Download as pdf or txt
You might also like
- Hypothesis Testing RoadmapDocument2 pagesHypothesis Testing RoadmapRam KumarNo ratings yet
- Logit MultinomialDocument16 pagesLogit MultinomialBruno BaiaNo ratings yet
- TsvarsvarDocument19 pagesTsvarsvarOğuzhan ÖzçelebiNo ratings yet
- XtxtnbregDocument13 pagesXtxtnbregalicorpanaoNo ratings yet
- XtxtmlogitDocument31 pagesXtxtmlogitAmoussouNo ratings yet
- RbiprobitDocument8 pagesRbiprobitDaniel Redel SaavedraNo ratings yet
- Bivariate Probit RegressionDocument7 pagesBivariate Probit RegressionnovanikarineNo ratings yet
- TsvarDocument12 pagesTsvartayson1212No ratings yet
- Tss SpaceDocument24 pagesTss SpaceJENNY MINAYANo ratings yet
- Depvarlist If In: Vec - Vector Error-Correction ModelsDocument24 pagesDepvarlist If In: Vec - Vector Error-Correction ModelsAdalberto CalsinNo ratings yet
- XtxtgeeDocument19 pagesXtxtgeejminyosoNo ratings yet
- MCA Using Stata PDFDocument22 pagesMCA Using Stata PDFAbdoulkarimNo ratings yet
- Comando XtprobitDocument20 pagesComando Xtprobitjc224No ratings yet
- Ayuda Comandos Stata MetaDocument42 pagesAyuda Comandos Stata Metaread03541No ratings yet
- Xtgls - Fit Panel-Data Models by Using GLSDocument11 pagesXtgls - Fit Panel-Data Models by Using GLSNha LeNo ratings yet
- R MaximizeDocument7 pagesR MaximizeMariia SungatullinaNo ratings yet
- RfrontierDocument15 pagesRfrontierzainurihanifNo ratings yet
- Varlist: Robust - Robust Variance EstimatesDocument24 pagesVarlist: Robust - Robust Variance EstimatesAsep KusnaliNo ratings yet
- XtxtpcseDocument11 pagesXtxtpcsemuniya altezaNo ratings yet
- CausaldidregressDocument35 pagesCausaldidregresseflitadataNo ratings yet
- Varlist If in Weight Options: Pca - Principal Component AnalysisDocument17 pagesVarlist If in Weight Options: Pca - Principal Component AnalysisclmarinNo ratings yet
- RnpregresskernelDocument24 pagesRnpregresskernelDaniel Redel SaavedraNo ratings yet
- XtxtdpdsysDocument11 pagesXtxtdpdsysUttam GolderNo ratings yet
- Hausman - Hausman Specification TestDocument10 pagesHausman - Hausman Specification TestSaiganesh RameshNo ratings yet
- Robust - Robust Variance EstimatesDocument25 pagesRobust - Robust Variance Estimatessarbaz0003No ratings yet
- Stata Help Hausman Test PDFDocument9 pagesStata Help Hausman Test PDFHabib AhmadNo ratings yet
- Using MFP in Stata To Get The Best Polynomial Equation For StsetDocument12 pagesUsing MFP in Stata To Get The Best Polynomial Equation For StsetalicorpanaoNo ratings yet
- BayesbayesxtregDocument4 pagesBayesbayesxtregBelaynehYitayewNo ratings yet
- Suest - Seemingly Unrelated Estimation: 20 Estimation and Postestimation CommandsDocument19 pagesSuest - Seemingly Unrelated Estimation: 20 Estimation and Postestimation Commandseko abiNo ratings yet
- RoprobitDocument6 pagesRoprobitAmoussouNo ratings yet
- RbetaregDocument10 pagesRbetaregBaron BulayaNo ratings yet
- LWP ManualDocument14 pagesLWP ManualShabbir OsmaniNo ratings yet
- Support Vector Machines: The Interface To Libsvm in Package E1071 by David Meyer FH Technikum Wien, AustriaDocument8 pagesSupport Vector Machines: The Interface To Libsvm in Package E1071 by David Meyer FH Technikum Wien, AustriaDoom Head 47No ratings yet
- Estimating Dynamic Common Correlated Effects Models in StataDocument41 pagesEstimating Dynamic Common Correlated Effects Models in StataSAWADOGONo ratings yet
- RmprobitDocument8 pagesRmprobitlompoNo ratings yet
- Suest - Seemingly Unrelated Estimation: 20 Estimation and Postestimation CommandsDocument19 pagesSuest - Seemingly Unrelated Estimation: 20 Estimation and Postestimation Commandseko abiNo ratings yet
- Useful Stata Commands - 2012 PDFDocument2 pagesUseful Stata Commands - 2012 PDFroberthtaipevNo ratings yet
- Marginal EffectsDocument16 pagesMarginal EffectsAmol GajdhaneNo ratings yet
- 1.4. Support Vector Machines - Scikit-LearnDocument6 pages1.4. Support Vector Machines - Scikit-LearnAmit DeshaiNo ratings yet
- Poisson RegressionDocument10 pagesPoisson RegressionUNLV234No ratings yet
- Depvar Indepvars Numlist Numlist: Arima - ARIMA, ARMAX, and Other Dynamic Regression ModelsDocument24 pagesDepvar Indepvars Numlist Numlist: Arima - ARIMA, ARMAX, and Other Dynamic Regression ModelsJimena MartinNo ratings yet
- Estimating DSGE Models With DynareDocument45 pagesEstimating DSGE Models With DynareGilbert ADJASSOUNo ratings yet
- SvmdocDocument8 pagesSvmdocEZ112No ratings yet
- Stata Time Series VarsocDocument6 pagesStata Time Series Varsocaiwen_wong2428No ratings yet
- Ucm - Unobserved-Components ModelDocument29 pagesUcm - Unobserved-Components ModelPaul RadidoNo ratings yet
- Support Vector Machines: The Interface To Libsvm in Package E1071 by David Meyer FH Technikum Wien, AustriaDocument8 pagesSupport Vector Machines: The Interface To Libsvm in Package E1071 by David Meyer FH Technikum Wien, AustriaAmish SharmaNo ratings yet
- Pca - STATADocument17 pagesPca - STATAAnonymous U5RYS6NqNo ratings yet
- MSVARDocument10 pagesMSVARCJC FinancesNo ratings yet
- Stata LogisticDocument4 pagesStata Logisticmohammad_zayed_7No ratings yet
- Multivariate EWMA Control Chart: Large Medium Small Means CovariancesDocument12 pagesMultivariate EWMA Control Chart: Large Medium Small Means Covariancesvista10No ratings yet
- Xtregar - Fixed-And Random-Effects Linear Models With An AR (1) DisturbanceDocument15 pagesXtregar - Fixed-And Random-Effects Linear Models With An AR (1) DisturbanceDiego Armando Pérez ReséndizNo ratings yet
- Translate - Varying Coefficient Models in Stata - v4Document40 pagesTranslate - Varying Coefficient Models in Stata - v4Arq. AcadêmicoNo ratings yet
- Stata Post Publication UpdateDocument20 pagesStata Post Publication UpdateChalee InkateNo ratings yet
- Varlist Exp: Alphabetical List of Common Stata CommandsDocument3 pagesVarlist Exp: Alphabetical List of Common Stata CommandsKwao LazarusNo ratings yet
- Time Series AnalysisDocument6 pagesTime Series AnalysisLibertyNo ratings yet
- Stata Ts Introduction To Time-Series CommandsDocument6 pagesStata Ts Introduction To Time-Series CommandsngocmimiNo ratings yet
- Chapter - 3 Common Statistical ProcedureDocument20 pagesChapter - 3 Common Statistical ProcedureYopi YansahNo ratings yet
- Codigos para STATADocument9 pagesCodigos para STATAPilar CarterNo ratings yet
- Gamma Distribution FittingDocument14 pagesGamma Distribution Fittingmipimipi03No ratings yet
- XsmleDocument37 pagesXsmleRickie Wiradz WahyudiNo ratings yet
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningFrom EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNo ratings yet
- Multiple Linear Regression (Continue) Example:: CO Product Y Solvent Total X Hydrogen Consumption X Y X Y X Y X XDocument4 pagesMultiple Linear Regression (Continue) Example:: CO Product Y Solvent Total X Hydrogen Consumption X Y X Y X Y X XMuhammad BilalNo ratings yet
- Testul Chi PatratDocument9 pagesTestul Chi PatratgeorgianapetrescuNo ratings yet
- Mat530 MM A1 2012 - EditedDocument11 pagesMat530 MM A1 2012 - Editedquiah89No ratings yet
- Bayesian and Maximum Likelihood Estimations of The Dagum Parameters Under Combined-Unified Hybrid CensoringDocument22 pagesBayesian and Maximum Likelihood Estimations of The Dagum Parameters Under Combined-Unified Hybrid Censoringحسن الفضيلNo ratings yet
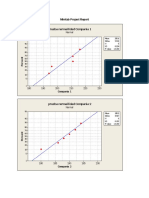
- Minitab Project ReportDocument3 pagesMinitab Project Reportramonfer79No ratings yet
- Production Planning and Control (MEFB 433) : Ts. Zubaidi Faiesal Email: Zubaidi@uniten - Edu.my Room No. BN-1-010Document36 pagesProduction Planning and Control (MEFB 433) : Ts. Zubaidi Faiesal Email: Zubaidi@uniten - Edu.my Room No. BN-1-010Sritaran BalakrishnanNo ratings yet
- Chapter 1Document34 pagesChapter 1Komi David ABOTSITSENo ratings yet
- "Responsi Praktikum": Statistik PertanianDocument6 pages"Responsi Praktikum": Statistik PertanianSefa FalahudinNo ratings yet
- Chapter 6Document5 pagesChapter 6Nermine LimemeNo ratings yet
- Statistics and ProbabilityDocument5 pagesStatistics and ProbabilityTrisTan Dolojan0% (1)
- ch09 PDFDocument44 pagesch09 PDFHemraj VermaNo ratings yet
- Performance Task 1 Proby and StatDocument1 pagePerformance Task 1 Proby and StatWithnoutNo ratings yet
- Chi-Square Test of IndependenceDocument6 pagesChi-Square Test of IndependenceJhoanie Marie CauanNo ratings yet
- Kolesterol (Kat) X Usia, Imt, LP, RLPTB (Numerik) T-Test: Group StatisticsDocument2 pagesKolesterol (Kat) X Usia, Imt, LP, RLPTB (Numerik) T-Test: Group StatisticsFrancisca NovelianiNo ratings yet
- Bio-Stat Class 2 and 3Document58 pagesBio-Stat Class 2 and 3Poonam RanaNo ratings yet
- 10.1 Data Analysis and InterpretationDocument23 pages10.1 Data Analysis and InterpretationmarwaNo ratings yet
- 1 Tail & 2 Tail TestDocument3 pages1 Tail & 2 Tail TestNisha AggarwalNo ratings yet
- Lecture 13Document53 pagesLecture 13Tú UyênNo ratings yet
- HypermarketDocument6 pagesHypermarketfatin hidayahNo ratings yet
- Real Statistics Examples Regression 2Document377 pagesReal Statistics Examples Regression 2Dwicahyo WNo ratings yet
- Eva OutputDocument24 pagesEva OutputEva tri kurnia santiNo ratings yet
- STATA Codes - BasicDocument8 pagesSTATA Codes - Basic蕭得軒No ratings yet
- Descriptives (A) Statistic 4.60 Lower Bound Upper BoundDocument8 pagesDescriptives (A) Statistic 4.60 Lower Bound Upper BoundJoevet T. TadlasNo ratings yet
- Categorical Data AnalysisDocument20 pagesCategorical Data AnalysisWanChainkeinNo ratings yet
- T-Test Formula Excel TemplateDocument3 pagesT-Test Formula Excel TemplateIQup AchieversNo ratings yet
- Itae 002 Test 1 2Document5 pagesItae 002 Test 1 2Nageshwar SinghNo ratings yet
- Re - ST - Hausman and Xthausman After Panel Fe, Re PDFDocument6 pagesRe - ST - Hausman and Xthausman After Panel Fe, Re PDFKhoiru RusydiNo ratings yet
- Assignment 3Document31 pagesAssignment 3Daniel CryerNo ratings yet
- GraphPad Ebook - Essential Dos Don'TsDocument10 pagesGraphPad Ebook - Essential Dos Don'TsNikunj MittalNo ratings yet