
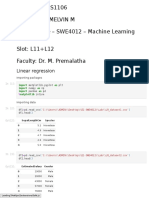
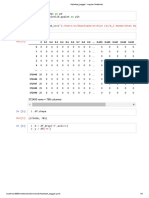
20it113 Logisticregression ML
20it113 Logisticregression ML
You might also like
- Motivation Letter SampleDocument1 pageMotivation Letter SampleMoulid Abdirahman AliNo ratings yet
- MinutelyDocument1 pageMinutelyAnonymous CDd9eukAxNNo ratings yet
- Abdulmalek, Rajgopal - 2007 - Analyzing The Benefits of Lean Manufacturing and Value Stream Mapping Via Simulation A Process Sector CaseDocument14 pagesAbdulmalek, Rajgopal - 2007 - Analyzing The Benefits of Lean Manufacturing and Value Stream Mapping Via Simulation A Process Sector CaseDragan DragičevićNo ratings yet
- 20bce2251 VL2021220503859 Ast03Document6 pages20bce2251 VL2021220503859 Ast03TANMAY MEHROTRANo ratings yet
- ML0101EN Clas Logistic Reg Churn Py v1Document13 pagesML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- Machine Learning Lab Assignment-8: Name: Kailasa Sandeep Kumar Reg No: 15BCE0480 Slot: L15+L16 Faculty: Vijaysherley.VDocument3 pagesMachine Learning Lab Assignment-8: Name: Kailasa Sandeep Kumar Reg No: 15BCE0480 Slot: L15+L16 Faculty: Vijaysherley.VAshish kumar NeelaNo ratings yet
- I Avaliação Parcial - 25.0 PTS - GabaritoDocument9 pagesI Avaliação Parcial - 25.0 PTS - GabaritoPedro CarvalhoNo ratings yet
- Jay Patel - DSML - Practical-6.ipynb - ColaboratoryDocument8 pagesJay Patel - DSML - Practical-6.ipynb - ColaboratorysharadNo ratings yet
- Scikit Learn What Were CoveringDocument15 pagesScikit Learn What Were CoveringRaiyan ZannatNo ratings yet
- Punto1 - Taller - Ipynb - ColaboratoryDocument4 pagesPunto1 - Taller - Ipynb - ColaboratoryYardlenis SanchezNo ratings yet
- Confidence Interval and Hypothesis TestingDocument1 pageConfidence Interval and Hypothesis TestingChetan TemkarNo ratings yet
- 8 - Logistic - Regression - Multiclass - Ipynb - ColaboratoryDocument6 pages8 - Logistic - Regression - Multiclass - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- Import AsDocument27 pagesImport AsFozia Dawood100% (1)
- Xarxa Neuronal - ColaboratoryDocument5 pagesXarxa Neuronal - Colaboratorybabsgordon20No ratings yet
- DL Output Ass2Document5 pagesDL Output Ass2Ayush PayalNo ratings yet
- Practice - DL - Ipynb - ColaboratoryDocument14 pagesPractice - DL - Ipynb - Colaboratorynoorullahmd461No ratings yet
- Gaussian NBDocument4 pagesGaussian NBnikkigupta13No ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- Lecture 2 Python 常用libraryDocument41 pagesLecture 2 Python 常用libraryYuanxingNo ratings yet
- Source Code in PDF FormatDocument15 pagesSource Code in PDF FormatShivam PrajapatiNo ratings yet
- AND - Gate - BiasedDocument4 pagesAND - Gate - Biasedmostafa98999No ratings yet
- Logistic Multiclass ClassificationDocument2 pagesLogistic Multiclass Classificationjaymehta1444No ratings yet
- Code ExerciseModelSelectionDocument19 pagesCode ExerciseModelSelectionaimen.nsiali100% (1)
- Practical 1 52Document4 pagesPractical 1 52Royal EmpireNo ratings yet
- Practical - 5 - 52Document4 pagesPractical - 5 - 52Royal EmpireNo ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- GNN 01 IntroDocument8 pagesGNN 01 IntrovitormeriatNo ratings yet
- 1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingDocument4 pages1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingAsmar HajizadaNo ratings yet
- Import As From Import From Import From Import From Import From Import From Import From Import From Import From Import From Import Import AsDocument8 pagesImport As From Import From Import From Import From Import From Import From Import From Import From Import From Import From Import Import Asvince.lachicaNo ratings yet
- Lab Record 2018-19 Mathematical Models Using Python Programming MAT451 Name: Yamuna.A Reg No:1740370Document32 pagesLab Record 2018-19 Mathematical Models Using Python Programming MAT451 Name: Yamuna.A Reg No:1740370yamunaNo ratings yet
- Assignment 6.2aDocument4 pagesAssignment 6.2adashNo ratings yet
- RStudioDocument3 pagesRStudioJose Daniel Noguera OropezaNo ratings yet
- Regno: 19mis1106 Name: Sam Melvin M Course Code - Swe4012 - Machine Learning Lab Slot: L11+L12 Faculty: Dr. M. PremalathaDocument37 pagesRegno: 19mis1106 Name: Sam Melvin M Course Code - Swe4012 - Machine Learning Lab Slot: L11+L12 Faculty: Dr. M. PremalathaXyzNo ratings yet
- Image ClassificationsDocument4 pagesImage ClassificationsAnvesh SilaganaNo ratings yet
- Implement SOFM For Character Recognition - WatermarkDocument9 pagesImplement SOFM For Character Recognition - Watermarksepovo6879No ratings yet
- Cáncer de Mama Con 8 Componentes Principales - Jupyter NotebookDocument7 pagesCáncer de Mama Con 8 Componentes Principales - Jupyter NotebookJIMMY CRISTHIAN CJURO APAZANo ratings yet
- Sunbase Data AssignmentDocument11 pagesSunbase Data Assignmentfanrock281No ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document9 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1Rajat SolankiNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Program 4 Lu Decomposition C ProgrammingDocument13 pagesProgram 4 Lu Decomposition C ProgrammingPraveen DNo ratings yet
- Import As Import As From Import: "Mean Squared Errors: "Document1 pageImport As Import As From Import: "Mean Squared Errors: "ulNo ratings yet
- SVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceDocument28 pagesSVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceZuzana W100% (1)
- Big Data Assignment - 7Document7 pagesBig Data Assignment - 7Rajeev MukheshNo ratings yet
- Multi - Class - Scaled - Down - Data - ColaboratoryDocument2 pagesMulti - Class - Scaled - Down - Data - ColaboratoryTahseen JwadNo ratings yet
- Image Classification - RithvikDocument20 pagesImage Classification - RithvikKanakamedala Sai Rithvik ee18b051No ratings yet
- LogisticregressionDocument5 pagesLogisticregressionpatil samrudhiNo ratings yet
- EE19B045 - Python AssignmentDocument7 pagesEE19B045 - Python AssignmentSnehita NNo ratings yet
- Fluid Particle Mechanics (CHT 208) Assignment-1 Date: 12-03-2020Document1 pageFluid Particle Mechanics (CHT 208) Assignment-1 Date: 12-03-2020Heena UpadhyayNo ratings yet
- Numpy PandasDocument20 pagesNumpy PandasAnish pandeyNo ratings yet
- Stock Price Prediction Project Utilizing LSTM TechniquesDocument14 pagesStock Price Prediction Project Utilizing LSTM TechniquesNisAr AhmadNo ratings yet
- Alphabet - Kaggal - Jupyter NotebookDocument6 pagesAlphabet - Kaggal - Jupyter Notebookankitasonawane9988No ratings yet
- Lab - 7 - 21130616 - TranhThanhVu - Ipynb - ColabDocument10 pagesLab - 7 - 21130616 - TranhThanhVu - Ipynb - Colabnguyennhutoan722003No ratings yet
- K Means ClusteringDocument10 pagesK Means ClusteringWalid Sassi100% (1)
- Advance Mathematics: Dosen Pengampu: Indrazno Siradjuddin, ST., MT., PH.DDocument6 pagesAdvance Mathematics: Dosen Pengampu: Indrazno Siradjuddin, ST., MT., PH.DPuspa AyuNo ratings yet
- Assignment 6.2bDocument4 pagesAssignment 6.2bdashNo ratings yet
- Experiment 8 Heirarchical ClusteringDocument17 pagesExperiment 8 Heirarchical ClusteringYuvraj Singh RathoreNo ratings yet
- Neural Networks: From ImportDocument3 pagesNeural Networks: From ImportAnonymous VNu3ODGavNo ratings yet
- 統計學習CH2 Lab - Jupyter Notebook (直向)Document41 pages統計學習CH2 Lab - Jupyter Notebook (直向)張FNo ratings yet
- AIML Report (1) 11Document13 pagesAIML Report (1) 11sumatksumatk5No ratings yet
- Opration Management TAMDocument5 pagesOpration Management TAMHK 'sNo ratings yet
- (The Selected Writings of Hans-Georg Gadamer 2) Hans-Georg Gadamer - Ethics, Aesthetics and The Historical Dimension of Language - Bloomsbury Academic (2022)Document324 pages(The Selected Writings of Hans-Georg Gadamer 2) Hans-Georg Gadamer - Ethics, Aesthetics and The Historical Dimension of Language - Bloomsbury Academic (2022)German Stefanoff100% (1)
- Ghost ScopeDocument5 pagesGhost ScopeDanNo ratings yet
- MEP - Scheme - of - Work PDFDocument2 pagesMEP - Scheme - of - Work PDFrukia316No ratings yet
- Bio-Dynamic Agriculture An IntroductionDocument266 pagesBio-Dynamic Agriculture An IntroductionTeo100% (2)
- Math Optional Hand WrittenDocument1,237 pagesMath Optional Hand Writtenatipriya choudharyNo ratings yet
- SCMADocument20 pagesSCMASHUBHAM JAINNo ratings yet
- ATV1200 BrochureDocument11 pagesATV1200 BrochureahilsergeyNo ratings yet
- Ilmu BahanDocument15 pagesIlmu BahanPECC PolinesNo ratings yet
- Vũ Trư NG GiangDocument4 pagesVũ Trư NG Gianghung6d5No ratings yet
- First Monthly Examination: Discipline and Ideas in The Social Sciences 11Document2 pagesFirst Monthly Examination: Discipline and Ideas in The Social Sciences 11Renen Millo BantilloNo ratings yet
- SCIENCE 4 Q3 February 13 17 2023 MON FRIDocument11 pagesSCIENCE 4 Q3 February 13 17 2023 MON FRIAndrea Y. AquinoNo ratings yet
- The in Uence of Social Environments On Child Development at The Preschool AgeDocument8 pagesThe in Uence of Social Environments On Child Development at The Preschool AgeTrisha Kate BumagatNo ratings yet
- Practical Exercise 3 Pareto Diagram: DR Yousef Amer - School of Engineering University of South Australia Page 1 of 3Document6 pagesPractical Exercise 3 Pareto Diagram: DR Yousef Amer - School of Engineering University of South Australia Page 1 of 3HarisNo ratings yet
- 1200 TỪ VỰNG HỌC THUẬT THƯỜNG XUẤT HIỆN NHẤT TRONG IELTS READINGDocument3 pages1200 TỪ VỰNG HỌC THUẬT THƯỜNG XUẤT HIỆN NHẤT TRONG IELTS READINGLong LưNo ratings yet
- Mock Interview PrepDocument12 pagesMock Interview PrepJohn MeyerNo ratings yet
- HW Assignment 1Document2 pagesHW Assignment 1Darcelle PaulNo ratings yet
- E - Efma Rbi Insp Interval Assess Projector - PP SimtechDocument10 pagesE - Efma Rbi Insp Interval Assess Projector - PP SimtechAbhimanyu SharmaNo ratings yet
- PRECALCULUS TOS-MidtermDocument2 pagesPRECALCULUS TOS-MidtermJERLYN MACADONo ratings yet
- MATH 1F - 3 Complex ConjugatesDocument2 pagesMATH 1F - 3 Complex ConjugatesJay-pNo ratings yet
- Ddo Ipcrf Proficient Teacher 1 3 Bandija Cherry Mae MDocument19 pagesDdo Ipcrf Proficient Teacher 1 3 Bandija Cherry Mae MCherry Mae Morales BandijaNo ratings yet
- The World Corpsed in Samuel Becketts EndDocument12 pagesThe World Corpsed in Samuel Becketts EndsippycupgeorgiaNo ratings yet
- N Forgings Energy Audit Final ReportDocument21 pagesN Forgings Energy Audit Final Reportbulusu kanthNo ratings yet
- X Ä A A Ä A A X: Values of Joint-Life Actuarial Functions Based On The AM92 Mortality Table at I 4%Document1 pageX Ä A A Ä A A X: Values of Joint-Life Actuarial Functions Based On The AM92 Mortality Table at I 4%Fung AlexNo ratings yet
- Department of Education: Republic of The PhilippinesDocument12 pagesDepartment of Education: Republic of The PhilippinesmarebeccaNo ratings yet
- Astm c172 English - CompressDocument5 pagesAstm c172 English - Compresstuski24No ratings yet
- Lab Exercise9 SensesDocument4 pagesLab Exercise9 Sensesian avenNo ratings yet
- Ca 125 IiDocument4 pagesCa 125 IiHassan GillNo ratings yet
- Max Snack AttackDocument3 pagesMax Snack AttackAdolfo Toxicat100% (1)























































































Download as docx, pdf, or txt
You might also like
- Motivation Letter SampleDocument1 pageMotivation Letter SampleMoulid Abdirahman AliNo ratings yet
- MinutelyDocument1 pageMinutelyAnonymous CDd9eukAxNNo ratings yet
- Abdulmalek, Rajgopal - 2007 - Analyzing The Benefits of Lean Manufacturing and Value Stream Mapping Via Simulation A Process Sector CaseDocument14 pagesAbdulmalek, Rajgopal - 2007 - Analyzing The Benefits of Lean Manufacturing and Value Stream Mapping Via Simulation A Process Sector CaseDragan DragičevićNo ratings yet
- 20bce2251 VL2021220503859 Ast03Document6 pages20bce2251 VL2021220503859 Ast03TANMAY MEHROTRANo ratings yet
- ML0101EN Clas Logistic Reg Churn Py v1Document13 pagesML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- Machine Learning Lab Assignment-8: Name: Kailasa Sandeep Kumar Reg No: 15BCE0480 Slot: L15+L16 Faculty: Vijaysherley.VDocument3 pagesMachine Learning Lab Assignment-8: Name: Kailasa Sandeep Kumar Reg No: 15BCE0480 Slot: L15+L16 Faculty: Vijaysherley.VAshish kumar NeelaNo ratings yet
- I Avaliação Parcial - 25.0 PTS - GabaritoDocument9 pagesI Avaliação Parcial - 25.0 PTS - GabaritoPedro CarvalhoNo ratings yet
- Jay Patel - DSML - Practical-6.ipynb - ColaboratoryDocument8 pagesJay Patel - DSML - Practical-6.ipynb - ColaboratorysharadNo ratings yet
- Scikit Learn What Were CoveringDocument15 pagesScikit Learn What Were CoveringRaiyan ZannatNo ratings yet
- Punto1 - Taller - Ipynb - ColaboratoryDocument4 pagesPunto1 - Taller - Ipynb - ColaboratoryYardlenis SanchezNo ratings yet
- Confidence Interval and Hypothesis TestingDocument1 pageConfidence Interval and Hypothesis TestingChetan TemkarNo ratings yet
- 8 - Logistic - Regression - Multiclass - Ipynb - ColaboratoryDocument6 pages8 - Logistic - Regression - Multiclass - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- Import AsDocument27 pagesImport AsFozia Dawood100% (1)
- Xarxa Neuronal - ColaboratoryDocument5 pagesXarxa Neuronal - Colaboratorybabsgordon20No ratings yet
- DL Output Ass2Document5 pagesDL Output Ass2Ayush PayalNo ratings yet
- Practice - DL - Ipynb - ColaboratoryDocument14 pagesPractice - DL - Ipynb - Colaboratorynoorullahmd461No ratings yet
- Gaussian NBDocument4 pagesGaussian NBnikkigupta13No ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- Lecture 2 Python 常用libraryDocument41 pagesLecture 2 Python 常用libraryYuanxingNo ratings yet
- Source Code in PDF FormatDocument15 pagesSource Code in PDF FormatShivam PrajapatiNo ratings yet
- AND - Gate - BiasedDocument4 pagesAND - Gate - Biasedmostafa98999No ratings yet
- Logistic Multiclass ClassificationDocument2 pagesLogistic Multiclass Classificationjaymehta1444No ratings yet
- Code ExerciseModelSelectionDocument19 pagesCode ExerciseModelSelectionaimen.nsiali100% (1)
- Practical 1 52Document4 pagesPractical 1 52Royal EmpireNo ratings yet
- Practical - 5 - 52Document4 pagesPractical - 5 - 52Royal EmpireNo ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- GNN 01 IntroDocument8 pagesGNN 01 IntrovitormeriatNo ratings yet
- 1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingDocument4 pages1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingAsmar HajizadaNo ratings yet
- Import As From Import From Import From Import From Import From Import From Import From Import From Import From Import From Import Import AsDocument8 pagesImport As From Import From Import From Import From Import From Import From Import From Import From Import From Import From Import Import Asvince.lachicaNo ratings yet
- Lab Record 2018-19 Mathematical Models Using Python Programming MAT451 Name: Yamuna.A Reg No:1740370Document32 pagesLab Record 2018-19 Mathematical Models Using Python Programming MAT451 Name: Yamuna.A Reg No:1740370yamunaNo ratings yet
- Assignment 6.2aDocument4 pagesAssignment 6.2adashNo ratings yet
- RStudioDocument3 pagesRStudioJose Daniel Noguera OropezaNo ratings yet
- Regno: 19mis1106 Name: Sam Melvin M Course Code - Swe4012 - Machine Learning Lab Slot: L11+L12 Faculty: Dr. M. PremalathaDocument37 pagesRegno: 19mis1106 Name: Sam Melvin M Course Code - Swe4012 - Machine Learning Lab Slot: L11+L12 Faculty: Dr. M. PremalathaXyzNo ratings yet
- Image ClassificationsDocument4 pagesImage ClassificationsAnvesh SilaganaNo ratings yet
- Implement SOFM For Character Recognition - WatermarkDocument9 pagesImplement SOFM For Character Recognition - Watermarksepovo6879No ratings yet
- Cáncer de Mama Con 8 Componentes Principales - Jupyter NotebookDocument7 pagesCáncer de Mama Con 8 Componentes Principales - Jupyter NotebookJIMMY CRISTHIAN CJURO APAZANo ratings yet
- Sunbase Data AssignmentDocument11 pagesSunbase Data Assignmentfanrock281No ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document9 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1Rajat SolankiNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Program 4 Lu Decomposition C ProgrammingDocument13 pagesProgram 4 Lu Decomposition C ProgrammingPraveen DNo ratings yet
- Import As Import As From Import: "Mean Squared Errors: "Document1 pageImport As Import As From Import: "Mean Squared Errors: "ulNo ratings yet
- SVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceDocument28 pagesSVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceZuzana W100% (1)
- Big Data Assignment - 7Document7 pagesBig Data Assignment - 7Rajeev MukheshNo ratings yet
- Multi - Class - Scaled - Down - Data - ColaboratoryDocument2 pagesMulti - Class - Scaled - Down - Data - ColaboratoryTahseen JwadNo ratings yet
- Image Classification - RithvikDocument20 pagesImage Classification - RithvikKanakamedala Sai Rithvik ee18b051No ratings yet
- LogisticregressionDocument5 pagesLogisticregressionpatil samrudhiNo ratings yet
- EE19B045 - Python AssignmentDocument7 pagesEE19B045 - Python AssignmentSnehita NNo ratings yet
- Fluid Particle Mechanics (CHT 208) Assignment-1 Date: 12-03-2020Document1 pageFluid Particle Mechanics (CHT 208) Assignment-1 Date: 12-03-2020Heena UpadhyayNo ratings yet
- Numpy PandasDocument20 pagesNumpy PandasAnish pandeyNo ratings yet
- Stock Price Prediction Project Utilizing LSTM TechniquesDocument14 pagesStock Price Prediction Project Utilizing LSTM TechniquesNisAr AhmadNo ratings yet
- Alphabet - Kaggal - Jupyter NotebookDocument6 pagesAlphabet - Kaggal - Jupyter Notebookankitasonawane9988No ratings yet
- Lab - 7 - 21130616 - TranhThanhVu - Ipynb - ColabDocument10 pagesLab - 7 - 21130616 - TranhThanhVu - Ipynb - Colabnguyennhutoan722003No ratings yet
- K Means ClusteringDocument10 pagesK Means ClusteringWalid Sassi100% (1)
- Advance Mathematics: Dosen Pengampu: Indrazno Siradjuddin, ST., MT., PH.DDocument6 pagesAdvance Mathematics: Dosen Pengampu: Indrazno Siradjuddin, ST., MT., PH.DPuspa AyuNo ratings yet
- Assignment 6.2bDocument4 pagesAssignment 6.2bdashNo ratings yet
- Experiment 8 Heirarchical ClusteringDocument17 pagesExperiment 8 Heirarchical ClusteringYuvraj Singh RathoreNo ratings yet
- Neural Networks: From ImportDocument3 pagesNeural Networks: From ImportAnonymous VNu3ODGavNo ratings yet
- 統計學習CH2 Lab - Jupyter Notebook (直向)Document41 pages統計學習CH2 Lab - Jupyter Notebook (直向)張FNo ratings yet
- AIML Report (1) 11Document13 pagesAIML Report (1) 11sumatksumatk5No ratings yet
- Opration Management TAMDocument5 pagesOpration Management TAMHK 'sNo ratings yet
- (The Selected Writings of Hans-Georg Gadamer 2) Hans-Georg Gadamer - Ethics, Aesthetics and The Historical Dimension of Language - Bloomsbury Academic (2022)Document324 pages(The Selected Writings of Hans-Georg Gadamer 2) Hans-Georg Gadamer - Ethics, Aesthetics and The Historical Dimension of Language - Bloomsbury Academic (2022)German Stefanoff100% (1)
- Ghost ScopeDocument5 pagesGhost ScopeDanNo ratings yet
- MEP - Scheme - of - Work PDFDocument2 pagesMEP - Scheme - of - Work PDFrukia316No ratings yet
- Bio-Dynamic Agriculture An IntroductionDocument266 pagesBio-Dynamic Agriculture An IntroductionTeo100% (2)
- Math Optional Hand WrittenDocument1,237 pagesMath Optional Hand Writtenatipriya choudharyNo ratings yet
- SCMADocument20 pagesSCMASHUBHAM JAINNo ratings yet
- ATV1200 BrochureDocument11 pagesATV1200 BrochureahilsergeyNo ratings yet
- Ilmu BahanDocument15 pagesIlmu BahanPECC PolinesNo ratings yet
- Vũ Trư NG GiangDocument4 pagesVũ Trư NG Gianghung6d5No ratings yet
- First Monthly Examination: Discipline and Ideas in The Social Sciences 11Document2 pagesFirst Monthly Examination: Discipline and Ideas in The Social Sciences 11Renen Millo BantilloNo ratings yet
- SCIENCE 4 Q3 February 13 17 2023 MON FRIDocument11 pagesSCIENCE 4 Q3 February 13 17 2023 MON FRIAndrea Y. AquinoNo ratings yet
- The in Uence of Social Environments On Child Development at The Preschool AgeDocument8 pagesThe in Uence of Social Environments On Child Development at The Preschool AgeTrisha Kate BumagatNo ratings yet
- Practical Exercise 3 Pareto Diagram: DR Yousef Amer - School of Engineering University of South Australia Page 1 of 3Document6 pagesPractical Exercise 3 Pareto Diagram: DR Yousef Amer - School of Engineering University of South Australia Page 1 of 3HarisNo ratings yet
- 1200 TỪ VỰNG HỌC THUẬT THƯỜNG XUẤT HIỆN NHẤT TRONG IELTS READINGDocument3 pages1200 TỪ VỰNG HỌC THUẬT THƯỜNG XUẤT HIỆN NHẤT TRONG IELTS READINGLong LưNo ratings yet
- Mock Interview PrepDocument12 pagesMock Interview PrepJohn MeyerNo ratings yet
- HW Assignment 1Document2 pagesHW Assignment 1Darcelle PaulNo ratings yet
- E - Efma Rbi Insp Interval Assess Projector - PP SimtechDocument10 pagesE - Efma Rbi Insp Interval Assess Projector - PP SimtechAbhimanyu SharmaNo ratings yet
- PRECALCULUS TOS-MidtermDocument2 pagesPRECALCULUS TOS-MidtermJERLYN MACADONo ratings yet
- MATH 1F - 3 Complex ConjugatesDocument2 pagesMATH 1F - 3 Complex ConjugatesJay-pNo ratings yet
- Ddo Ipcrf Proficient Teacher 1 3 Bandija Cherry Mae MDocument19 pagesDdo Ipcrf Proficient Teacher 1 3 Bandija Cherry Mae MCherry Mae Morales BandijaNo ratings yet
- The World Corpsed in Samuel Becketts EndDocument12 pagesThe World Corpsed in Samuel Becketts EndsippycupgeorgiaNo ratings yet
- N Forgings Energy Audit Final ReportDocument21 pagesN Forgings Energy Audit Final Reportbulusu kanthNo ratings yet
- X Ä A A Ä A A X: Values of Joint-Life Actuarial Functions Based On The AM92 Mortality Table at I 4%Document1 pageX Ä A A Ä A A X: Values of Joint-Life Actuarial Functions Based On The AM92 Mortality Table at I 4%Fung AlexNo ratings yet
- Department of Education: Republic of The PhilippinesDocument12 pagesDepartment of Education: Republic of The PhilippinesmarebeccaNo ratings yet
- Astm c172 English - CompressDocument5 pagesAstm c172 English - Compresstuski24No ratings yet
- Lab Exercise9 SensesDocument4 pagesLab Exercise9 Sensesian avenNo ratings yet
- Ca 125 IiDocument4 pagesCa 125 IiHassan GillNo ratings yet
- Max Snack AttackDocument3 pagesMax Snack AttackAdolfo Toxicat100% (1)