
Ch2 - Fundamental of Deep Learning
Ch2 - Fundamental of Deep Learning
You might also like
- OUP - Just Click For The CaribbeanDocument292 pagesOUP - Just Click For The CaribbeanDemetre ford100% (1)
- Aci Card and Merchant Management Solutions Product Line Flyer FL Us 0711 4795 PDFDocument4 pagesAci Card and Merchant Management Solutions Product Line Flyer FL Us 0711 4795 PDFRazib ZoyNo ratings yet
- Ch4 - Multilayer PerceptronDocument26 pagesCh4 - Multilayer PerceptronĐặng Anh KhoaNo ratings yet
- Pattern Recognition Using Neural Network (Project Proposal For Image Processing)Document6 pagesPattern Recognition Using Neural Network (Project Proposal For Image Processing)Dil Prasad KunwarNo ratings yet
- Amansoftcomp PDFDocument27 pagesAmansoftcomp PDFas6858732No ratings yet
- Lab Manual On Soft Computing (IT-802) : Ms. Neha SexanaDocument29 pagesLab Manual On Soft Computing (IT-802) : Ms. Neha SexanaAdarsh SrivastavaNo ratings yet
- INT305 Machine Learning Linear Methods For Regression, OptimizationDocument50 pagesINT305 Machine Learning Linear Methods For Regression, OptimizationSheng HuangNo ratings yet
- Machine Learning Part 9Document33 pagesMachine Learning Part 9Sujit KumarNo ratings yet
- Neural Networks: Learning: Cost FunctionDocument33 pagesNeural Networks: Learning: Cost FunctionLydia DarlaNo ratings yet
- RELU and OthersDocument19 pagesRELU and OthersPRATIK GANGAPURWALANo ratings yet
- AIML - 04 Single Layer PerceptronDocument11 pagesAIML - 04 Single Layer PerceptronUMANG PEDNEKARNo ratings yet
- Ch.02 Modeling in Frequency Domain - AssignmentDocument5 pagesCh.02 Modeling in Frequency Domain - AssignmentThảo Đặng Ngọc ThanhNo ratings yet
- Discussion 4 Multiclass ClassificationDocument15 pagesDiscussion 4 Multiclass ClassificationLê Nguyễn Quang MinhNo ratings yet
- Machine Learning Week 3Document4 pagesMachine Learning Week 3AnandhsNo ratings yet
- Sheet #6 Ensemble + Neural Nets + Linear Regression + Backpropagation + CNNDocument4 pagesSheet #6 Ensemble + Neural Nets + Linear Regression + Backpropagation + CNNrowaida elsayedNo ratings yet
- Experiment-3: Convolution: Signals and Systems Lab (EC2P002)Document4 pagesExperiment-3: Convolution: Signals and Systems Lab (EC2P002)GAUTAM BUBNANo ratings yet
- Experiment-3: Convolution: Signals and Systems Lab (EC2P002)Document4 pagesExperiment-3: Convolution: Signals and Systems Lab (EC2P002)GAUTAM BUBNANo ratings yet
- Ai 7Document41 pagesAi 7saharkamal7274No ratings yet
- Backpropagation Learning in Neural NetworksDocument27 pagesBackpropagation Learning in Neural NetworksPooja PatwariNo ratings yet
- Deep Feedforward Networks and Regularization: Licheng ZhangDocument56 pagesDeep Feedforward Networks and Regularization: Licheng Zhang18MDS019No ratings yet
- Machine Learning: Neural NetworksDocument41 pagesMachine Learning: Neural NetworksAtınç YılmazNo ratings yet
- A108 Rosenberg SuppDocument10 pagesA108 Rosenberg Suppsabitha sabesanNo ratings yet
- Neural Networks in MATLABDocument13 pagesNeural Networks in MATLABHugo BadilloNo ratings yet
- AN Overview Artificial Neural Network Approach AN Overview Artificial Neural Network ApproachDocument34 pagesAN Overview Artificial Neural Network Approach AN Overview Artificial Neural Network ApproachSonaAjithNo ratings yet
- Machine Learning: Neural Networks Slides Mostly Adapted From Tom Mithcell, Han and KamberDocument40 pagesMachine Learning: Neural Networks Slides Mostly Adapted From Tom Mithcell, Han and KamberasdasdNo ratings yet
- Neural NetworksDocument45 pagesNeural NetworksDiễm Quỳnh TrầnNo ratings yet
- Ann MPDMDocument61 pagesAnn MPDMsidra shafiqNo ratings yet
- Quiz (1-B) Model AnswerDocument3 pagesQuiz (1-B) Model AnswerSara Bahaa EldinNo ratings yet
- BMM 2018 - Deep Learning TutorialDocument47 pagesBMM 2018 - Deep Learning TutorialaraghunathreddyraghunathNo ratings yet
- ARTIFICIAL NEURAL NETWORKS-moduleIIIDocument61 pagesARTIFICIAL NEURAL NETWORKS-moduleIIIelakkadanNo ratings yet
- Signal Processing Method For Faults Location in DC Transmission SystemDocument4 pagesSignal Processing Method For Faults Location in DC Transmission SystemBatoul BatoulNo ratings yet
- 6-DeepVisualLearning L6Document82 pages6-DeepVisualLearning L6hisisthesongoficeandfireNo ratings yet
- Redes Dinamicas - BPTT - DBP - AplicacionesDocument21 pagesRedes Dinamicas - BPTT - DBP - AplicacionesDaniel AlvarezNo ratings yet
- Soft Computing For Intelligent Control of Nonlinear Dynamical Systems (Invited Paper)Document35 pagesSoft Computing For Intelligent Control of Nonlinear Dynamical Systems (Invited Paper)ayeniNo ratings yet
- Computational Representation of Wigner Seitz CellsDocument6 pagesComputational Representation of Wigner Seitz CellsertülbayNo ratings yet
- 001 IntroDocument66 pages001 IntromanikNo ratings yet
- Recurrent NetsDocument28 pagesRecurrent NetsKhang Thái DuyNo ratings yet
- Lab 3 2023Document11 pagesLab 3 2023Azlina RamliNo ratings yet
- DKUT - CNTIII - Poles and Zeros Solved TestDocument6 pagesDKUT - CNTIII - Poles and Zeros Solved TestmwangiNo ratings yet
- Robust Control Project2Document6 pagesRobust Control Project2Karima ChakerNo ratings yet
- LN - ieML SupportVectorMachinesDocument36 pagesLN - ieML SupportVectorMachineskamikita127No ratings yet
- University of LimpopoDocument5 pagesUniversity of LimpopoNtokozo MasemulaNo ratings yet
- Deep Learning HardwareDocument82 pagesDeep Learning HardwareblackgenNo ratings yet
- AI - II - Cihan - Lect 6 PDFDocument31 pagesAI - II - Cihan - Lect 6 PDFAusid AbduladheemNo ratings yet
- L10 - Intro - To - Deep - LearningDocument75 pagesL10 - Intro - To - Deep - LearningNALE SVPMEnggNo ratings yet
- Introduction To Machine Learning - Unit 4 - Week 2Document4 pagesIntroduction To Machine Learning - Unit 4 - Week 2RAJASREE RNo ratings yet
- AI & Machine LearningDocument47 pagesAI & Machine LearningjcarlosaguiarNo ratings yet
- CNN and Gan: Introduction ToDocument58 pagesCNN and Gan: Introduction ToGopiNath VelivelaNo ratings yet
- Session 4Document35 pagesSession 4Hadare IdrissouNo ratings yet
- Lect 8Document32 pagesLect 8Magarsa BedasaNo ratings yet
- Quad 1Document13 pagesQuad 1prakhartripathi826No ratings yet
- FEM IntroductionDocument127 pagesFEM Introductionrohansuthar.ascentNo ratings yet
- Exercises On BackpropagationDocument4 pagesExercises On Backpropagationyuyang zhangNo ratings yet
- Chaotic Time Series Prediction by ArtifiDocument17 pagesChaotic Time Series Prediction by Artifialexandre.mslNo ratings yet
- Transmission de LingDocument7 pagesTransmission de Lingzakia zerroukiNo ratings yet
- EE223-Signals & Systems: Remote Final Exam Total Time: 03 Hours Total Marks: 100 Course InstructorDocument5 pagesEE223-Signals & Systems: Remote Final Exam Total Time: 03 Hours Total Marks: 100 Course InstructorMuhammad AbdullahNo ratings yet
- 01 - Semantic SegmentationDocument16 pages01 - Semantic Segmentationasim zamanNo ratings yet
- Lecture 3 FEAShapeFunctions1DDocument24 pagesLecture 3 FEAShapeFunctions1DatilolaNo ratings yet
- Machine Learning: Chapter 4. Artificial Neural NetworksDocument34 pagesMachine Learning: Chapter 4. Artificial Neural NetworksfareenfarzanawahedNo ratings yet
- Neural Network Implementation in JavaDocument12 pagesNeural Network Implementation in JavaRam SarsihaNo ratings yet
- Back Propagation Neural NetworkDocument5 pagesBack Propagation Neural NetworkKeshav TulsyanNo ratings yet
- Albrt931002 SpecDocument148 pagesAlbrt931002 SpecArturo Treviño MedinaNo ratings yet
- 4 Limits and ContinuityDocument21 pages4 Limits and ContinuityAnis Siti NurrohkayatiNo ratings yet
- William Stallings Computer Organization and Architecture 8 Edition Computer Evolution and Performance Computer Evolution and PerformanceDocument56 pagesWilliam Stallings Computer Organization and Architecture 8 Edition Computer Evolution and Performance Computer Evolution and PerformanceAhsan Jameel100% (2)
- 8051 Microcontroller FeaturesDocument42 pages8051 Microcontroller FeaturesTech_MX67% (3)
- Vinno A5 BrochureDocument6 pagesVinno A5 Brochurekhaled twakolNo ratings yet
- PLC, IO & Communications ProductsDocument46 pagesPLC, IO & Communications ProductsMuhamad PriyatnaNo ratings yet
- GR00005401 00Document32 pagesGR00005401 00TrevorNo ratings yet
- Cover Letter PDF DownloadDocument8 pagesCover Letter PDF Downloadf5b2q8e3100% (2)
- Lecturer - 3 Algorithm AnalysisDocument59 pagesLecturer - 3 Algorithm AnalysisSamiNo ratings yet
- 32PHG500177-42PFG501177-49PFG500178 KTS16.1L LaDocument50 pages32PHG500177-42PFG501177-49PFG500178 KTS16.1L LaelectronicamposNo ratings yet
- Sample Security PlanDocument9 pagesSample Security PlanAbraham BuruseNo ratings yet
- Cobol QuestionsDocument12 pagesCobol QuestionsNigthstalkerNo ratings yet
- Ring Manual Floodlight Cam 02 MANUAL WebDocument21 pagesRing Manual Floodlight Cam 02 MANUAL Webclea.foyNo ratings yet
- UM1720 User Manual: STM32Cube USB Host LibraryDocument43 pagesUM1720 User Manual: STM32Cube USB Host LibraryDali JliziNo ratings yet
- Applied Networking Labs 2nd Edition Boyle Solutions ManualDocument19 pagesApplied Networking Labs 2nd Edition Boyle Solutions ManualDavidBrownjrzf100% (61)
- Welcome To Our Presentation ENGDocument16 pagesWelcome To Our Presentation ENGTANJIN AHMADNo ratings yet
- IGMP & IGMP Snooping Clement DuvalDocument32 pagesIGMP & IGMP Snooping Clement DuvalCarlos Andres Silva ZuritaNo ratings yet
- (FIX) (Guide) Unbrick Hard Bricked LG G3 (VS9 - Verizon LG G3Document17 pages(FIX) (Guide) Unbrick Hard Bricked LG G3 (VS9 - Verizon LG G3robert hallsteinNo ratings yet
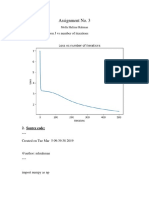
- Assignment No. 3: 1. Plot of Loss Function J Vs Number of IterationsDocument6 pagesAssignment No. 3: 1. Plot of Loss Function J Vs Number of Iterationssun_917443954No ratings yet
- What Is An ASPX File?: How To Open, Edit, and Convert ASPX FilesDocument3 pagesWhat Is An ASPX File?: How To Open, Edit, and Convert ASPX FilespeterNo ratings yet
- Ec6711 Emb Lab PDFDocument92 pagesEc6711 Emb Lab PDFAnonymous LXQnmsD100% (1)
- Experiment-2: Quires Using Operators in SQLDocument6 pagesExperiment-2: Quires Using Operators in SQLPhani Kumar SolletiNo ratings yet
- Project Hgs24Document25 pagesProject Hgs24hgstegglesNo ratings yet
- Die Design ProgramDocument5 pagesDie Design ProgramSundar KaruppiahNo ratings yet
- MCA (Revised) / BCA (Revised) Term-End Examination June, 2016Document4 pagesMCA (Revised) / BCA (Revised) Term-End Examination June, 2016Prerak Kumar SharmaNo ratings yet
- The Learner : Ernesto Rondon Hs Eric M. de Guzman Mathematics September 2, 2019 SecondDocument9 pagesThe Learner : Ernesto Rondon Hs Eric M. de Guzman Mathematics September 2, 2019 SecondEric de GuzmanNo ratings yet
- Harsh Verdhan Singh Autocad Mini Project FileDocument17 pagesHarsh Verdhan Singh Autocad Mini Project Fileaquaharsh0No ratings yet
- Irb 260Document2 pagesIrb 260ANDRENo ratings yet

























































































Download as pdf or txt
You might also like
- OUP - Just Click For The CaribbeanDocument292 pagesOUP - Just Click For The CaribbeanDemetre ford100% (1)
- Aci Card and Merchant Management Solutions Product Line Flyer FL Us 0711 4795 PDFDocument4 pagesAci Card and Merchant Management Solutions Product Line Flyer FL Us 0711 4795 PDFRazib ZoyNo ratings yet
- Ch4 - Multilayer PerceptronDocument26 pagesCh4 - Multilayer PerceptronĐặng Anh KhoaNo ratings yet
- Pattern Recognition Using Neural Network (Project Proposal For Image Processing)Document6 pagesPattern Recognition Using Neural Network (Project Proposal For Image Processing)Dil Prasad KunwarNo ratings yet
- Amansoftcomp PDFDocument27 pagesAmansoftcomp PDFas6858732No ratings yet
- Lab Manual On Soft Computing (IT-802) : Ms. Neha SexanaDocument29 pagesLab Manual On Soft Computing (IT-802) : Ms. Neha SexanaAdarsh SrivastavaNo ratings yet
- INT305 Machine Learning Linear Methods For Regression, OptimizationDocument50 pagesINT305 Machine Learning Linear Methods For Regression, OptimizationSheng HuangNo ratings yet
- Machine Learning Part 9Document33 pagesMachine Learning Part 9Sujit KumarNo ratings yet
- Neural Networks: Learning: Cost FunctionDocument33 pagesNeural Networks: Learning: Cost FunctionLydia DarlaNo ratings yet
- RELU and OthersDocument19 pagesRELU and OthersPRATIK GANGAPURWALANo ratings yet
- AIML - 04 Single Layer PerceptronDocument11 pagesAIML - 04 Single Layer PerceptronUMANG PEDNEKARNo ratings yet
- Ch.02 Modeling in Frequency Domain - AssignmentDocument5 pagesCh.02 Modeling in Frequency Domain - AssignmentThảo Đặng Ngọc ThanhNo ratings yet
- Discussion 4 Multiclass ClassificationDocument15 pagesDiscussion 4 Multiclass ClassificationLê Nguyễn Quang MinhNo ratings yet
- Machine Learning Week 3Document4 pagesMachine Learning Week 3AnandhsNo ratings yet
- Sheet #6 Ensemble + Neural Nets + Linear Regression + Backpropagation + CNNDocument4 pagesSheet #6 Ensemble + Neural Nets + Linear Regression + Backpropagation + CNNrowaida elsayedNo ratings yet
- Experiment-3: Convolution: Signals and Systems Lab (EC2P002)Document4 pagesExperiment-3: Convolution: Signals and Systems Lab (EC2P002)GAUTAM BUBNANo ratings yet
- Experiment-3: Convolution: Signals and Systems Lab (EC2P002)Document4 pagesExperiment-3: Convolution: Signals and Systems Lab (EC2P002)GAUTAM BUBNANo ratings yet
- Ai 7Document41 pagesAi 7saharkamal7274No ratings yet
- Backpropagation Learning in Neural NetworksDocument27 pagesBackpropagation Learning in Neural NetworksPooja PatwariNo ratings yet
- Deep Feedforward Networks and Regularization: Licheng ZhangDocument56 pagesDeep Feedforward Networks and Regularization: Licheng Zhang18MDS019No ratings yet
- Machine Learning: Neural NetworksDocument41 pagesMachine Learning: Neural NetworksAtınç YılmazNo ratings yet
- A108 Rosenberg SuppDocument10 pagesA108 Rosenberg Suppsabitha sabesanNo ratings yet
- Neural Networks in MATLABDocument13 pagesNeural Networks in MATLABHugo BadilloNo ratings yet
- AN Overview Artificial Neural Network Approach AN Overview Artificial Neural Network ApproachDocument34 pagesAN Overview Artificial Neural Network Approach AN Overview Artificial Neural Network ApproachSonaAjithNo ratings yet
- Machine Learning: Neural Networks Slides Mostly Adapted From Tom Mithcell, Han and KamberDocument40 pagesMachine Learning: Neural Networks Slides Mostly Adapted From Tom Mithcell, Han and KamberasdasdNo ratings yet
- Neural NetworksDocument45 pagesNeural NetworksDiễm Quỳnh TrầnNo ratings yet
- Ann MPDMDocument61 pagesAnn MPDMsidra shafiqNo ratings yet
- Quiz (1-B) Model AnswerDocument3 pagesQuiz (1-B) Model AnswerSara Bahaa EldinNo ratings yet
- BMM 2018 - Deep Learning TutorialDocument47 pagesBMM 2018 - Deep Learning TutorialaraghunathreddyraghunathNo ratings yet
- ARTIFICIAL NEURAL NETWORKS-moduleIIIDocument61 pagesARTIFICIAL NEURAL NETWORKS-moduleIIIelakkadanNo ratings yet
- Signal Processing Method For Faults Location in DC Transmission SystemDocument4 pagesSignal Processing Method For Faults Location in DC Transmission SystemBatoul BatoulNo ratings yet
- 6-DeepVisualLearning L6Document82 pages6-DeepVisualLearning L6hisisthesongoficeandfireNo ratings yet
- Redes Dinamicas - BPTT - DBP - AplicacionesDocument21 pagesRedes Dinamicas - BPTT - DBP - AplicacionesDaniel AlvarezNo ratings yet
- Soft Computing For Intelligent Control of Nonlinear Dynamical Systems (Invited Paper)Document35 pagesSoft Computing For Intelligent Control of Nonlinear Dynamical Systems (Invited Paper)ayeniNo ratings yet
- Computational Representation of Wigner Seitz CellsDocument6 pagesComputational Representation of Wigner Seitz CellsertülbayNo ratings yet
- 001 IntroDocument66 pages001 IntromanikNo ratings yet
- Recurrent NetsDocument28 pagesRecurrent NetsKhang Thái DuyNo ratings yet
- Lab 3 2023Document11 pagesLab 3 2023Azlina RamliNo ratings yet
- DKUT - CNTIII - Poles and Zeros Solved TestDocument6 pagesDKUT - CNTIII - Poles and Zeros Solved TestmwangiNo ratings yet
- Robust Control Project2Document6 pagesRobust Control Project2Karima ChakerNo ratings yet
- LN - ieML SupportVectorMachinesDocument36 pagesLN - ieML SupportVectorMachineskamikita127No ratings yet
- University of LimpopoDocument5 pagesUniversity of LimpopoNtokozo MasemulaNo ratings yet
- Deep Learning HardwareDocument82 pagesDeep Learning HardwareblackgenNo ratings yet
- AI - II - Cihan - Lect 6 PDFDocument31 pagesAI - II - Cihan - Lect 6 PDFAusid AbduladheemNo ratings yet
- L10 - Intro - To - Deep - LearningDocument75 pagesL10 - Intro - To - Deep - LearningNALE SVPMEnggNo ratings yet
- Introduction To Machine Learning - Unit 4 - Week 2Document4 pagesIntroduction To Machine Learning - Unit 4 - Week 2RAJASREE RNo ratings yet
- AI & Machine LearningDocument47 pagesAI & Machine LearningjcarlosaguiarNo ratings yet
- CNN and Gan: Introduction ToDocument58 pagesCNN and Gan: Introduction ToGopiNath VelivelaNo ratings yet
- Session 4Document35 pagesSession 4Hadare IdrissouNo ratings yet
- Lect 8Document32 pagesLect 8Magarsa BedasaNo ratings yet
- Quad 1Document13 pagesQuad 1prakhartripathi826No ratings yet
- FEM IntroductionDocument127 pagesFEM Introductionrohansuthar.ascentNo ratings yet
- Exercises On BackpropagationDocument4 pagesExercises On Backpropagationyuyang zhangNo ratings yet
- Chaotic Time Series Prediction by ArtifiDocument17 pagesChaotic Time Series Prediction by Artifialexandre.mslNo ratings yet
- Transmission de LingDocument7 pagesTransmission de Lingzakia zerroukiNo ratings yet
- EE223-Signals & Systems: Remote Final Exam Total Time: 03 Hours Total Marks: 100 Course InstructorDocument5 pagesEE223-Signals & Systems: Remote Final Exam Total Time: 03 Hours Total Marks: 100 Course InstructorMuhammad AbdullahNo ratings yet
- 01 - Semantic SegmentationDocument16 pages01 - Semantic Segmentationasim zamanNo ratings yet
- Lecture 3 FEAShapeFunctions1DDocument24 pagesLecture 3 FEAShapeFunctions1DatilolaNo ratings yet
- Machine Learning: Chapter 4. Artificial Neural NetworksDocument34 pagesMachine Learning: Chapter 4. Artificial Neural NetworksfareenfarzanawahedNo ratings yet
- Neural Network Implementation in JavaDocument12 pagesNeural Network Implementation in JavaRam SarsihaNo ratings yet
- Back Propagation Neural NetworkDocument5 pagesBack Propagation Neural NetworkKeshav TulsyanNo ratings yet
- Albrt931002 SpecDocument148 pagesAlbrt931002 SpecArturo Treviño MedinaNo ratings yet
- 4 Limits and ContinuityDocument21 pages4 Limits and ContinuityAnis Siti NurrohkayatiNo ratings yet
- William Stallings Computer Organization and Architecture 8 Edition Computer Evolution and Performance Computer Evolution and PerformanceDocument56 pagesWilliam Stallings Computer Organization and Architecture 8 Edition Computer Evolution and Performance Computer Evolution and PerformanceAhsan Jameel100% (2)
- 8051 Microcontroller FeaturesDocument42 pages8051 Microcontroller FeaturesTech_MX67% (3)
- Vinno A5 BrochureDocument6 pagesVinno A5 Brochurekhaled twakolNo ratings yet
- PLC, IO & Communications ProductsDocument46 pagesPLC, IO & Communications ProductsMuhamad PriyatnaNo ratings yet
- GR00005401 00Document32 pagesGR00005401 00TrevorNo ratings yet
- Cover Letter PDF DownloadDocument8 pagesCover Letter PDF Downloadf5b2q8e3100% (2)
- Lecturer - 3 Algorithm AnalysisDocument59 pagesLecturer - 3 Algorithm AnalysisSamiNo ratings yet
- 32PHG500177-42PFG501177-49PFG500178 KTS16.1L LaDocument50 pages32PHG500177-42PFG501177-49PFG500178 KTS16.1L LaelectronicamposNo ratings yet
- Sample Security PlanDocument9 pagesSample Security PlanAbraham BuruseNo ratings yet
- Cobol QuestionsDocument12 pagesCobol QuestionsNigthstalkerNo ratings yet
- Ring Manual Floodlight Cam 02 MANUAL WebDocument21 pagesRing Manual Floodlight Cam 02 MANUAL Webclea.foyNo ratings yet
- UM1720 User Manual: STM32Cube USB Host LibraryDocument43 pagesUM1720 User Manual: STM32Cube USB Host LibraryDali JliziNo ratings yet
- Applied Networking Labs 2nd Edition Boyle Solutions ManualDocument19 pagesApplied Networking Labs 2nd Edition Boyle Solutions ManualDavidBrownjrzf100% (61)
- Welcome To Our Presentation ENGDocument16 pagesWelcome To Our Presentation ENGTANJIN AHMADNo ratings yet
- IGMP & IGMP Snooping Clement DuvalDocument32 pagesIGMP & IGMP Snooping Clement DuvalCarlos Andres Silva ZuritaNo ratings yet
- (FIX) (Guide) Unbrick Hard Bricked LG G3 (VS9 - Verizon LG G3Document17 pages(FIX) (Guide) Unbrick Hard Bricked LG G3 (VS9 - Verizon LG G3robert hallsteinNo ratings yet
- Assignment No. 3: 1. Plot of Loss Function J Vs Number of IterationsDocument6 pagesAssignment No. 3: 1. Plot of Loss Function J Vs Number of Iterationssun_917443954No ratings yet
- What Is An ASPX File?: How To Open, Edit, and Convert ASPX FilesDocument3 pagesWhat Is An ASPX File?: How To Open, Edit, and Convert ASPX FilespeterNo ratings yet
- Ec6711 Emb Lab PDFDocument92 pagesEc6711 Emb Lab PDFAnonymous LXQnmsD100% (1)
- Experiment-2: Quires Using Operators in SQLDocument6 pagesExperiment-2: Quires Using Operators in SQLPhani Kumar SolletiNo ratings yet
- Project Hgs24Document25 pagesProject Hgs24hgstegglesNo ratings yet
- Die Design ProgramDocument5 pagesDie Design ProgramSundar KaruppiahNo ratings yet
- MCA (Revised) / BCA (Revised) Term-End Examination June, 2016Document4 pagesMCA (Revised) / BCA (Revised) Term-End Examination June, 2016Prerak Kumar SharmaNo ratings yet
- The Learner : Ernesto Rondon Hs Eric M. de Guzman Mathematics September 2, 2019 SecondDocument9 pagesThe Learner : Ernesto Rondon Hs Eric M. de Guzman Mathematics September 2, 2019 SecondEric de GuzmanNo ratings yet
- Harsh Verdhan Singh Autocad Mini Project FileDocument17 pagesHarsh Verdhan Singh Autocad Mini Project Fileaquaharsh0No ratings yet
- Irb 260Document2 pagesIrb 260ANDRENo ratings yet