakarta Jurusan FisioterapiDocument8 pagesKementerian Kesehatan Politeknik Kesehatan Surakarta Jurusan FisioterapikhairinazulfahNo ratings yet
- A Case Study of TanzaniaDocument15 pagesA Case Study of TanzaniaVladGrigoreNo ratings yet