Download as pdf or txt
You might also like
- Software Development Techniques 07 March 2019 Examination PaperDocument7 pagesSoftware Development Techniques 07 March 2019 Examination PaperAsifHossain100% (1)
- Univariate Time SeriesDocument132 pagesUnivariate Time SeriesWesley Miller Perez OrtizNo ratings yet
- ACFDocument27 pagesACFAnand SatsangiNo ratings yet
- Session 13A - The ARMA and ARIMA ModelsDocument173 pagesSession 13A - The ARMA and ARIMA ModelskhkarthikNo ratings yet
- Univariate Time SeriesDocument83 pagesUnivariate Time SeriesVishnuChaithanyaNo ratings yet
- Univariate Time SeriesDocument83 pagesUnivariate Time SeriesShashank Gupta100% (1)
- Lecture 7 PDFDocument30 pagesLecture 7 PDFemy anishaNo ratings yet
- Chapter - AR and MA 7. Dec. 2020Document60 pagesChapter - AR and MA 7. Dec. 2020Khánh Đoan Lê ĐìnhNo ratings yet
- BSC Honours in Statistics: HSTS 203: Time Series Analysis University of ZimbabweDocument6 pagesBSC Honours in Statistics: HSTS 203: Time Series Analysis University of ZimbabweKeith Tanyaradzwa MushiningaNo ratings yet
- Topic 4-StudentDocument54 pagesTopic 4-StudentAqim AzamNo ratings yet
- Time Series AnalysisDocument5 pagesTime Series AnalysisMaged Al-BarashiNo ratings yet
- ACFDocument27 pagesACFShalini VelappanNo ratings yet
- I. Introduction To Time Series Analysis: X X ... X X XDocument56 pagesI. Introduction To Time Series Analysis: X X ... X X XCollins MuseraNo ratings yet
- Mechatronics Frequency Response Analysis & Design K. Craig 1Document121 pagesMechatronics Frequency Response Analysis & Design K. Craig 1rub786No ratings yet
- Time Series 2 - 2Document12 pagesTime Series 2 - 2MFaisalAbdaHasanNo ratings yet
- Chapter 4. ARIMA - SVDocument49 pagesChapter 4. ARIMA - SVthucnhi.2003hnntNo ratings yet
- Stochastic Process - IntroductionDocument16 pagesStochastic Process - IntroductionRajesh BathijaNo ratings yet
- Time Series Station, AR, MADocument30 pagesTime Series Station, AR, MAHospital BasisNo ratings yet
- Chapter9 Econometrics AutocorrelationDocument17 pagesChapter9 Econometrics Autocorrelationamwai davidNo ratings yet
- TSNotes 2Document28 pagesTSNotes 2YANGYUXINNo ratings yet
- 23 Oct 2020 Datavisualization TimeseriesDocument17 pages23 Oct 2020 Datavisualization TimeseriesAditya MishraNo ratings yet
- ACS Experiments 3,4Document5 pagesACS Experiments 3,4Aditya SharmaNo ratings yet
- Stationary ProcessDocument178 pagesStationary ProcessMohamed AsimNo ratings yet
- JML ArimaDocument37 pagesJML Arimapg aiNo ratings yet
- Chapter 3Document25 pagesChapter 3Jose C Beraun TapiaNo ratings yet
- Frequency Response Analysis and Design PDFDocument281 pagesFrequency Response Analysis and Design PDFfergusoniseNo ratings yet
- Time Series and Sequential DataDocument143 pagesTime Series and Sequential DataSamuel hinn lionelNo ratings yet
- Gakhov Time Series Forecasting With PythonDocument66 pagesGakhov Time Series Forecasting With PythonSadık DelioğluNo ratings yet
- Time - Series - in - BriefDocument11 pagesTime - Series - in - BriefPrak ParasharNo ratings yet
- TR Time Series June2012Document20 pagesTR Time Series June2012TORAJ INTEAASHI RCBSNo ratings yet
- Time Series AnalysisDocument10 pagesTime Series AnalysisJayson VillezaNo ratings yet
- Time Series AnalysisDocument58 pagesTime Series Analysistanishq kansalNo ratings yet
- Stata Lab4 2023Document36 pagesStata Lab4 2023Aadhav JayarajNo ratings yet
- Time Series Analysis: Autocorrelation: Chatfield (1996) Chapter 2 (Example: Rebel Et Al., 2012)Document6 pagesTime Series Analysis: Autocorrelation: Chatfield (1996) Chapter 2 (Example: Rebel Et Al., 2012)Nina BrownNo ratings yet
- Time Series Modeling: Shouvik Mani April 5, 2018Document46 pagesTime Series Modeling: Shouvik Mani April 5, 2018Salvador RamirezNo ratings yet
- 3ARIMA and Box JenkinsDocument32 pages3ARIMA and Box JenkinsAstrid TanNo ratings yet
- Time Series Analysis and ForecastingDocument21 pagesTime Series Analysis and Forecastingmaria saleemNo ratings yet
- Frequency Analysis in HydrologyDocument24 pagesFrequency Analysis in Hydrologysuman59No ratings yet
- Ch6 Slides Ed3 Feb2021Document63 pagesCh6 Slides Ed3 Feb2021Phuc Hong PhamNo ratings yet
- Monte Carlo Simulation (ARIMA Time Series Models)Document15 pagesMonte Carlo Simulation (ARIMA Time Series Models)Anonymous FZNn6rBNo ratings yet
- EViews LabDocument13 pagesEViews LabZakia ShaheenNo ratings yet
- FRM - 2 - Chapter 2Document57 pagesFRM - 2 - Chapter 2Nguyễn Thị Mỹ HạnhNo ratings yet
- Lecture - L5 - Time Series ECMDocument28 pagesLecture - L5 - Time Series ECMJaka PratamaNo ratings yet
- LU 9 Modelling PDFDocument47 pagesLU 9 Modelling PDFThanachporn RatananukromNo ratings yet
- Econometrics Year 3 EcoDocument185 pagesEconometrics Year 3 Ecoantoinette MWANAKASALANo ratings yet
- Mccormick 1998 Cyclostationarity in Rotating MachiDocument23 pagesMccormick 1998 Cyclostationarity in Rotating MachijudarangocaNo ratings yet
- 454 2013Document11 pages454 2013Suresh KumarNo ratings yet
- 2 Basic RegressionDocument69 pages2 Basic RegressionGiang HoangNo ratings yet
- Identification and Estimation - OxfordDocument28 pagesIdentification and Estimation - OxfordAnimesh Kumar JhaNo ratings yet
- Intro of Time SeriesDocument18 pagesIntro of Time SeriesDr.Surajit DasNo ratings yet
- Chapter 2slideDocument103 pagesChapter 2slideYared brhaneNo ratings yet
- SlidesDocument31 pagesSlidesKaran GautamNo ratings yet
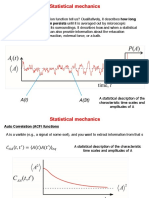
- Statistical Mechanics: A (T) A (3t)Document13 pagesStatistical Mechanics: A (T) A (3t)Abdul Aziz KhanNo ratings yet
- Molecular DynamicsDocument22 pagesMolecular DynamicsSaliya Ranashigha BandaraNo ratings yet
- A Data-Driven Model For Software Reliability PredictionDocument32 pagesA Data-Driven Model For Software Reliability Predictionsleepanon4362No ratings yet
- KCS301 Unit1 Lec2Document23 pagesKCS301 Unit1 Lec2utkarshNo ratings yet
- Slva 589Document12 pagesSlva 589Omar MohamedNo ratings yet
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- Robot Manipulators: Modeling, Performance Analysis and ControlFrom EverandRobot Manipulators: Modeling, Performance Analysis and ControlNo ratings yet
- SEE6101 04 HeatEngine 2015Document38 pagesSEE6101 04 HeatEngine 2015kk chanNo ratings yet
- SEE6101 01 IntroToEnergy 2015Document47 pagesSEE6101 01 IntroToEnergy 2015kk chanNo ratings yet
- SEE6101 02 FossilFuel 2015Document60 pagesSEE6101 02 FossilFuel 2015kk chanNo ratings yet
- SEE5211 Chapter4 P2017Document58 pagesSEE5211 Chapter4 P2017kk chanNo ratings yet
- SEE6101 03 BiomassEnergy 2015Document54 pagesSEE6101 03 BiomassEnergy 2015kk chanNo ratings yet
- SEE5211 Chapter5 P2017Document48 pagesSEE5211 Chapter5 P2017kk chanNo ratings yet
- SEE5211 Chapter3-P2017Document58 pagesSEE5211 Chapter3-P2017kk chanNo ratings yet
- SEE5211 Chapter1 P2017Document60 pagesSEE5211 Chapter1 P2017kk chanNo ratings yet
- SEE5211 Chapter2 p2017Document47 pagesSEE5211 Chapter2 p2017kk chanNo ratings yet
- Integer Linear Programming: Penelitian Operasional IDocument8 pagesInteger Linear Programming: Penelitian Operasional IIndahNo ratings yet
- ROBLES - Module 4 QuestionDocument3 pagesROBLES - Module 4 QuestionClint RoblesNo ratings yet
- 9 Blast1Document8 pages9 Blast1swatiNo ratings yet
- Iterative Learning Control ReportDocument20 pagesIterative Learning Control ReportHoàng HứaNo ratings yet
- 8 Tree Searching Algorithms: H. KaindlDocument2 pages8 Tree Searching Algorithms: H. Kaindldaeas jeryNo ratings yet
- 4 TreesDocument2 pages4 TreesNguyen Tien Dat (K18 HL)No ratings yet
- Design and Implement Special Stack Data Structure - Added Space Optimized Version - GeeksforGeeksDocument35 pagesDesign and Implement Special Stack Data Structure - Added Space Optimized Version - GeeksforGeekslongphiycNo ratings yet
- Deep Learning-Based Sentiment Classification in Amharic Using Multi-Lingual DatasetsDocument24 pagesDeep Learning-Based Sentiment Classification in Amharic Using Multi-Lingual Datasetswudnew306No ratings yet
- Chapter - Calculus: Ax BX + CFT Ax BX + 0Document19 pagesChapter - Calculus: Ax BX + CFT Ax BX + 0Ricardo VillalongaNo ratings yet
- PDCDocument14 pagesPDCzapperfatterNo ratings yet
- Similarity Measure For Categorical DataDocument8 pagesSimilarity Measure For Categorical DataNeti SuherawatiNo ratings yet
- Cryptography - Final ProjectDocument8 pagesCryptography - Final Projectapi-413364164No ratings yet
- Euler's and Runge-Kutta Method PDFDocument8 pagesEuler's and Runge-Kutta Method PDFClearMind84No ratings yet
- Discrim An ExamDocument2 pagesDiscrim An ExamAlexandre GumNo ratings yet
- Introduction To Data Classification and PredictionDocument9 pagesIntroduction To Data Classification and PredictionSuman GhoraiNo ratings yet
- Sample Forecasting ProblemDocument11 pagesSample Forecasting ProblemBaby Jean Odrunia VillarNo ratings yet
- Rpa M3Document28 pagesRpa M3VAISHNAVINo ratings yet
- NP CompleteDocument32 pagesNP CompleteSabaniNo ratings yet
- Sathyabama University: Register NumberDocument4 pagesSathyabama University: Register NumberBhavya BabuNo ratings yet
- CSE (Prerequisite)Document2 pagesCSE (Prerequisite)FAHMIDA JAMILNo ratings yet
- Applications of Matrices in Real Life PDFDocument14 pagesApplications of Matrices in Real Life PDFSureshi BishtNo ratings yet
- PHD Thesis On Elliptic Curve CryptographyDocument6 pagesPHD Thesis On Elliptic Curve Cryptographylorigilbertgilbert100% (2)
- Detail - Example 2-Goal Programming-12 EmployeesDocument9 pagesDetail - Example 2-Goal Programming-12 EmployeesRenad ObaidNo ratings yet
- Personal Comfort Models Predicting Individuals' Thermal Preference Using Occupant Heating and Cooling Behavior and Machine LearningDocument11 pagesPersonal Comfort Models Predicting Individuals' Thermal Preference Using Occupant Heating and Cooling Behavior and Machine LearningHimanshu PatelNo ratings yet
- CP5639 Week 4 PRACTICE On ITERATIONSDocument11 pagesCP5639 Week 4 PRACTICE On ITERATIONSRanjith KrishnaNo ratings yet
- State Feedback Control AlgorithmDocument6 pagesState Feedback Control AlgorithmManav VoraNo ratings yet
- CS 563-DeepLearning-SentimentApplication-April2022 (27403)Document124 pagesCS 563-DeepLearning-SentimentApplication-April2022 (27403)Varaprasad DNo ratings yet
- Indexes and View and Other Important Interview QuestionsDocument11 pagesIndexes and View and Other Important Interview QuestionsBathula SudhakarNo ratings yet
- LP Solved ProblemsDocument5 pagesLP Solved ProblemsAaronLumibao100% (1)