
Introduction To The Soar Cognitive Architecture
Introduction To The Soar Cognitive Architecture
You might also like
- Implementing The MindDocument23 pagesImplementing The MindJarar ShahNo ratings yet
- Agent Architecture-Final Form - 409Document7 pagesAgent Architecture-Final Form - 409Ubiquitous Computing and Communication JournalNo ratings yet
- Toward Cognitive Robotics: Proceedings of SPIE - The International Society For Optical Engineering May 2009Document12 pagesToward Cognitive Robotics: Proceedings of SPIE - The International Society For Optical Engineering May 2009Shamo Ha-RyoNo ratings yet
- Paper 8-Segment, Track, Extract, Recognize and Convert Sign Language Videos To VoiceTextDocument13 pagesPaper 8-Segment, Track, Extract, Recognize and Convert Sign Language Videos To VoiceTextEditor IJACSANo ratings yet
- Rabeeya Arshad, FA17-BPY-034 Final PaperDocument11 pagesRabeeya Arshad, FA17-BPY-034 Final PaperRabeeya ArshadNo ratings yet
- Neural TuringDocument194 pagesNeural TuringIamINNo ratings yet
- Robot With A Sense of SelfDocument7 pagesRobot With A Sense of Selfdingsda1980No ratings yet
- Aiked 35Document6 pagesAiked 35kareemaa589No ratings yet
- DALI: An Architecture For Intelligent Logical Agents: Stefania Costantini and Arianna TocchioDocument6 pagesDALI: An Architecture For Intelligent Logical Agents: Stefania Costantini and Arianna Tocchiobhavin24uNo ratings yet
- A Cognitive Neuroscience Perspective On Embodied Language - 2010 - Brain and LaDocument9 pagesA Cognitive Neuroscience Perspective On Embodied Language - 2010 - Brain and Lamaria arambulaNo ratings yet
- Design Patterns IntroductionDocument285 pagesDesign Patterns IntroductionMintishu TemesgenzNo ratings yet
- One FormerDocument19 pagesOne FormerYi-Chen ChenNo ratings yet
- Speechanimation fcs2020Document13 pagesSpeechanimation fcs2020ryl0903No ratings yet
- Universidade Nova de Lisboa: Introduction To Kohonen's Self-Organizing MapsDocument22 pagesUniversidade Nova de Lisboa: Introduction To Kohonen's Self-Organizing MapsYuri BrasilkaNo ratings yet
- W16 3628 PDFDocument4 pagesW16 3628 PDFMohammed MusharrifNo ratings yet
- A Model For Real Time Sign Language Recognition SystemDocument7 pagesA Model For Real Time Sign Language Recognition Systemeditor_ijarcsseNo ratings yet
- Deep Reniforcement Leanring PaperDocument13 pagesDeep Reniforcement Leanring PaperAnika TasnimNo ratings yet
- Report CS Elective 1 Group 1Document52 pagesReport CS Elective 1 Group 1Meky QuiranteNo ratings yet
- OneFormer: One Transformer To Rule Universal Image SegmentationDocument18 pagesOneFormer: One Transformer To Rule Universal Image SegmentationYann SkiderNo ratings yet
- INCOSE IW09-MBSE - Initiative - SysMO - (d01FEB09-aRH-v1.4-sFINAL)Document42 pagesINCOSE IW09-MBSE - Initiative - SysMO - (d01FEB09-aRH-v1.4-sFINAL)Ralph HodgsonNo ratings yet
- CorsiDocument19 pagesCorsishanNo ratings yet
- Speech Emotion Recognition: Methods and Cases Study: January 2018Document9 pagesSpeech Emotion Recognition: Methods and Cases Study: January 2018nehaNo ratings yet
- 1 s2.0 S1877050915036595 MainDocument6 pages1 s2.0 S1877050915036595 MainjoaonitNo ratings yet
- The Final UmlDocument107 pagesThe Final Umlujjwalbhujel333No ratings yet
- The Deep Learning Revolution: Introductory Overview LectureDocument35 pagesThe Deep Learning Revolution: Introductory Overview LectureAnji M ReddyNo ratings yet
- Object-Oriented Programming ConceptsDocument9 pagesObject-Oriented Programming ConceptsRemi-RolandOladayoRolandNo ratings yet
- Object-Oriented Programming in AI: Guest Editors'Document2 pagesObject-Oriented Programming in AI: Guest Editors'Hernan Rivera CabezaNo ratings yet
- Baddley's Working MemoryDocument5 pagesBaddley's Working MemoryavakkNo ratings yet
- Suffix Trees No Longer Considered Harmful: Zerge Zita and Kis G EzaDocument5 pagesSuffix Trees No Longer Considered Harmful: Zerge Zita and Kis G Ezaanon_586378449No ratings yet
- Activity Diagram LectureDocument19 pagesActivity Diagram LectureNouf AlRumaihNo ratings yet
- "Smart" Models: Abu and AbuDocument5 pages"Smart" Models: Abu and AbuAbuNo ratings yet
- Semi-Supervised Recursive Autoencoders For Predicting Sentiment DistributionsDocument11 pagesSemi-Supervised Recursive Autoencoders For Predicting Sentiment Distributionsشروق الغامديNo ratings yet
- The Fourth International Conference On Artificial Intelligence and Pattern Recognition (AIPR2017)Document105 pagesThe Fourth International Conference On Artificial Intelligence and Pattern Recognition (AIPR2017)SDIWC PublicationsNo ratings yet
- Ai FinalDocument52 pagesAi FinalMadni FareedNo ratings yet
- PGCON Paper FinalDocument4 pagesPGCON Paper FinalArbaaz ShaikhNo ratings yet
- AI Principles, Semester 2,, Biological Intelligence IIDocument24 pagesAI Principles, Semester 2,, Biological Intelligence IIIan Ray DughoNo ratings yet
- Meeting The Computer Halfway: Language Processing in The Artificial Language LojbanDocument3 pagesMeeting The Computer Halfway: Language Processing in The Artificial Language LojbanSoyoko U.No ratings yet
- Artificial Intelligence Cat 2Document8 pagesArtificial Intelligence Cat 2Frankline RickyNo ratings yet
- A Cognitive Approach To Solve Water Jugs Problem: Divya Saxena Naveen Kumar Malik V.R. SinghDocument10 pagesA Cognitive Approach To Solve Water Jugs Problem: Divya Saxena Naveen Kumar Malik V.R. SinghKhalil AfghanNo ratings yet
- Web 1st PracticalDocument7 pagesWeb 1st PracticalDhanraj DeoreNo ratings yet
- ASPIRE Ontology Workspace andDocument20 pagesASPIRE Ontology Workspace andghirbach24No ratings yet
- Sifferman 2022 ArxivDocument23 pagesSifferman 2022 ArxivYan AecNo ratings yet
- Automatic Language Acquisition by An Autonomous Robot: August 2003Document7 pagesAutomatic Language Acquisition by An Autonomous Robot: August 2003Dan Djari HarounaNo ratings yet
- International Journal of Research Publication and ReviewsDocument7 pagesInternational Journal of Research Publication and ReviewsSharan Teja KasulaNo ratings yet
- Vehicl ManagementDocument12 pagesVehicl ManagementkaveeshaNo ratings yet
- Neuro-Symbolic Artificial Intelligence: Current TrendsDocument11 pagesNeuro-Symbolic Artificial Intelligence: Current Trendsn1234567890987654321No ratings yet
- Chapter 7Document15 pagesChapter 7نور هادي حمودNo ratings yet
- Learning Deep Architectures For AI - Yoshua BengioDocument130 pagesLearning Deep Architectures For AI - Yoshua BengioJohn Jairo SilvaNo ratings yet
- 1 s2.0 S0896627314008514 MainDocument8 pages1 s2.0 S0896627314008514 MainKatospiegelNo ratings yet
- Code2vec Learning Distributed Representations of CodeDocument30 pagesCode2vec Learning Distributed Representations of CodeaaabbaaabbNo ratings yet
- Deep Visual-Semantic Alignments For Generating Image DescriptionsDocument14 pagesDeep Visual-Semantic Alignments For Generating Image DescriptionsRAGURAM SHANMUGAMNo ratings yet
- FinalDocument28 pagesFinalKowshik PonugotiNo ratings yet
- Recurrent Convolutional Neural Networks For Text ClassificationDocument7 pagesRecurrent Convolutional Neural Networks For Text ClassificationAditya ThakkerNo ratings yet
- Working Memory Memory and Psychology Case StudyDocument10 pagesWorking Memory Memory and Psychology Case StudyFelicia NikeNo ratings yet
- "Conscious" Multi-Modal Perceptual Learning For Grounded Simulation-Based CognitionDocument7 pages"Conscious" Multi-Modal Perceptual Learning For Grounded Simulation-Based CognitionShalini GuptaNo ratings yet
- Enrico Pagello: Intelligent Autonomous System Laboratory (IAS-Lab) University of Padua, ItalyDocument13 pagesEnrico Pagello: Intelligent Autonomous System Laboratory (IAS-Lab) University of Padua, Italyanon_864995No ratings yet
- Introduction to Cognitive Science: Cognitive Processing of Visual Design Elements In Virtual EnvironmentsFrom EverandIntroduction to Cognitive Science: Cognitive Processing of Visual Design Elements In Virtual EnvironmentsNo ratings yet
- System Verilog Assertions and Functional Coverage: Guide to Language, Methodology and ApplicationsFrom EverandSystem Verilog Assertions and Functional Coverage: Guide to Language, Methodology and ApplicationsNo ratings yet
- Cognitive Architectures and Multi-Agent Social SimulationDocument15 pagesCognitive Architectures and Multi-Agent Social SimulationisraaNo ratings yet
- MMC 4Document51 pagesMMC 4israaNo ratings yet
- An Agent Based Model To Analyze The Effect of Ambivalent Opinion Leaders in Social NetworksDocument47 pagesAn Agent Based Model To Analyze The Effect of Ambivalent Opinion Leaders in Social NetworksisraaNo ratings yet
- Common's Behavior Social DilemmasDocument9 pagesCommon's Behavior Social DilemmasisraaNo ratings yet
- A Deep Learning Cognitive Architecture - Towards A Unified Theory of CognitionDocument17 pagesA Deep Learning Cognitive Architecture - Towards A Unified Theory of CognitionisraaNo ratings yet
- Environmental ParticipationDocument112 pagesEnvironmental ParticipationisraaNo ratings yet
- OAF Training MaterialDocument92 pagesOAF Training MaterialBalaji ShindeNo ratings yet
- Opinion Mining and Sentiment Analysis in An Online Lending ForumDocument16 pagesOpinion Mining and Sentiment Analysis in An Online Lending Forumvishalmate10No ratings yet
- Boost TrieDocument20 pagesBoost TrieEmil24No ratings yet
- 7300 LDocument126 pages7300 LSantiago Cabarcas L. de UrquizoNo ratings yet
- TEC B-470 Maintenance ManualDocument196 pagesTEC B-470 Maintenance Manual-TT-No ratings yet
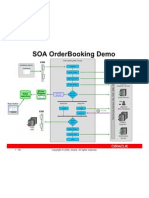
- So A Demo ArchitectureDocument1 pageSo A Demo ArchitecturebirvahNo ratings yet
- IQ Interactive Education Platform V6.0 User ManualDocument40 pagesIQ Interactive Education Platform V6.0 User ManualJulian TabaresNo ratings yet
- Controlling Playback Speed in VLC Media PlayerDocument11 pagesControlling Playback Speed in VLC Media PlayerAnonymous ywBDhvXZFMNo ratings yet
- Complete Guten Berg WebDocument177 pagesComplete Guten Berg WebddfteyegghhNo ratings yet
- GeneralDocument27 pagesGeneralverma_ravinderNo ratings yet
- Isa IntroductionDocument31 pagesIsa IntroductionspwajeehNo ratings yet
- S86T GPS Receiver User GuideDocument54 pagesS86T GPS Receiver User GuideGalih Yudha Wahyu Saputra100% (1)
- SFDC UAP Customized Cognizant Curriculum (52 Modules)Document4 pagesSFDC UAP Customized Cognizant Curriculum (52 Modules)Manimegalai ArunachalamNo ratings yet
- Brood Lord-Unit Description - Game - StarCraft IIDocument8 pagesBrood Lord-Unit Description - Game - StarCraft IIcalmansoorNo ratings yet
- PF Theory Course OutlineDocument8 pagesPF Theory Course OutlineKhadija MüghålNo ratings yet
- Unit 1 To 5 (2016)Document163 pagesUnit 1 To 5 (2016)Sumathy JayaramNo ratings yet
- 1756 rm087 - en PDocument6 pages1756 rm087 - en PjesusortegavNo ratings yet
- Pivot Table Formulas Before PowerpivotDocument6 pagesPivot Table Formulas Before PowerpivotAziz Khan LodhiNo ratings yet
- ReleaseNote FileList of GL703GS WIN10 64 V2.03Document3 pagesReleaseNote FileList of GL703GS WIN10 64 V2.03danielvasilievNo ratings yet
- Active ConnectionsDocument6 pagesActive ConnectionsMaricicaNo ratings yet
- Desma Corporate Catalogue 2014Document20 pagesDesma Corporate Catalogue 2014Jigar M. Upadhyay100% (2)
- SQL To Pyspark ConversionDocument9 pagesSQL To Pyspark Conversionyikogoy117No ratings yet
- Scilab, Xcos NITKDocument6 pagesScilab, Xcos NITKrachitmehraNo ratings yet
- MySQL Data Types & MyDocument34 pagesMySQL Data Types & MydummyNo ratings yet
- Database Programming With PL - SQL 2019 Learner - English-MergedDocument4 pagesDatabase Programming With PL - SQL 2019 Learner - English-MergedMuhammad AkbarNo ratings yet
- 02 Path ActionDocument18 pages02 Path ActionJesus MedinaNo ratings yet
- Rajavardhan UTMIDocument69 pagesRajavardhan UTMIRajavardhan_Re_6459No ratings yet
- Database ReferenceDocument2,464 pagesDatabase ReferenceTiomon Mon Tiomon MonNo ratings yet
- Pub QuizDocument4 pagesPub QuizVan YangNo ratings yet
- Client Needs and Software Requirements V2.2Document43 pagesClient Needs and Software Requirements V2.2Mehmet DemirezNo ratings yet





























































































Download as pdf or txt
You might also like
- Implementing The MindDocument23 pagesImplementing The MindJarar ShahNo ratings yet
- Agent Architecture-Final Form - 409Document7 pagesAgent Architecture-Final Form - 409Ubiquitous Computing and Communication JournalNo ratings yet
- Toward Cognitive Robotics: Proceedings of SPIE - The International Society For Optical Engineering May 2009Document12 pagesToward Cognitive Robotics: Proceedings of SPIE - The International Society For Optical Engineering May 2009Shamo Ha-RyoNo ratings yet
- Paper 8-Segment, Track, Extract, Recognize and Convert Sign Language Videos To VoiceTextDocument13 pagesPaper 8-Segment, Track, Extract, Recognize and Convert Sign Language Videos To VoiceTextEditor IJACSANo ratings yet
- Rabeeya Arshad, FA17-BPY-034 Final PaperDocument11 pagesRabeeya Arshad, FA17-BPY-034 Final PaperRabeeya ArshadNo ratings yet
- Neural TuringDocument194 pagesNeural TuringIamINNo ratings yet
- Robot With A Sense of SelfDocument7 pagesRobot With A Sense of Selfdingsda1980No ratings yet
- Aiked 35Document6 pagesAiked 35kareemaa589No ratings yet
- DALI: An Architecture For Intelligent Logical Agents: Stefania Costantini and Arianna TocchioDocument6 pagesDALI: An Architecture For Intelligent Logical Agents: Stefania Costantini and Arianna Tocchiobhavin24uNo ratings yet
- A Cognitive Neuroscience Perspective On Embodied Language - 2010 - Brain and LaDocument9 pagesA Cognitive Neuroscience Perspective On Embodied Language - 2010 - Brain and Lamaria arambulaNo ratings yet
- Design Patterns IntroductionDocument285 pagesDesign Patterns IntroductionMintishu TemesgenzNo ratings yet
- One FormerDocument19 pagesOne FormerYi-Chen ChenNo ratings yet
- Speechanimation fcs2020Document13 pagesSpeechanimation fcs2020ryl0903No ratings yet
- Universidade Nova de Lisboa: Introduction To Kohonen's Self-Organizing MapsDocument22 pagesUniversidade Nova de Lisboa: Introduction To Kohonen's Self-Organizing MapsYuri BrasilkaNo ratings yet
- W16 3628 PDFDocument4 pagesW16 3628 PDFMohammed MusharrifNo ratings yet
- A Model For Real Time Sign Language Recognition SystemDocument7 pagesA Model For Real Time Sign Language Recognition Systemeditor_ijarcsseNo ratings yet
- Deep Reniforcement Leanring PaperDocument13 pagesDeep Reniforcement Leanring PaperAnika TasnimNo ratings yet
- Report CS Elective 1 Group 1Document52 pagesReport CS Elective 1 Group 1Meky QuiranteNo ratings yet
- OneFormer: One Transformer To Rule Universal Image SegmentationDocument18 pagesOneFormer: One Transformer To Rule Universal Image SegmentationYann SkiderNo ratings yet
- INCOSE IW09-MBSE - Initiative - SysMO - (d01FEB09-aRH-v1.4-sFINAL)Document42 pagesINCOSE IW09-MBSE - Initiative - SysMO - (d01FEB09-aRH-v1.4-sFINAL)Ralph HodgsonNo ratings yet
- CorsiDocument19 pagesCorsishanNo ratings yet
- Speech Emotion Recognition: Methods and Cases Study: January 2018Document9 pagesSpeech Emotion Recognition: Methods and Cases Study: January 2018nehaNo ratings yet
- 1 s2.0 S1877050915036595 MainDocument6 pages1 s2.0 S1877050915036595 MainjoaonitNo ratings yet
- The Final UmlDocument107 pagesThe Final Umlujjwalbhujel333No ratings yet
- The Deep Learning Revolution: Introductory Overview LectureDocument35 pagesThe Deep Learning Revolution: Introductory Overview LectureAnji M ReddyNo ratings yet
- Object-Oriented Programming ConceptsDocument9 pagesObject-Oriented Programming ConceptsRemi-RolandOladayoRolandNo ratings yet
- Object-Oriented Programming in AI: Guest Editors'Document2 pagesObject-Oriented Programming in AI: Guest Editors'Hernan Rivera CabezaNo ratings yet
- Baddley's Working MemoryDocument5 pagesBaddley's Working MemoryavakkNo ratings yet
- Suffix Trees No Longer Considered Harmful: Zerge Zita and Kis G EzaDocument5 pagesSuffix Trees No Longer Considered Harmful: Zerge Zita and Kis G Ezaanon_586378449No ratings yet
- Activity Diagram LectureDocument19 pagesActivity Diagram LectureNouf AlRumaihNo ratings yet
- "Smart" Models: Abu and AbuDocument5 pages"Smart" Models: Abu and AbuAbuNo ratings yet
- Semi-Supervised Recursive Autoencoders For Predicting Sentiment DistributionsDocument11 pagesSemi-Supervised Recursive Autoencoders For Predicting Sentiment Distributionsشروق الغامديNo ratings yet
- The Fourth International Conference On Artificial Intelligence and Pattern Recognition (AIPR2017)Document105 pagesThe Fourth International Conference On Artificial Intelligence and Pattern Recognition (AIPR2017)SDIWC PublicationsNo ratings yet
- Ai FinalDocument52 pagesAi FinalMadni FareedNo ratings yet
- PGCON Paper FinalDocument4 pagesPGCON Paper FinalArbaaz ShaikhNo ratings yet
- AI Principles, Semester 2,, Biological Intelligence IIDocument24 pagesAI Principles, Semester 2,, Biological Intelligence IIIan Ray DughoNo ratings yet
- Meeting The Computer Halfway: Language Processing in The Artificial Language LojbanDocument3 pagesMeeting The Computer Halfway: Language Processing in The Artificial Language LojbanSoyoko U.No ratings yet
- Artificial Intelligence Cat 2Document8 pagesArtificial Intelligence Cat 2Frankline RickyNo ratings yet
- A Cognitive Approach To Solve Water Jugs Problem: Divya Saxena Naveen Kumar Malik V.R. SinghDocument10 pagesA Cognitive Approach To Solve Water Jugs Problem: Divya Saxena Naveen Kumar Malik V.R. SinghKhalil AfghanNo ratings yet
- Web 1st PracticalDocument7 pagesWeb 1st PracticalDhanraj DeoreNo ratings yet
- ASPIRE Ontology Workspace andDocument20 pagesASPIRE Ontology Workspace andghirbach24No ratings yet
- Sifferman 2022 ArxivDocument23 pagesSifferman 2022 ArxivYan AecNo ratings yet
- Automatic Language Acquisition by An Autonomous Robot: August 2003Document7 pagesAutomatic Language Acquisition by An Autonomous Robot: August 2003Dan Djari HarounaNo ratings yet
- International Journal of Research Publication and ReviewsDocument7 pagesInternational Journal of Research Publication and ReviewsSharan Teja KasulaNo ratings yet
- Vehicl ManagementDocument12 pagesVehicl ManagementkaveeshaNo ratings yet
- Neuro-Symbolic Artificial Intelligence: Current TrendsDocument11 pagesNeuro-Symbolic Artificial Intelligence: Current Trendsn1234567890987654321No ratings yet
- Chapter 7Document15 pagesChapter 7نور هادي حمودNo ratings yet
- Learning Deep Architectures For AI - Yoshua BengioDocument130 pagesLearning Deep Architectures For AI - Yoshua BengioJohn Jairo SilvaNo ratings yet
- 1 s2.0 S0896627314008514 MainDocument8 pages1 s2.0 S0896627314008514 MainKatospiegelNo ratings yet
- Code2vec Learning Distributed Representations of CodeDocument30 pagesCode2vec Learning Distributed Representations of CodeaaabbaaabbNo ratings yet
- Deep Visual-Semantic Alignments For Generating Image DescriptionsDocument14 pagesDeep Visual-Semantic Alignments For Generating Image DescriptionsRAGURAM SHANMUGAMNo ratings yet
- FinalDocument28 pagesFinalKowshik PonugotiNo ratings yet
- Recurrent Convolutional Neural Networks For Text ClassificationDocument7 pagesRecurrent Convolutional Neural Networks For Text ClassificationAditya ThakkerNo ratings yet
- Working Memory Memory and Psychology Case StudyDocument10 pagesWorking Memory Memory and Psychology Case StudyFelicia NikeNo ratings yet
- "Conscious" Multi-Modal Perceptual Learning For Grounded Simulation-Based CognitionDocument7 pages"Conscious" Multi-Modal Perceptual Learning For Grounded Simulation-Based CognitionShalini GuptaNo ratings yet
- Enrico Pagello: Intelligent Autonomous System Laboratory (IAS-Lab) University of Padua, ItalyDocument13 pagesEnrico Pagello: Intelligent Autonomous System Laboratory (IAS-Lab) University of Padua, Italyanon_864995No ratings yet
- Introduction to Cognitive Science: Cognitive Processing of Visual Design Elements In Virtual EnvironmentsFrom EverandIntroduction to Cognitive Science: Cognitive Processing of Visual Design Elements In Virtual EnvironmentsNo ratings yet
- System Verilog Assertions and Functional Coverage: Guide to Language, Methodology and ApplicationsFrom EverandSystem Verilog Assertions and Functional Coverage: Guide to Language, Methodology and ApplicationsNo ratings yet
- Cognitive Architectures and Multi-Agent Social SimulationDocument15 pagesCognitive Architectures and Multi-Agent Social SimulationisraaNo ratings yet
- MMC 4Document51 pagesMMC 4israaNo ratings yet
- An Agent Based Model To Analyze The Effect of Ambivalent Opinion Leaders in Social NetworksDocument47 pagesAn Agent Based Model To Analyze The Effect of Ambivalent Opinion Leaders in Social NetworksisraaNo ratings yet
- Common's Behavior Social DilemmasDocument9 pagesCommon's Behavior Social DilemmasisraaNo ratings yet
- A Deep Learning Cognitive Architecture - Towards A Unified Theory of CognitionDocument17 pagesA Deep Learning Cognitive Architecture - Towards A Unified Theory of CognitionisraaNo ratings yet
- Environmental ParticipationDocument112 pagesEnvironmental ParticipationisraaNo ratings yet
- OAF Training MaterialDocument92 pagesOAF Training MaterialBalaji ShindeNo ratings yet
- Opinion Mining and Sentiment Analysis in An Online Lending ForumDocument16 pagesOpinion Mining and Sentiment Analysis in An Online Lending Forumvishalmate10No ratings yet
- Boost TrieDocument20 pagesBoost TrieEmil24No ratings yet
- 7300 LDocument126 pages7300 LSantiago Cabarcas L. de UrquizoNo ratings yet
- TEC B-470 Maintenance ManualDocument196 pagesTEC B-470 Maintenance Manual-TT-No ratings yet
- So A Demo ArchitectureDocument1 pageSo A Demo ArchitecturebirvahNo ratings yet
- IQ Interactive Education Platform V6.0 User ManualDocument40 pagesIQ Interactive Education Platform V6.0 User ManualJulian TabaresNo ratings yet
- Controlling Playback Speed in VLC Media PlayerDocument11 pagesControlling Playback Speed in VLC Media PlayerAnonymous ywBDhvXZFMNo ratings yet
- Complete Guten Berg WebDocument177 pagesComplete Guten Berg WebddfteyegghhNo ratings yet
- GeneralDocument27 pagesGeneralverma_ravinderNo ratings yet
- Isa IntroductionDocument31 pagesIsa IntroductionspwajeehNo ratings yet
- S86T GPS Receiver User GuideDocument54 pagesS86T GPS Receiver User GuideGalih Yudha Wahyu Saputra100% (1)
- SFDC UAP Customized Cognizant Curriculum (52 Modules)Document4 pagesSFDC UAP Customized Cognizant Curriculum (52 Modules)Manimegalai ArunachalamNo ratings yet
- Brood Lord-Unit Description - Game - StarCraft IIDocument8 pagesBrood Lord-Unit Description - Game - StarCraft IIcalmansoorNo ratings yet
- PF Theory Course OutlineDocument8 pagesPF Theory Course OutlineKhadija MüghålNo ratings yet
- Unit 1 To 5 (2016)Document163 pagesUnit 1 To 5 (2016)Sumathy JayaramNo ratings yet
- 1756 rm087 - en PDocument6 pages1756 rm087 - en PjesusortegavNo ratings yet
- Pivot Table Formulas Before PowerpivotDocument6 pagesPivot Table Formulas Before PowerpivotAziz Khan LodhiNo ratings yet
- ReleaseNote FileList of GL703GS WIN10 64 V2.03Document3 pagesReleaseNote FileList of GL703GS WIN10 64 V2.03danielvasilievNo ratings yet
- Active ConnectionsDocument6 pagesActive ConnectionsMaricicaNo ratings yet
- Desma Corporate Catalogue 2014Document20 pagesDesma Corporate Catalogue 2014Jigar M. Upadhyay100% (2)
- SQL To Pyspark ConversionDocument9 pagesSQL To Pyspark Conversionyikogoy117No ratings yet
- Scilab, Xcos NITKDocument6 pagesScilab, Xcos NITKrachitmehraNo ratings yet
- MySQL Data Types & MyDocument34 pagesMySQL Data Types & MydummyNo ratings yet
- Database Programming With PL - SQL 2019 Learner - English-MergedDocument4 pagesDatabase Programming With PL - SQL 2019 Learner - English-MergedMuhammad AkbarNo ratings yet
- 02 Path ActionDocument18 pages02 Path ActionJesus MedinaNo ratings yet
- Rajavardhan UTMIDocument69 pagesRajavardhan UTMIRajavardhan_Re_6459No ratings yet
- Database ReferenceDocument2,464 pagesDatabase ReferenceTiomon Mon Tiomon MonNo ratings yet
- Pub QuizDocument4 pagesPub QuizVan YangNo ratings yet
- Client Needs and Software Requirements V2.2Document43 pagesClient Needs and Software Requirements V2.2Mehmet DemirezNo ratings yet