
03 Multiple Linear Regression
03 Multiple Linear Regression
You might also like
- Module 4 (Data Management) - Math 101Document8 pagesModule 4 (Data Management) - Math 101Flory CabaseNo ratings yet
- Tutorial For StatgraphicsDocument53 pagesTutorial For StatgraphicsSaúl DtNo ratings yet
- E21CSEU0770 Lab4Document4 pagesE21CSEU0770 Lab4kumar.nayan26No ratings yet
- Lecture3 2018Document16 pagesLecture3 2018Stefan-Aurelian ApostolNo ratings yet
- LT05 L1TP 003056 20091218 20161017 01 T1 AngDocument13 pagesLT05 L1TP 003056 20091218 20161017 01 T1 AngMilenaNo ratings yet
- Stock Prediction Web App - Jupyter NotebookDocument12 pagesStock Prediction Web App - Jupyter Notebookashutosh312004No ratings yet
- Regression DemoDocument8 pagesRegression Demorxn114392No ratings yet
- 1 Solution1Document6 pages1 Solution1Mix-Kat ZiakaNo ratings yet
- Source Code in PDF FormatDocument15 pagesSource Code in PDF FormatShivam PrajapatiNo ratings yet
- Ridge - Lasso - Regression (1) .Ipynb - ColaboratoryDocument4 pagesRidge - Lasso - Regression (1) .Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- DLL 7 Harsh Kabir 2203254Document6 pagesDLL 7 Harsh Kabir 2203254Darshil RajNo ratings yet
- Name: Shreyash Kharat Homework: Hw3 (Problem 1)Document7 pagesName: Shreyash Kharat Homework: Hw3 (Problem 1)Mainak SamantaNo ratings yet
- Quiz Data ScienseDocument8 pagesQuiz Data Scienseada sajaNo ratings yet
- Chapter 4Document28 pagesChapter 4sulavdklNo ratings yet
- MScFE 300 Group Work Project 2 Python CodesDocument2 pagesMScFE 300 Group Work Project 2 Python CodesBryanNo ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- PembelajaranMesin - Ipynb - ColaboratoryDocument6 pagesPembelajaranMesin - Ipynb - ColaboratoryKhaerul RijalNo ratings yet
- Merging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - ColaboratoryDocument16 pagesMerging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - Colaboratorygirishcherry12100% (1)
- Import As Import As From Import: "Mean Squared Errors: "Document1 pageImport As Import As From Import: "Mean Squared Errors: "ulNo ratings yet
- Euler Explicit Jan2024Document11 pagesEuler Explicit Jan2024getachewbonga09No ratings yet
- 1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingDocument4 pages1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingAsmar HajizadaNo ratings yet
- Data Preprocessing ML LabDocument6 pagesData Preprocessing ML Labmohan kukrejaNo ratings yet
- PCA Code-CheckpointDocument4 pagesPCA Code-CheckpointАурел ПNo ratings yet
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- KMeans Clustering Bidimensional Daniel Ames CamayoDocument15 pagesKMeans Clustering Bidimensional Daniel Ames CamayoEl RusnderNo ratings yet
- Lab - 7 - 21130616 - TranhThanhVu - Ipynb - ColabDocument10 pagesLab - 7 - 21130616 - TranhThanhVu - Ipynb - Colabnguyennhutoan722003No ratings yet
- Coding Tugas Besar Analitika DataDocument7 pagesCoding Tugas Besar Analitika Datarizqullahm14No ratings yet
- LT05 L2SP 179032 19990818 20200908 02 T1 AngDocument13 pagesLT05 L2SP 179032 19990818 20200908 02 T1 AngAnas Sharafeldin Mohamed OsmanNo ratings yet
- Ilovepdf MergedDocument47 pagesIlovepdf MergedSIDDHANT MANDALNo ratings yet
- Assumption of Linear RegressionDocument6 pagesAssumption of Linear RegressionKagade AjinkyaNo ratings yet
- Le07 L1TP 184028 19991203 20170216 01 T1 AngDocument16 pagesLe07 L1TP 184028 19991203 20170216 01 T1 AngMag ClaudiaNo ratings yet
- LT05 L1TP 190055 19841211 20170219 01 T1 AngDocument13 pagesLT05 L1TP 190055 19841211 20170219 01 T1 AngmodupeNo ratings yet
- Le07 L1TP 120065 20020821 20200916 02 T1 AngDocument16 pagesLe07 L1TP 120065 20020821 20200916 02 T1 AngklklklklklklklklklkkNo ratings yet
- Matlab Code: Question No: 4 (A)Document11 pagesMatlab Code: Question No: 4 (A)ihsan yaseenNo ratings yet
- LT05 L2SP 148045 20111114 20200820 02 T1 AngDocument13 pagesLT05 L2SP 148045 20111114 20200820 02 T1 Angksuhail44444No ratings yet
- Project 8 Predictive Analytics - Ipynb - ColaboratoryDocument8 pagesProject 8 Predictive Analytics - Ipynb - ColaboratoryaadityadeolalikarNo ratings yet
- Desarrollo Modelo Random Forest Preparamos El Entorno de SparkDocument3 pagesDesarrollo Modelo Random Forest Preparamos El Entorno de SparkFacundo VarasNo ratings yet
- Jupyter Notebook Yardlenis Sánchez Act2Document1 pageJupyter Notebook Yardlenis Sánchez Act2NASLYNo ratings yet
- Compute Fibonacci Using Java and ParallelizationDocument2,713 pagesCompute Fibonacci Using Java and ParallelizationIoan Simion BelbeNo ratings yet
- Y # - Y Matrix SetupDocument11 pagesY # - Y Matrix SetupSeymurH-vNo ratings yet
- 2 - 9 - KNN CodeDocument6 pages2 - 9 - KNN CodeYahya SabriNo ratings yet
- Basant Kumar Adm - No.-16je002220 SEMESTER-4th: Matlab Assignment No.-2 NameDocument4 pagesBasant Kumar Adm - No.-16je002220 SEMESTER-4th: Matlab Assignment No.-2 NameBasant KumarNo ratings yet
- Portfoliompt1: 1 Universidad Nacional de IngenieríaDocument10 pagesPortfoliompt1: 1 Universidad Nacional de IngenieríaArnold MontesinosNo ratings yet
- LT05 L1TP 183028 20010904 20180501 01 T1 AngDocument13 pagesLT05 L1TP 183028 20010904 20180501 01 T1 AngClaudia Cristina MagNo ratings yet
- Import AsDocument27 pagesImport AsFozia Dawood100% (1)
- BS SRR-3Document20 pagesBS SRR-3anveshvarma365No ratings yet
- Take-Home Test 1 AE3110 Aerodinamika: Oleh: Muhammad Rizki ZuhriDocument11 pagesTake-Home Test 1 AE3110 Aerodinamika: Oleh: Muhammad Rizki ZuhriMuhammad Rizki ZuhriNo ratings yet
- Pattern - Recognition - 3 - Code With OutputDocument7 pagesPattern - Recognition - 3 - Code With OutputReem NasserNo ratings yet
- 19mis1112 Lab1Document10 pages19mis1112 Lab1Fèdríck SämùélNo ratings yet
- Assignment Seminar 8Document4 pagesAssignment Seminar 8KNo ratings yet
- Question 1 (15) - Multiple Choice To Be Answered On Multiple Choice Sheet FormDocument6 pagesQuestion 1 (15) - Multiple Choice To Be Answered On Multiple Choice Sheet FormNicholas RuestNo ratings yet
- LT05 L1TP 173033 20110910 20200820 02 T1 AngDocument13 pagesLT05 L1TP 173033 20110910 20200820 02 T1 Angmerve1099No ratings yet
- PandasDocument21 pagesPandasShubham dattatray koteNo ratings yet
- Parte 1. Problemas Sobre Tema 2.: Unrecognized Function or Variable 'B'Document10 pagesParte 1. Problemas Sobre Tema 2.: Unrecognized Function or Variable 'B'EMILIO RODRIGUEZ CALDERONNo ratings yet
- TranMinhTu1 bt2 2Document5 pagesTranMinhTu1 bt2 2Trần Minh TúNo ratings yet
- 2 Fourier Transforms CorDocument8 pages2 Fourier Transforms CorCəvahir AğazadəNo ratings yet
- PythonDocument4 pagesPythonESTUDIANTE JOSE DAVID MARTINEZ RODRIGUEZNo ratings yet
- DIMENSIÓN.Z, Método MatricialDocument29 pagesDIMENSIÓN.Z, Método MatricialAlison GonzálezNo ratings yet
- Labpractice 2Document29 pagesLabpractice 2Rajashree Das100% (2)
- ROC and AUC Practical Implementation PDFDocument6 pagesROC and AUC Practical Implementation PDFNermine LimemeNo ratings yet
- False Position Method PracticalDocument3 pagesFalse Position Method PracticalPrakriti SaxenaNo ratings yet
- 08 Decision - TreeDocument9 pages08 Decision - TreeGabriel GheorgheNo ratings yet
- B Ridge - and - Lasso - RegressionDocument5 pagesB Ridge - and - Lasso - RegressionGabriel GheorgheNo ratings yet
- 13 Cross - ValidationDocument4 pages13 Cross - ValidationGabriel GheorgheNo ratings yet
- 02 MulticollinearityDocument8 pages02 MulticollinearityGabriel Gheorghe100% (1)
- 03 A Polynomial Linear RegressionDocument6 pages03 A Polynomial Linear RegressionGabriel GheorgheNo ratings yet
- Ensemble LearningDocument7 pagesEnsemble LearningGabriel Gheorghe100% (1)
- Backward && Forward Feature Selection PART-2Document6 pagesBackward && Forward Feature Selection PART-2Gabriel GheorgheNo ratings yet
- 22 Dim Reduction Part-1Document9 pages22 Dim Reduction Part-1Gabriel GheorgheNo ratings yet
- GroupsDocument1 pageGroupsGabriel GheorgheNo ratings yet
- Projects ExperienceDocument19 pagesProjects ExperienceGabriel GheorgheNo ratings yet
- Dev OpsDocument1 pageDev OpsGabriel GheorgheNo ratings yet
- Knowledge Learning Steps Learnig in ServiceNowDocument1 pageKnowledge Learning Steps Learnig in ServiceNowGabriel GheorgheNo ratings yet
- Service NowDocument2 pagesService NowGabriel GheorgheNo ratings yet
- JD - Senior Java Developer - Extenda Officecentral - 40580Document2 pagesJD - Senior Java Developer - Extenda Officecentral - 40580Gabriel GheorgheNo ratings yet
- An Artificial Intelligence Browser Architecture AIDocument11 pagesAn Artificial Intelligence Browser Architecture AIGabriel GheorgheNo ratings yet
- AddsupDocument2 pagesAddsupGabriel GheorgheNo ratings yet
- BSC-301 - Probability - Distribution 3Document8 pagesBSC-301 - Probability - Distribution 3Precisive OneNo ratings yet
- 11 Data VisualizationDocument44 pages11 Data VisualizationYEOWNo ratings yet
- Stat Prob Q4 Module 3Document21 pagesStat Prob Q4 Module 3Lailanie Fortu60% (5)
- Historical Data RSM Tutorial (Part 2 - Advanced Topics) : Design EvaluationDocument6 pagesHistorical Data RSM Tutorial (Part 2 - Advanced Topics) : Design Evaluationjamunaa83No ratings yet
- School of Applied Mathematics and Informatics: H H H H H HDocument1 pageSchool of Applied Mathematics and Informatics: H H H H H HHưng Đoàn VănNo ratings yet
- Output Statistics Frequency Table: Penyembuhan Luka Pasien Post OperasiDocument5 pagesOutput Statistics Frequency Table: Penyembuhan Luka Pasien Post OperasiDetdet343No ratings yet
- The Influence of Tax Knowledge, Taxpayer Awareness, And Tax Rates on the Compliance of Individual Taxpayers With Tax Sanctions as a Moderating Variable in E-Commerce Business Activities (Case Study at Online Shop Owner in IndoDocument12 pagesThe Influence of Tax Knowledge, Taxpayer Awareness, And Tax Rates on the Compliance of Individual Taxpayers With Tax Sanctions as a Moderating Variable in E-Commerce Business Activities (Case Study at Online Shop Owner in IndoInternational Journal of Innovative Science and Research Technology100% (1)
- Random Effects Probit and Logit Understanding Predictions and Marginal EffectsDocument9 pagesRandom Effects Probit and Logit Understanding Predictions and Marginal EffectsEdwin ReveloNo ratings yet
- Business Statistics-Spss Assignment: Group A8Document6 pagesBusiness Statistics-Spss Assignment: Group A8Alina KujurNo ratings yet
- Box Plot Answers MMEDocument2 pagesBox Plot Answers MMESabih AzharNo ratings yet
- (Written Examination Scheme) : (MCQ S)Document4 pages(Written Examination Scheme) : (MCQ S)rahulNo ratings yet
- Measures of VariationDocument31 pagesMeasures of VariationMerjie A. NunezNo ratings yet
- Analysis of Automobile Sales in Top 10 States of IndiaDocument26 pagesAnalysis of Automobile Sales in Top 10 States of IndiaAayush SinghNo ratings yet
- Statistics and Probability: Exploring Rejection RegionDocument15 pagesStatistics and Probability: Exploring Rejection RegionJyeoNo ratings yet
- Tugas Statistik 6Document4 pagesTugas Statistik 6Zyad KemalNo ratings yet
- (BAFI 1045) T03 (Markowitz Portfolio)Document46 pages(BAFI 1045) T03 (Markowitz Portfolio)Red RingoNo ratings yet
- Statistics Beginners GuideDocument42 pagesStatistics Beginners GuideAhmad MakhloufNo ratings yet
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Module On Basic Statistical ConceptsDocument21 pagesModule On Basic Statistical ConceptsEllaine PaladinNo ratings yet
- Standard and Quartile DeviationDocument7 pagesStandard and Quartile DeviationGemine Ailna Panganiban NuevoNo ratings yet
- Assignment-XIDocument2 pagesAssignment-XIAbhishek PanditNo ratings yet
- Sampling Distributions: Digital Image Powerpoint To AccompanyDocument36 pagesSampling Distributions: Digital Image Powerpoint To AccompanyChris TanNo ratings yet
- Asset-V1 TUMx+QPLS1x+2T2018+type@asset+block@QPLS1X 6-4 Sampling Plans - Part 1 PDFDocument7 pagesAsset-V1 TUMx+QPLS1x+2T2018+type@asset+block@QPLS1X 6-4 Sampling Plans - Part 1 PDFPedro CostaNo ratings yet
- ManagementDocument3 pagesManagementNo MoreNo ratings yet
- Gridding Report - : Data SourceDocument7 pagesGridding Report - : Data SourcekukuhNo ratings yet
- Statistics and Prob 11 Summative Test 1,2 and 3 Q4Document3 pagesStatistics and Prob 11 Summative Test 1,2 and 3 Q4Celine Mary DamianNo ratings yet
- Introduction To SamplingDocument10 pagesIntroduction To Samplingadiba ridahNo ratings yet






















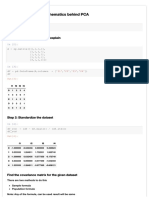


















































































Download as pdf or txt
You might also like
- Module 4 (Data Management) - Math 101Document8 pagesModule 4 (Data Management) - Math 101Flory CabaseNo ratings yet
- Tutorial For StatgraphicsDocument53 pagesTutorial For StatgraphicsSaúl DtNo ratings yet
- E21CSEU0770 Lab4Document4 pagesE21CSEU0770 Lab4kumar.nayan26No ratings yet
- Lecture3 2018Document16 pagesLecture3 2018Stefan-Aurelian ApostolNo ratings yet
- LT05 L1TP 003056 20091218 20161017 01 T1 AngDocument13 pagesLT05 L1TP 003056 20091218 20161017 01 T1 AngMilenaNo ratings yet
- Stock Prediction Web App - Jupyter NotebookDocument12 pagesStock Prediction Web App - Jupyter Notebookashutosh312004No ratings yet
- Regression DemoDocument8 pagesRegression Demorxn114392No ratings yet
- 1 Solution1Document6 pages1 Solution1Mix-Kat ZiakaNo ratings yet
- Source Code in PDF FormatDocument15 pagesSource Code in PDF FormatShivam PrajapatiNo ratings yet
- Ridge - Lasso - Regression (1) .Ipynb - ColaboratoryDocument4 pagesRidge - Lasso - Regression (1) .Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- DLL 7 Harsh Kabir 2203254Document6 pagesDLL 7 Harsh Kabir 2203254Darshil RajNo ratings yet
- Name: Shreyash Kharat Homework: Hw3 (Problem 1)Document7 pagesName: Shreyash Kharat Homework: Hw3 (Problem 1)Mainak SamantaNo ratings yet
- Quiz Data ScienseDocument8 pagesQuiz Data Scienseada sajaNo ratings yet
- Chapter 4Document28 pagesChapter 4sulavdklNo ratings yet
- MScFE 300 Group Work Project 2 Python CodesDocument2 pagesMScFE 300 Group Work Project 2 Python CodesBryanNo ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- PembelajaranMesin - Ipynb - ColaboratoryDocument6 pagesPembelajaranMesin - Ipynb - ColaboratoryKhaerul RijalNo ratings yet
- Merging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - ColaboratoryDocument16 pagesMerging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - Colaboratorygirishcherry12100% (1)
- Import As Import As From Import: "Mean Squared Errors: "Document1 pageImport As Import As From Import: "Mean Squared Errors: "ulNo ratings yet
- Euler Explicit Jan2024Document11 pagesEuler Explicit Jan2024getachewbonga09No ratings yet
- 1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingDocument4 pages1 Reducing Dimensionality From 4D To 1D: Numpy NP Pandas PD Sklearn Sklearn - PreprocessingAsmar HajizadaNo ratings yet
- Data Preprocessing ML LabDocument6 pagesData Preprocessing ML Labmohan kukrejaNo ratings yet
- PCA Code-CheckpointDocument4 pagesPCA Code-CheckpointАурел ПNo ratings yet
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- KMeans Clustering Bidimensional Daniel Ames CamayoDocument15 pagesKMeans Clustering Bidimensional Daniel Ames CamayoEl RusnderNo ratings yet
- Lab - 7 - 21130616 - TranhThanhVu - Ipynb - ColabDocument10 pagesLab - 7 - 21130616 - TranhThanhVu - Ipynb - Colabnguyennhutoan722003No ratings yet
- Coding Tugas Besar Analitika DataDocument7 pagesCoding Tugas Besar Analitika Datarizqullahm14No ratings yet
- LT05 L2SP 179032 19990818 20200908 02 T1 AngDocument13 pagesLT05 L2SP 179032 19990818 20200908 02 T1 AngAnas Sharafeldin Mohamed OsmanNo ratings yet
- Ilovepdf MergedDocument47 pagesIlovepdf MergedSIDDHANT MANDALNo ratings yet
- Assumption of Linear RegressionDocument6 pagesAssumption of Linear RegressionKagade AjinkyaNo ratings yet
- Le07 L1TP 184028 19991203 20170216 01 T1 AngDocument16 pagesLe07 L1TP 184028 19991203 20170216 01 T1 AngMag ClaudiaNo ratings yet
- LT05 L1TP 190055 19841211 20170219 01 T1 AngDocument13 pagesLT05 L1TP 190055 19841211 20170219 01 T1 AngmodupeNo ratings yet
- Le07 L1TP 120065 20020821 20200916 02 T1 AngDocument16 pagesLe07 L1TP 120065 20020821 20200916 02 T1 AngklklklklklklklklklkkNo ratings yet
- Matlab Code: Question No: 4 (A)Document11 pagesMatlab Code: Question No: 4 (A)ihsan yaseenNo ratings yet
- LT05 L2SP 148045 20111114 20200820 02 T1 AngDocument13 pagesLT05 L2SP 148045 20111114 20200820 02 T1 Angksuhail44444No ratings yet
- Project 8 Predictive Analytics - Ipynb - ColaboratoryDocument8 pagesProject 8 Predictive Analytics - Ipynb - ColaboratoryaadityadeolalikarNo ratings yet
- Desarrollo Modelo Random Forest Preparamos El Entorno de SparkDocument3 pagesDesarrollo Modelo Random Forest Preparamos El Entorno de SparkFacundo VarasNo ratings yet
- Jupyter Notebook Yardlenis Sánchez Act2Document1 pageJupyter Notebook Yardlenis Sánchez Act2NASLYNo ratings yet
- Compute Fibonacci Using Java and ParallelizationDocument2,713 pagesCompute Fibonacci Using Java and ParallelizationIoan Simion BelbeNo ratings yet
- Y # - Y Matrix SetupDocument11 pagesY # - Y Matrix SetupSeymurH-vNo ratings yet
- 2 - 9 - KNN CodeDocument6 pages2 - 9 - KNN CodeYahya SabriNo ratings yet
- Basant Kumar Adm - No.-16je002220 SEMESTER-4th: Matlab Assignment No.-2 NameDocument4 pagesBasant Kumar Adm - No.-16je002220 SEMESTER-4th: Matlab Assignment No.-2 NameBasant KumarNo ratings yet
- Portfoliompt1: 1 Universidad Nacional de IngenieríaDocument10 pagesPortfoliompt1: 1 Universidad Nacional de IngenieríaArnold MontesinosNo ratings yet
- LT05 L1TP 183028 20010904 20180501 01 T1 AngDocument13 pagesLT05 L1TP 183028 20010904 20180501 01 T1 AngClaudia Cristina MagNo ratings yet
- Import AsDocument27 pagesImport AsFozia Dawood100% (1)
- BS SRR-3Document20 pagesBS SRR-3anveshvarma365No ratings yet
- Take-Home Test 1 AE3110 Aerodinamika: Oleh: Muhammad Rizki ZuhriDocument11 pagesTake-Home Test 1 AE3110 Aerodinamika: Oleh: Muhammad Rizki ZuhriMuhammad Rizki ZuhriNo ratings yet
- Pattern - Recognition - 3 - Code With OutputDocument7 pagesPattern - Recognition - 3 - Code With OutputReem NasserNo ratings yet
- 19mis1112 Lab1Document10 pages19mis1112 Lab1Fèdríck SämùélNo ratings yet
- Assignment Seminar 8Document4 pagesAssignment Seminar 8KNo ratings yet
- Question 1 (15) - Multiple Choice To Be Answered On Multiple Choice Sheet FormDocument6 pagesQuestion 1 (15) - Multiple Choice To Be Answered On Multiple Choice Sheet FormNicholas RuestNo ratings yet
- LT05 L1TP 173033 20110910 20200820 02 T1 AngDocument13 pagesLT05 L1TP 173033 20110910 20200820 02 T1 Angmerve1099No ratings yet
- PandasDocument21 pagesPandasShubham dattatray koteNo ratings yet
- Parte 1. Problemas Sobre Tema 2.: Unrecognized Function or Variable 'B'Document10 pagesParte 1. Problemas Sobre Tema 2.: Unrecognized Function or Variable 'B'EMILIO RODRIGUEZ CALDERONNo ratings yet
- TranMinhTu1 bt2 2Document5 pagesTranMinhTu1 bt2 2Trần Minh TúNo ratings yet
- 2 Fourier Transforms CorDocument8 pages2 Fourier Transforms CorCəvahir AğazadəNo ratings yet
- PythonDocument4 pagesPythonESTUDIANTE JOSE DAVID MARTINEZ RODRIGUEZNo ratings yet
- DIMENSIÓN.Z, Método MatricialDocument29 pagesDIMENSIÓN.Z, Método MatricialAlison GonzálezNo ratings yet
- Labpractice 2Document29 pagesLabpractice 2Rajashree Das100% (2)
- ROC and AUC Practical Implementation PDFDocument6 pagesROC and AUC Practical Implementation PDFNermine LimemeNo ratings yet
- False Position Method PracticalDocument3 pagesFalse Position Method PracticalPrakriti SaxenaNo ratings yet
- 08 Decision - TreeDocument9 pages08 Decision - TreeGabriel GheorgheNo ratings yet
- B Ridge - and - Lasso - RegressionDocument5 pagesB Ridge - and - Lasso - RegressionGabriel GheorgheNo ratings yet
- 13 Cross - ValidationDocument4 pages13 Cross - ValidationGabriel GheorgheNo ratings yet
- 02 MulticollinearityDocument8 pages02 MulticollinearityGabriel Gheorghe100% (1)
- 03 A Polynomial Linear RegressionDocument6 pages03 A Polynomial Linear RegressionGabriel GheorgheNo ratings yet
- Ensemble LearningDocument7 pagesEnsemble LearningGabriel Gheorghe100% (1)
- Backward && Forward Feature Selection PART-2Document6 pagesBackward && Forward Feature Selection PART-2Gabriel GheorgheNo ratings yet
- 22 Dim Reduction Part-1Document9 pages22 Dim Reduction Part-1Gabriel GheorgheNo ratings yet
- GroupsDocument1 pageGroupsGabriel GheorgheNo ratings yet
- Projects ExperienceDocument19 pagesProjects ExperienceGabriel GheorgheNo ratings yet
- Dev OpsDocument1 pageDev OpsGabriel GheorgheNo ratings yet
- Knowledge Learning Steps Learnig in ServiceNowDocument1 pageKnowledge Learning Steps Learnig in ServiceNowGabriel GheorgheNo ratings yet
- Service NowDocument2 pagesService NowGabriel GheorgheNo ratings yet
- JD - Senior Java Developer - Extenda Officecentral - 40580Document2 pagesJD - Senior Java Developer - Extenda Officecentral - 40580Gabriel GheorgheNo ratings yet
- An Artificial Intelligence Browser Architecture AIDocument11 pagesAn Artificial Intelligence Browser Architecture AIGabriel GheorgheNo ratings yet
- AddsupDocument2 pagesAddsupGabriel GheorgheNo ratings yet
- BSC-301 - Probability - Distribution 3Document8 pagesBSC-301 - Probability - Distribution 3Precisive OneNo ratings yet
- 11 Data VisualizationDocument44 pages11 Data VisualizationYEOWNo ratings yet
- Stat Prob Q4 Module 3Document21 pagesStat Prob Q4 Module 3Lailanie Fortu60% (5)
- Historical Data RSM Tutorial (Part 2 - Advanced Topics) : Design EvaluationDocument6 pagesHistorical Data RSM Tutorial (Part 2 - Advanced Topics) : Design Evaluationjamunaa83No ratings yet
- School of Applied Mathematics and Informatics: H H H H H HDocument1 pageSchool of Applied Mathematics and Informatics: H H H H H HHưng Đoàn VănNo ratings yet
- Output Statistics Frequency Table: Penyembuhan Luka Pasien Post OperasiDocument5 pagesOutput Statistics Frequency Table: Penyembuhan Luka Pasien Post OperasiDetdet343No ratings yet
- The Influence of Tax Knowledge, Taxpayer Awareness, And Tax Rates on the Compliance of Individual Taxpayers With Tax Sanctions as a Moderating Variable in E-Commerce Business Activities (Case Study at Online Shop Owner in IndoDocument12 pagesThe Influence of Tax Knowledge, Taxpayer Awareness, And Tax Rates on the Compliance of Individual Taxpayers With Tax Sanctions as a Moderating Variable in E-Commerce Business Activities (Case Study at Online Shop Owner in IndoInternational Journal of Innovative Science and Research Technology100% (1)
- Random Effects Probit and Logit Understanding Predictions and Marginal EffectsDocument9 pagesRandom Effects Probit and Logit Understanding Predictions and Marginal EffectsEdwin ReveloNo ratings yet
- Business Statistics-Spss Assignment: Group A8Document6 pagesBusiness Statistics-Spss Assignment: Group A8Alina KujurNo ratings yet
- Box Plot Answers MMEDocument2 pagesBox Plot Answers MMESabih AzharNo ratings yet
- (Written Examination Scheme) : (MCQ S)Document4 pages(Written Examination Scheme) : (MCQ S)rahulNo ratings yet
- Measures of VariationDocument31 pagesMeasures of VariationMerjie A. NunezNo ratings yet
- Analysis of Automobile Sales in Top 10 States of IndiaDocument26 pagesAnalysis of Automobile Sales in Top 10 States of IndiaAayush SinghNo ratings yet
- Statistics and Probability: Exploring Rejection RegionDocument15 pagesStatistics and Probability: Exploring Rejection RegionJyeoNo ratings yet
- Tugas Statistik 6Document4 pagesTugas Statistik 6Zyad KemalNo ratings yet
- (BAFI 1045) T03 (Markowitz Portfolio)Document46 pages(BAFI 1045) T03 (Markowitz Portfolio)Red RingoNo ratings yet
- Statistics Beginners GuideDocument42 pagesStatistics Beginners GuideAhmad MakhloufNo ratings yet
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Module On Basic Statistical ConceptsDocument21 pagesModule On Basic Statistical ConceptsEllaine PaladinNo ratings yet
- Standard and Quartile DeviationDocument7 pagesStandard and Quartile DeviationGemine Ailna Panganiban NuevoNo ratings yet
- Assignment-XIDocument2 pagesAssignment-XIAbhishek PanditNo ratings yet
- Sampling Distributions: Digital Image Powerpoint To AccompanyDocument36 pagesSampling Distributions: Digital Image Powerpoint To AccompanyChris TanNo ratings yet
- Asset-V1 TUMx+QPLS1x+2T2018+type@asset+block@QPLS1X 6-4 Sampling Plans - Part 1 PDFDocument7 pagesAsset-V1 TUMx+QPLS1x+2T2018+type@asset+block@QPLS1X 6-4 Sampling Plans - Part 1 PDFPedro CostaNo ratings yet
- ManagementDocument3 pagesManagementNo MoreNo ratings yet
- Gridding Report - : Data SourceDocument7 pagesGridding Report - : Data SourcekukuhNo ratings yet
- Statistics and Prob 11 Summative Test 1,2 and 3 Q4Document3 pagesStatistics and Prob 11 Summative Test 1,2 and 3 Q4Celine Mary DamianNo ratings yet
- Introduction To SamplingDocument10 pagesIntroduction To Samplingadiba ridahNo ratings yet