Download as pdf or txt
You might also like
- Libro Dyadic Data Analysis PDFDocument480 pagesLibro Dyadic Data Analysis PDFLu100% (1)
- 2018 AP Chem MOCK FRQ FROM B Score GuideDocument15 pages2018 AP Chem MOCK FRQ FROM B Score GuideLena Nikiforov100% (1)
- Models, Theory & Systems Analysis in GeographyDocument33 pagesModels, Theory & Systems Analysis in GeographyAniruddha SinghalNo ratings yet
- Project Proposal On Dairy FarmDocument26 pagesProject Proposal On Dairy Farmvector dairy88% (8)
- Accounting and Finance For ManagersDocument322 pagesAccounting and Finance For ManagersPrasanna Aravindan100% (5)
- KH-HO - NG-MAI-CH - NH - 1.xlsx Filename UTF-8''KH-HOÀNG-MAI-CH - NHÀ-1Document549 pagesKH-HO - NG-MAI-CH - NH - 1.xlsx Filename UTF-8''KH-HOÀNG-MAI-CH - NHÀ-1Lê Minh TuânNo ratings yet
- Ecta 200522Document26 pagesEcta 200522George OyukeNo ratings yet
- Philosophies 05 00002 v2 PDFDocument12 pagesPhilosophies 05 00002 v2 PDFJuan RamirezNo ratings yet
- What Are The Most Important Statistical Ideas of The Past 50 Years?Document21 pagesWhat Are The Most Important Statistical Ideas of The Past 50 Years?Sounak SadhukhanNo ratings yet
- What Are The Most Important Statistical Ideas of The Past 50 YearsDocument12 pagesWhat Are The Most Important Statistical Ideas of The Past 50 Years595250651No ratings yet
- 2019 Deep Learning Pre PrintsDocument14 pages2019 Deep Learning Pre Prints潘石尧No ratings yet
- What Are The Most Important Statistical Ideas of The Past 50 Years?Document19 pagesWhat Are The Most Important Statistical Ideas of The Past 50 Years?No12n533No ratings yet
- Smaldino CommentaryOnAlmaatouqEtAl PreprintDocument3 pagesSmaldino CommentaryOnAlmaatouqEtAl Preprintyrm yrmNo ratings yet
- Towards A Reflexive Digital Data AnalysisDocument10 pagesTowards A Reflexive Digital Data AnalysisJulia BelinskyNo ratings yet
- Disaster World: Decision-Theoretic Agents For Simulating Population Responses To HurricanesDocument34 pagesDisaster World: Decision-Theoretic Agents For Simulating Population Responses To HurricanesLuis Fernando ZhininNo ratings yet
- Combining Quantitative and Qualitative Approaches in Poverty AnalysisDocument12 pagesCombining Quantitative and Qualitative Approaches in Poverty Analysismilanslavkovic9660No ratings yet
- BookofwhyreviewdocumentDocument9 pagesBookofwhyreviewdocumentJoshua AryampaNo ratings yet
- Pearl 2021 - The Causal Foundations of Structural Equattion ModelingDocument40 pagesPearl 2021 - The Causal Foundations of Structural Equattion ModelingPabloNeudörferNo ratings yet
- Counter FDocument13 pagesCounter FAlejandra ParraNo ratings yet
- Causality and Statistical Learning (Andrew Gelman)Document12 pagesCausality and Statistical Learning (Andrew Gelman)kekeNo ratings yet
- Novak 2021 Mathematical ModelingDocument35 pagesNovak 2021 Mathematical ModelingazuredianNo ratings yet
- Causation, Prediction, and Search: Second EditionDocument567 pagesCausation, Prediction, and Search: Second EditionNikash Subedi100% (1)
- Mello 2021 GUP CH 4Document29 pagesMello 2021 GUP CH 4saadisheraziNo ratings yet
- A Proposal For An Innovative Approach To Extended Modelling Cycles Incorporating Problem-Posing From A Creativity PerspectiveDocument7 pagesA Proposal For An Innovative Approach To Extended Modelling Cycles Incorporating Problem-Posing From A Creativity PerspectiveIJAR JOURNALNo ratings yet
- 2020 - Target Article Lack of Theory Building and Testing Impedes Progress in The Factor and Network LiteratureDocument19 pages2020 - Target Article Lack of Theory Building and Testing Impedes Progress in The Factor and Network LiteraturelocoflorezNo ratings yet
- A New Kind of Social Science: The Path Beyond Current (IR) Methodologies May Lie Beneath ThemDocument65 pagesA New Kind of Social Science: The Path Beyond Current (IR) Methodologies May Lie Beneath Themgiani_2008No ratings yet
- Scott-Cunningham-Causal-Inference-2020 TERCERA PARTEDocument22 pagesScott-Cunningham-Causal-Inference-2020 TERCERA PARTEAndrés LeonardoNo ratings yet
- What Can Mathematical Modelling Contribute To A Sociology of QuantificationDocument8 pagesWhat Can Mathematical Modelling Contribute To A Sociology of Quantificationbrooke.tizzyNo ratings yet
- Paul Lazarsfeld - Evidence and Inference in Social ResearchDocument33 pagesPaul Lazarsfeld - Evidence and Inference in Social ResearchLuis GarridoNo ratings yet
- Applying Critical Realism in Qualitative Research Methodology Meets MethodDocument15 pagesApplying Critical Realism in Qualitative Research Methodology Meets Methodsebastiao_est3197No ratings yet
- Fdata 05 989469Document17 pagesFdata 05 989469septapumaNo ratings yet
- Realist MethodologyDocument29 pagesRealist MethodologyAliNo ratings yet
- 001 Small Ns and Big ConclusionsDocument14 pages001 Small Ns and Big ConclusionsjoseNo ratings yet
- Pre PrintDocument36 pagesPre PrintDouglas GodoyNo ratings yet
- Boolean Literature ReviewDocument7 pagesBoolean Literature Reviewafdtyfnid100% (1)
- Lindley (2001) The Philosophy of StatisticsDocument45 pagesLindley (2001) The Philosophy of Statisticsbky.teachNo ratings yet
- ED573364Document8 pagesED573364Arleth CruzNo ratings yet
- Curry, A, y Schultz, W. Roads Less Travelled - Different - Methods - DDocument26 pagesCurry, A, y Schultz, W. Roads Less Travelled - Different - Methods - DBtc CryptoNo ratings yet
- Card (2021) - Design Based Research in Empirical MicroeconomicsDocument13 pagesCard (2021) - Design Based Research in Empirical MicroeconomicsArtika SinhaNo ratings yet
- Unsupervised by Any Other Name - Hidden Layers of Knowledge Production in Artificial Intelligence On Social MediaDocument11 pagesUnsupervised by Any Other Name - Hidden Layers of Knowledge Production in Artificial Intelligence On Social MediaJames WilsonNo ratings yet
- Do Mathematicians Agree About Mathematical BeautyDocument27 pagesDo Mathematicians Agree About Mathematical BeautyPo Hung LiuNo ratings yet
- Thesis On Scale DevelopmentDocument6 pagesThesis On Scale Developmentbsfp46eh100% (1)
- Master Thesis VubDocument7 pagesMaster Thesis Vubfc2fqg8j100% (2)
- LiebersonDocument15 pagesLiebersonMeruyert MussamadinovaNo ratings yet
- Outline 04Document6 pagesOutline 04api-3773589No ratings yet
- Qualitative and Quantitative Methods in Religious Studies: Heinz StreibDocument45 pagesQualitative and Quantitative Methods in Religious Studies: Heinz StreibKate BrownNo ratings yet
- For A Better Understanding of CausalityDocument6 pagesFor A Better Understanding of CausalityDirencNo ratings yet
- Lieberson 1991Document14 pagesLieberson 1991Isabel M. FontanotNo ratings yet
- Research About ResearchDocument8 pagesResearch About ResearchJohnny BravoNo ratings yet
- MiniLiteratureReview onNHST v4Document26 pagesMiniLiteratureReview onNHST v4John XieNo ratings yet
- The Level of Analysis Problem. SingerDocument17 pagesThe Level of Analysis Problem. Singerdianalr25No ratings yet
- Lee Butavicius ReillyDocument35 pagesLee Butavicius ReillynorbertscribdNo ratings yet
- On The Problem of Relevance in Statistical Infe - 2021 - Econometrics and StatisDocument17 pagesOn The Problem of Relevance in Statistical Infe - 2021 - Econometrics and StatisDANY CREATIONSNo ratings yet
- This Content Downloaded From 195.101.43.237 On Sun, 03 Oct 2021 06:56:26 UTCDocument25 pagesThis Content Downloaded From 195.101.43.237 On Sun, 03 Oct 2021 06:56:26 UTCGudeta KebedeNo ratings yet
- ALM226 - 1-Theories and Models What They Are What They Are For and What They Are AboutDocument10 pagesALM226 - 1-Theories and Models What They Are What They Are For and What They Are AboutChristine Mae SamsonNo ratings yet
- 2 - Unmasking The Privacy ParadoxDocument10 pages2 - Unmasking The Privacy ParadoxDr. Gaurav YadavNo ratings yet
- Journal of Theoretical Biology: Justin T. Mark, Brian B. Marion, Donald D. HoffmanDocument12 pagesJournal of Theoretical Biology: Justin T. Mark, Brian B. Marion, Donald D. HoffmanRyan J JonesNo ratings yet
- A Note On "Causality: Models, Reasoning, and Inference" by Judea PearlDocument4 pagesA Note On "Causality: Models, Reasoning, and Inference" by Judea PearlJose LorenzoNo ratings yet
- Methods and Tools For Causal Discovery and CausalDocument39 pagesMethods and Tools For Causal Discovery and Causalabu.hurr.80No ratings yet
- Kozlowoski, Joseph. 2019Document37 pagesKozlowoski, Joseph. 2019DWIKINo ratings yet
- A Prospective On Mathematics and Artificial Intelligence: Problem Solving Modeling + Theorem Proving Harvey J. GreenbergDocument5 pagesA Prospective On Mathematics and Artificial Intelligence: Problem Solving Modeling + Theorem Proving Harvey J. GreenbergAvighan MajumderNo ratings yet
- The Presentation of The Networked Self Ethics and Epistemology in SocialDocument9 pagesThe Presentation of The Networked Self Ethics and Epistemology in SocialDannielJosseAlvarezzMojicaaXDNo ratings yet
- Mathison - Why TriangulateDocument5 pagesMathison - Why TriangulateGrace Zhu ManyunNo ratings yet
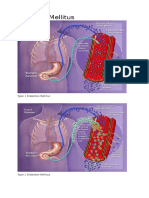
- Acute. KetoacidosisdocxDocument12 pagesAcute. KetoacidosisdocxShara SampangNo ratings yet
- 2023 MS P2 Al Statistics Zimsec Tuks and MR ShareDocument29 pages2023 MS P2 Al Statistics Zimsec Tuks and MR SharerudomposiNo ratings yet
- Chess PrinciplesDocument11 pagesChess PrinciplesNick PerilNo ratings yet
- Stat 116Document7 pagesStat 116oguzdagciNo ratings yet
- Fitel S199M24 Spec SheetDocument1 pageFitel S199M24 Spec SheetcolinyNo ratings yet
- WP1088 - DCMA 14 Point PDFDocument7 pagesWP1088 - DCMA 14 Point PDFpaspargiliusNo ratings yet
- Apron An Apron Is A Garment That Is Worn Over Other Clothing and Covers Mainly The Front of The BodyDocument3 pagesApron An Apron Is A Garment That Is Worn Over Other Clothing and Covers Mainly The Front of The BodyMicahDelaCruzCuatronaNo ratings yet
- MBA Course StructureDocument2 pagesMBA Course StructureAnupama JampaniNo ratings yet
- What Is A Real Estate Investment Trust?: AreitisaDocument45 pagesWhat Is A Real Estate Investment Trust?: AreitisakoosNo ratings yet
- Didactic ProductHighlights 2020 v2.6Document20 pagesDidactic ProductHighlights 2020 v2.6agus prasetioNo ratings yet
- ResMed CPAP-2012Document23 pagesResMed CPAP-2012navnaNo ratings yet
- Reactivity Series Homework Worksheet LADocument4 pagesReactivity Series Homework Worksheet LAkevinzhao704No ratings yet
- Final Report: Simulation Using Star CCM+ Theory and Practice in Marine CFD BenaoeDocument10 pagesFinal Report: Simulation Using Star CCM+ Theory and Practice in Marine CFD BenaoeRaviindra singhNo ratings yet
- The Perfection of The Narcissistic Self A Qualitative Study On Luxury Consumption and Customer EquityDocument7 pagesThe Perfection of The Narcissistic Self A Qualitative Study On Luxury Consumption and Customer EquityPablo Castro SalgadoNo ratings yet
- Ge 4.500HP PDFDocument3 pagesGe 4.500HP PDFCarlos FiorilloNo ratings yet
- Essay On Flood in PakistanDocument6 pagesEssay On Flood in Pakistanjvscmacaf100% (2)
- Case CX TrainingDocument20 pagesCase CX Traininghoward100% (27)
- The State of Structural Engineering in The US - IDEA StatiCaDocument6 pagesThe State of Structural Engineering in The US - IDEA StatiCaluisNo ratings yet
- Experiments in Art and Technology A Brief History and Summary of Major Projects 1966 - 1998Document12 pagesExperiments in Art and Technology A Brief History and Summary of Major Projects 1966 - 1998mate maricNo ratings yet
- Color Powder Color ChartDocument4 pagesColor Powder Color ChartArif RusyanaNo ratings yet
- Ielts Listening Section 4 40 Practice TestsDocument41 pagesIelts Listening Section 4 40 Practice TestsRajinder Singh Kahlon100% (1)
- ION-Evolution - ERA PANOS-RSDocument29 pagesION-Evolution - ERA PANOS-RSSokratesNo ratings yet
- Environmental Protection and Awareness Project ProposalDocument14 pagesEnvironmental Protection and Awareness Project ProposalRUS SELLNo ratings yet
- Ra 8294Document2 pagesRa 8294Rio TolentinoNo ratings yet
- Archer T5E (UN) - 1.0 Datasheet PDFDocument4 pagesArcher T5E (UN) - 1.0 Datasheet PDFeeerakeshNo ratings yet
- A Court Case On Letters of Credit & UCP600Document2 pagesA Court Case On Letters of Credit & UCP600gmat1287No ratings yet