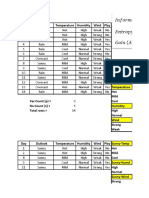
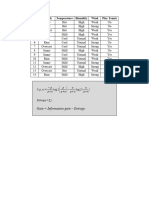
Download as pdf or txt
You might also like
- Prof Ed ReviewerDocument40 pagesProf Ed ReviewerVina100% (1)
- Ghana Livestock Development Policy and Strategy FinalDocument107 pagesGhana Livestock Development Policy and Strategy FinalGodsonNo ratings yet
- An Overview of Decision Tree LearningDocument34 pagesAn Overview of Decision Tree LearningBenazirNo ratings yet
- First Rule - Major RuleDocument3 pagesFirst Rule - Major RuleErik LampeNo ratings yet
- Data Mining: Classification-1Document53 pagesData Mining: Classification-1Nirmal RNo ratings yet
- Out GameDocument1 pageOut Gamemateuszpopek1234No ratings yet
- Module 4 Question Bank: Big Data AnalyticsDocument2 pagesModule 4 Question Bank: Big Data AnalyticsKaushik KapsNo ratings yet
- VENUS - Exercise 2Document2 pagesVENUS - Exercise 2Stella Mariz VenusNo ratings yet
- Bayes Algorithm: Ex1Document8 pagesBayes Algorithm: Ex1Thao PhamNo ratings yet
- I 24 Nov 2023 Lab Exam Questions MaterialDocument2 pagesI 24 Nov 2023 Lab Exam Questions Materialthirdmail2021No ratings yet
- Data Mining: Practical Machine Learning Tools and TechniquesDocument57 pagesData Mining: Practical Machine Learning Tools and TechniquesArvindNo ratings yet
- SWE485 - Assignment 2 - 45-2Document2 pagesSWE485 - Assignment 2 - 45-2lay22nNo ratings yet
- Decision Trees Example ProblemDocument1 pageDecision Trees Example ProblemMuneeb ButtNo ratings yet
- Decision TreeDocument6 pagesDecision TreeshubhNo ratings yet
- HAI C-06 Jueves 15-10-2020Document34 pagesHAI C-06 Jueves 15-10-2020lizandro verdugo viegasNo ratings yet
- Datos Jugar TenisDocument1 pageDatos Jugar TenisBrayan RoseroNo ratings yet
- Play Tennis Example: Outlook Temperature Humidity WindyDocument29 pagesPlay Tennis Example: Outlook Temperature Humidity Windyioi123No ratings yet
- 05 ZeroR OneR Bayes KNNDocument76 pages05 ZeroR OneR Bayes KNNsidra shafiqNo ratings yet
- A Step by Step ID3 Decision Tree Example by Niranjan Kumar DasDocument8 pagesA Step by Step ID3 Decision Tree Example by Niranjan Kumar DasNiranjan Kumar DasNo ratings yet
- Outlook Temperature Humidity Windy Play: AS 0.0206 0.0053 Hence Play NoDocument1 pageOutlook Temperature Humidity Windy Play: AS 0.0206 0.0053 Hence Play NoHarshali PatilNo ratings yet
- Naive BayesDocument4 pagesNaive Bayesbhavya.purohit81No ratings yet
- Dataset 1 and 2Document1 pageDataset 1 and 2shirisha gowdaNo ratings yet
- Decision Tree Calculation For Play ExampleDocument10 pagesDecision Tree Calculation For Play ExampleParthraj SolankiNo ratings yet
- MLA NLP Lecture2Document76 pagesMLA NLP Lecture2shubham choudharyNo ratings yet
- Decision Trees For Classification - A Machine Learning Algorithm - XoriantDocument4 pagesDecision Trees For Classification - A Machine Learning Algorithm - Xoriantmaanav8098No ratings yet
- L10 AnnDocument15 pagesL10 AnnNo OneNo ratings yet
- Session XIVDocument30 pagesSession XIVRupaliVajpayeeNo ratings yet
- Lec5 ActivitiesDocument1 pageLec5 Activitiestin nguyenNo ratings yet
- Decision Tree - ID3Document11 pagesDecision Tree - ID3Eman NaeemNo ratings yet
- ML LabDocument9 pagesML Labvgovinda36No ratings yet
- Decision TreeDocument5 pagesDecision TreePriyanka pawarNo ratings yet
- Outlook Temp Humidity Windy PlayDocument17 pagesOutlook Temp Humidity Windy PlaySarfarazNo ratings yet
- Decision TreesDocument52 pagesDecision TreeslailaNo ratings yet
- Classification and Regression Trees (CART)Document6 pagesClassification and Regression Trees (CART)Pravin PanduNo ratings yet
- LINFO2262: Decision Trees + Random Forests: Pierre DupontDocument43 pagesLINFO2262: Decision Trees + Random Forests: Pierre DupontQuentin LambotteNo ratings yet
- Naïve Bayes Classifier AlgorithmDocument10 pagesNaïve Bayes Classifier Algorithmbhavana vashishthaNo ratings yet
- Classification Models-IntuitionDocument17 pagesClassification Models-IntuitionAninda DuttaNo ratings yet
- Describe The WeatherDocument4 pagesDescribe The WeatherMaría de Guadalupe Castillo QuirozNo ratings yet
- Laboratory 1 Intro To Machine Learning 1Document3 pagesLaboratory 1 Intro To Machine Learning 1Emmanuel AncenoNo ratings yet
- Decision Tree and CartDocument6 pagesDecision Tree and CartMonisha JoseNo ratings yet
- Id 3Document1 pageId 3vuhp1000No ratings yet
- Aiml Assignment 2Document2 pagesAiml Assignment 2Gem StonesNo ratings yet
- Naïve Bayes Classifier AlgorithmDocument3 pagesNaïve Bayes Classifier AlgorithmHead Of Department Computer Science and EngineeringNo ratings yet
- Data Mining All SlidesDocument206 pagesData Mining All SlidesAmanat ConstructionNo ratings yet
- L4Document19 pagesL4ebrahimsarhan13No ratings yet
- Data Mining and Warehousing: Arijit SenguptaDocument60 pagesData Mining and Warehousing: Arijit Senguptaエバン スミドNo ratings yet
- NaiveDocument10 pagesNaiveNashowanNo ratings yet
- 7-Decision Trees LearningDocument51 pages7-Decision Trees Learningyshu1No ratings yet
- Decision Tree.10.11Document31 pagesDecision Tree.10.11Oindrila SanyalNo ratings yet
- AEWODocument38 pagesAEWOAmelia Bayu RamadhanisNo ratings yet
- Naive BayesDocument7 pagesNaive BayesfirozNo ratings yet
- GolfDocument3 pagesGolfSlamet AchwandiNo ratings yet
- ML - Unit 2Document15 pagesML - Unit 2HamsiNo ratings yet
- Decision Trees Iterative Dichotomiser 3 (ID3) For Classification: An ML AlgorithmDocument7 pagesDecision Trees Iterative Dichotomiser 3 (ID3) For Classification: An ML AlgorithmMohammad SharifNo ratings yet
- ML Unit IvDocument17 pagesML Unit Ivsnikhath20No ratings yet
- Lecture 19 - Decision TressDocument21 pagesLecture 19 - Decision Tressbscs-20f-0009No ratings yet
- Tide Times and Charts For Bushehr, Iran and Weather Forecast For Fishing in Bushehr in 2021Document1 pageTide Times and Charts For Bushehr, Iran and Weather Forecast For Fishing in Bushehr in 2021alireza khoshnoodNo ratings yet
- Csis355 Classifications 1Document70 pagesCsis355 Classifications 1AzerMušinovićNo ratings yet
- Association Rules: Apriori Algorithm. Prof. Carolina Ruiz, WPIDocument2 pagesAssociation Rules: Apriori Algorithm. Prof. Carolina Ruiz, WPIChristine CheongNo ratings yet
- Data Mining: Practical Machine Learning Tools and TechniquesDocument111 pagesData Mining: Practical Machine Learning Tools and TechniquesHenry YugoNo ratings yet
- Association Rules L3Document5 pagesAssociation Rules L3u- m-No ratings yet
- 1 2 NodeJSDocument141 pages1 2 NodeJShạnhNo ratings yet
- 1 1 Http-ApiDocument74 pages1 1 Http-ApihạnhNo ratings yet
- Hệ thống quản lý bệnh viện ngoại trúDocument2 pagesHệ thống quản lý bệnh viện ngoại trúhạnhNo ratings yet
- 5 Dectree-EnDocument48 pages5 Dectree-EnhạnhNo ratings yet
- 9 Clustering-EnDocument36 pages9 Clustering-EnhạnhNo ratings yet
- VLSMDocument10 pagesVLSMhạnhNo ratings yet
- 8 Svm-EnDocument71 pages8 Svm-EnhạnhNo ratings yet
- 2 Knn-EnDocument24 pages2 Knn-EnhạnhNo ratings yet
- 3 Eval-EnDocument19 pages3 Eval-EnhạnhNo ratings yet
- Baitap 6Document1 pageBaitap 6hạnhNo ratings yet
- 1 Intro-EnDocument43 pages1 Intro-EnhạnhNo ratings yet
- Chapter 1 The Entrepreneurial PerspectiveDocument26 pagesChapter 1 The Entrepreneurial PerspectiveYaseni WilliamsNo ratings yet
- Knimbus and Jgate ComparisonDocument3 pagesKnimbus and Jgate ComparisonMahesh Wagh100% (1)
- Kalhar To Jalsu TrainDocument1 pageKalhar To Jalsu TrainatewarigrNo ratings yet
- RT Vol. 10, No. 3 The Perfect MarriageDocument1 pageRT Vol. 10, No. 3 The Perfect MarriageRice TodayNo ratings yet
- A New Fair-Value Model For Bitcoin - SEBA BANCO SEBA SUIZA VALOR DE CRIPTOMONEDA PDFDocument15 pagesA New Fair-Value Model For Bitcoin - SEBA BANCO SEBA SUIZA VALOR DE CRIPTOMONEDA PDFnicolasNo ratings yet
- Employee Hand Book GTZDocument105 pagesEmployee Hand Book GTZAabha GaurNo ratings yet
- QuestionnaireDocument3 pagesQuestionnaireBrigette Kim LumawasNo ratings yet
- BIR PenaltiesDocument12 pagesBIR PenaltiesMark VillaverdeNo ratings yet
- Numerical Reasoning Test1 QuestionsDocument19 pagesNumerical Reasoning Test1 Questionscorporateboy36596No ratings yet
- A Review of Methods For Burstleakage Detection andDocument13 pagesA Review of Methods For Burstleakage Detection andalaaagala248No ratings yet
- Manual CPC PDFDocument36 pagesManual CPC PDFEric Costa100% (2)
- The MatrixDocument16 pagesThe MatrixPablo Antonio Martínez FernándezNo ratings yet
- NLUJLR-Blog Calls For SubmissionsDocument2 pagesNLUJLR-Blog Calls For SubmissionsAbhijat SinghNo ratings yet
- OECSwceDocument12 pagesOECSwceChristopher WeeksNo ratings yet
- Roundown Pesta Rakyat SimpedesDocument6 pagesRoundown Pesta Rakyat SimpedesCAHYANTO 96No ratings yet
- SoumyaDocument3 pagesSoumyaapi-3747004100% (1)
- Human Embryonic DevelopmentDocument24 pagesHuman Embryonic Developmentrobin100% (3)
- AOR List Supreme Court PDFDocument359 pagesAOR List Supreme Court PDFप्रदीप मिश्र100% (1)
- GX120 GX160 GX200: Engine Adjustment InformationDocument1 pageGX120 GX160 GX200: Engine Adjustment Informationjac marchandNo ratings yet
- Bankruptcy Weapons To Terminate A Zombie MortgageDocument37 pagesBankruptcy Weapons To Terminate A Zombie MortgageValerie Lopez100% (2)
- Answer Key Langfocus Vocab Two StarsDocument9 pagesAnswer Key Langfocus Vocab Two StarsBekaNo ratings yet
- Preview Activity (I) : Hyperloop. Discuss What You Know About It. Can You Explain How It May Work?Document6 pagesPreview Activity (I) : Hyperloop. Discuss What You Know About It. Can You Explain How It May Work?Lucky TaurusNo ratings yet
- 1 Ladder/Manhole Access DesignDocument6 pages1 Ladder/Manhole Access DesignGanesh AdityaNo ratings yet
- Political Obligation ProjectDocument23 pagesPolitical Obligation ProjectRadheyNo ratings yet
- Naplan 2013 Final Test Numeracy Year 9 (Calculator)Document13 pagesNaplan 2013 Final Test Numeracy Year 9 (Calculator)Mohammad AliNo ratings yet
- Kalmin 100 Plus Wiith Neck Down SleevesDocument9 pagesKalmin 100 Plus Wiith Neck Down SleevesBhushan TanavdeNo ratings yet
- Unbalanced Transportation ProblemDocument7 pagesUnbalanced Transportation ProblemJojo ContiNo ratings yet
- Nitotile Grout PDFDocument2 pagesNitotile Grout PDFJong Dollente Jr.No ratings yet