Download as docx, pdf, or txt
You might also like
- Full Download Introduction To Psychology 11th Edition Kalat Test BankDocument35 pagesFull Download Introduction To Psychology 11th Edition Kalat Test Bankcku4lcarter100% (33)
- Principles of Management MN4062QA Assessment 2021-22: Portfolio Part ADocument4 pagesPrinciples of Management MN4062QA Assessment 2021-22: Portfolio Part Ageofrey0% (1)
- Midterm 1a SolutionsDocument9 pagesMidterm 1a Solutionskyle.krist13No ratings yet
- (6 Marks) : Test Business Analytics (MGT 555) Answer Scheme A) Briefly Explain About Three (3) Measures of DispersionDocument4 pages(6 Marks) : Test Business Analytics (MGT 555) Answer Scheme A) Briefly Explain About Three (3) Measures of Dispersionazlin natasya100% (3)
- Case Study FinalDocument7 pagesCase Study FinalCyrille Malinao Esperanza100% (1)
- Full Name of submitter: Cao Thị Minh Anh Student ID: IELSIU18002Document7 pagesFull Name of submitter: Cao Thị Minh Anh Student ID: IELSIU18002ManhNo ratings yet
- Chapter 1 To Chapter 2 Stat 222Document21 pagesChapter 1 To Chapter 2 Stat 222Edgar MagturoNo ratings yet
- SAGE Quantitative Research MethodsDocument4 pagesSAGE Quantitative Research MethodsAdolfo FlorianNo ratings yet
- Binomial Distribution: Presented byDocument39 pagesBinomial Distribution: Presented bygeofreyNo ratings yet
- Applied Statistical Methodology For Research BusinessDocument12 pagesApplied Statistical Methodology For Research BusinessgeofreyNo ratings yet
- Applied Statistical Methodology For Research BusinessDocument11 pagesApplied Statistical Methodology For Research BusinessBrian JerryNo ratings yet
- Applied Statistical Methodology For Research BusinessDocument12 pagesApplied Statistical Methodology For Research BusinessgeofreyNo ratings yet
- Testing of The Hypothesis Using Binomial Distribution For Both Non-Directional and Directional CasesDocument4 pagesTesting of The Hypothesis Using Binomial Distribution For Both Non-Directional and Directional CasesgeofreyNo ratings yet
- Process Control Concepts Through Statistics: N X N X X X X XDocument14 pagesProcess Control Concepts Through Statistics: N X N X X X X XVeeresha YrNo ratings yet
- PSet1 - Solnb SolutiondDocument10 pagesPSet1 - Solnb Solutiondtest435345345No ratings yet
- Statistical Concepts BasicsDocument17 pagesStatistical Concepts BasicsVeeresha YrNo ratings yet
- Student's T TestDocument7 pagesStudent's T TestLedesma Ray100% (1)
- Statistical Methods in Quality ManagementDocument71 pagesStatistical Methods in Quality ManagementKurtNo ratings yet
- Lecture TQMDocument43 pagesLecture TQMkkarthik101No ratings yet
- Statistical Methods in Quality ManagementDocument71 pagesStatistical Methods in Quality ManagementKurtNo ratings yet
- ML 15 09 2022Document22 pagesML 15 09 2022saibaba8998No ratings yet
- Faqs Sta301 by Naveedabbas17Document77 pagesFaqs Sta301 by Naveedabbas17Malik Imran100% (1)
- Big Data Analytics Statistical MethodsDocument8 pagesBig Data Analytics Statistical MethodsA47Sahil RahateNo ratings yet
- Sample Answers: Economics 140: MIDTERM #1 (Exam Code "A")Document4 pagesSample Answers: Economics 140: MIDTERM #1 (Exam Code "A")Scribd UserNo ratings yet
- Chi Square TestDocument13 pagesChi Square TestatheebanNo ratings yet
- Pattern Basics and Related OperationsDocument21 pagesPattern Basics and Related OperationsSri VatsaanNo ratings yet
- STAT1301 Notes: Steps For Scientific StudyDocument31 pagesSTAT1301 Notes: Steps For Scientific StudyjohnNo ratings yet
- 12jane Chi-Square FinalA4Document10 pages12jane Chi-Square FinalA4kirslee6No ratings yet
- STA301 - Final Term Solved Subjective With Reference by MoaazDocument28 pagesSTA301 - Final Term Solved Subjective With Reference by MoaazAdnan Khawaja61% (18)
- STAT2120: Categorical Data Analysis Chapter 1: IntroductionDocument51 pagesSTAT2120: Categorical Data Analysis Chapter 1: IntroductionRicardo TavaresNo ratings yet
- MAE 300 TextbookDocument95 pagesMAE 300 Textbookmgerges15No ratings yet
- Inferential Statistics For Print Part IDocument23 pagesInferential Statistics For Print Part IAgazziNo ratings yet
- SBR Tutorial 4 - Solution - UpdatedDocument4 pagesSBR Tutorial 4 - Solution - UpdatedZoloft Zithromax ProzacNo ratings yet
- Wilcoxon Sign TestDocument23 pagesWilcoxon Sign TestCalculus Chong Wei ChoonNo ratings yet
- MS 08 - Solved AssignmentDocument13 pagesMS 08 - Solved AssignmentAdarsh Kalhia100% (1)
- Isom 2500Document58 pagesIsom 2500JessicaLiNo ratings yet
- Solutions Exercises Chapter 6 Exercise 1: Asymptotic Significance (2-Sided) "Document5 pagesSolutions Exercises Chapter 6 Exercise 1: Asymptotic Significance (2-Sided) "DanyValentinNo ratings yet
- Review 1 SolutionsDocument2 pagesReview 1 SolutionsNgọc Anh Bảo PhướcNo ratings yet
- Random VariablesDocument68 pagesRandom VariablesSree Lakshmi DeeviNo ratings yet
- File004 Hatfield Sample Final DiscussionDocument16 pagesFile004 Hatfield Sample Final DiscussionCameron ShoaeeNo ratings yet
- Jan S Dy 4Document26 pagesJan S Dy 4Hassan SaadNo ratings yet
- บทความภาษาอังกฤษDocument9 pagesบทความภาษาอังกฤษTANAWAT SUKKHAONo ratings yet
- 807 2readyDocument15 pages807 2readysalarNo ratings yet
- CS 229 Spring 2016 Problem Set #3: Theory & Unsupervised LearningDocument5 pagesCS 229 Spring 2016 Problem Set #3: Theory & Unsupervised LearningAchuthan SekarNo ratings yet
- ML Test2 2021 SAN - Set 3 SchemeDocument4 pagesML Test2 2021 SAN - Set 3 Schemechirag suresh chiruNo ratings yet
- 10) ISM-Session 10Document61 pages10) ISM-Session 10Rishabh GautamNo ratings yet
- StatestsDocument20 pagesStatestskebakaone marumoNo ratings yet
- Section - 1 ' Objective Type Questions: Q. (1) - Choose The Correct OptionsDocument30 pagesSection - 1 ' Objective Type Questions: Q. (1) - Choose The Correct OptionsSamrat PandeyNo ratings yet
- Getting To Know Your Data: 2.1 ExercisesDocument8 pagesGetting To Know Your Data: 2.1 Exercisesbilkeralle100% (1)
- Question 4 (A) What Are The Stochastic Assumption of The Ordinary Least Squares? Assumption 1Document9 pagesQuestion 4 (A) What Are The Stochastic Assumption of The Ordinary Least Squares? Assumption 1yaqoob008No ratings yet
- AIMDocument8 pagesAIMSaqib AliNo ratings yet
- Econometricstutorials Exam QuestionsSelectedAnswersDocument11 pagesEconometricstutorials Exam QuestionsSelectedAnswersFiliz Ertekin100% (1)
- BSA - PUT - SEM I - 21-22 SolutionDocument16 pagesBSA - PUT - SEM I - 21-22 SolutionRizwan SaifiNo ratings yet
- Problem Set 2 Quantitative Methods UNIGEDocument10 pagesProblem Set 2 Quantitative Methods UNIGEsancallonandez.95No ratings yet
- Random Variable & Probability DistributionDocument48 pagesRandom Variable & Probability DistributionRISHAB NANGIANo ratings yet
- Statistical Inference FrequentistDocument25 pagesStatistical Inference FrequentistAnkita GhoshNo ratings yet
- Ho ChisqDocument5 pagesHo ChisqchikkuNo ratings yet
- The Chi Square StatisticDocument7 pagesThe Chi Square StatisticC Athithya AshwinNo ratings yet
- Establishing Te Lesson 6Document36 pagesEstablishing Te Lesson 6SARAH JANE CAPSANo ratings yet
- Sampling Distribution Assignment HelpDocument9 pagesSampling Distribution Assignment HelpStatistics Homework SolverNo ratings yet
- Supplement To Chapter 2 - Probability and StatisticsDocument34 pagesSupplement To Chapter 2 - Probability and StatisticstemedebereNo ratings yet
- Lesson 3 - T-Distribution (Module)Document26 pagesLesson 3 - T-Distribution (Module)charmaine marasigan100% (1)
- Bupa Arabia Health Insurance Company Vs Enaya Health Insurance CompanyDocument7 pagesBupa Arabia Health Insurance Company Vs Enaya Health Insurance CompanygeofreyNo ratings yet
- UntitledDocument1 pageUntitledgeofreyNo ratings yet
- Applied Statistical Methodology For Research BusinessDocument12 pagesApplied Statistical Methodology For Research BusinessgeofreyNo ratings yet
- UntitledDocument1 pageUntitledgeofreyNo ratings yet
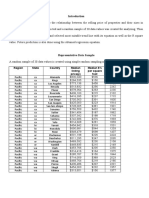
- Region State Country Median Listing Price (Y) Median $'s Per Square Foot Median Square Feet (X)Document4 pagesRegion State Country Median Listing Price (Y) Median $'s Per Square Foot Median Square Feet (X)geofreyNo ratings yet
- Running Head: Blue Ocean Strategy Report 1Document6 pagesRunning Head: Blue Ocean Strategy Report 1geofreyNo ratings yet
- Real Estate County Data For 2019 2019 Data (N 1000) : Region State County Listing Price Square Feet $'s Per Square FootDocument9 pagesReal Estate County Data For 2019 2019 Data (N 1000) : Region State County Listing Price Square Feet $'s Per Square FootgeofreyNo ratings yet
- Four Quest I Onsofequalval Uet Oanswer .: Page1of1Document13 pagesFour Quest I Onsofequalval Uet Oanswer .: Page1of1geofreyNo ratings yet
- One of The Most Serious Competitive Challenges Hain Celestial Will Face in The Next Ten Years Is That New Competitive Companies Will Enter The MarketDocument1 pageOne of The Most Serious Competitive Challenges Hain Celestial Will Face in The Next Ten Years Is That New Competitive Companies Will Enter The MarketgeofreyNo ratings yet
- Running Head: SHARED CARE PLANS 1Document11 pagesRunning Head: SHARED CARE PLANS 1geofreyNo ratings yet
- BUSN3910 Assignment 3 BriefingDocument6 pagesBUSN3910 Assignment 3 BriefinggeofreyNo ratings yet
- Law of DemandDocument5 pagesLaw of DemandgeofreyNo ratings yet
- Answer 1Document15 pagesAnswer 1geofreyNo ratings yet
- Section A Q1) A) : Particulars Amount Total Revenue 190,000,000 ExpensesDocument7 pagesSection A Q1) A) : Particulars Amount Total Revenue 190,000,000 ExpensesgeofreyNo ratings yet
- Employee Attrition Analysis Report: Student Name Course Institution Affiliation Professor DateDocument13 pagesEmployee Attrition Analysis Report: Student Name Course Institution Affiliation Professor DategeofreyNo ratings yet
- UntitledDocument9 pagesUntitledgeofreyNo ratings yet
- Real Estate County Data For 2019 2019 County Data (N 978) : County Level Measures Are Based On AveragesDocument37 pagesReal Estate County Data For 2019 2019 County Data (N 978) : County Level Measures Are Based On AveragesgeofreyNo ratings yet
- Binomial Distribution: Presented byDocument39 pagesBinomial Distribution: Presented bygeofreyNo ratings yet
- Outline Topic: Employee Attrition Analysis Report Thesis: This Essay Analyzes The Various Reasons For Attrition in A Company That Wishes To MergeDocument2 pagesOutline Topic: Employee Attrition Analysis Report Thesis: This Essay Analyzes The Various Reasons For Attrition in A Company That Wishes To MergegeofreyNo ratings yet
- Running Head: RISK ASSESSMENT 1Document7 pagesRunning Head: RISK ASSESSMENT 1geofreyNo ratings yet
- Asdfgh: by Yyyyy Uuuuip (Document7 pagesAsdfgh: by Yyyyy Uuuuip (geofreyNo ratings yet
- Answer 1Document2 pagesAnswer 1geofreyNo ratings yet
- The Blue Ocean StrategyDocument12 pagesThe Blue Ocean StrategygeofreyNo ratings yet
- UntitledDocument7 pagesUntitledgeofreyNo ratings yet
- Task Two Institutional Affiliation Students Name DateDocument5 pagesTask Two Institutional Affiliation Students Name DategeofreyNo ratings yet
- UntitledDocument2 pagesUntitledgeofreyNo ratings yet
- Case Study-Hain Celestial: Student Name Institution Affiliation DateDocument5 pagesCase Study-Hain Celestial: Student Name Institution Affiliation DategeofreyNo ratings yet
- In-Depth Market Research On D.M. Pan National Real Estate Company's Listing Prices and Square FootageDocument6 pagesIn-Depth Market Research On D.M. Pan National Real Estate Company's Listing Prices and Square FootagegeofreyNo ratings yet
- Applied Statistical Methodology For Research BusinessDocument12 pagesApplied Statistical Methodology For Research BusinessgeofreyNo ratings yet
- Chapter 2Document13 pagesChapter 2Naqeeb KhanNo ratings yet
- The Sports Review Journal SampleDocument12 pagesThe Sports Review Journal SampleJoshuaNo ratings yet
- Writing Capstone Research Project For Senior High School A Modified Guide ManualDocument9 pagesWriting Capstone Research Project For Senior High School A Modified Guide ManualIOER International Multidisciplinary Research Journal ( IIMRJ)No ratings yet
- Managing Expats and Their Effectiveness: A Comparative StudyDocument21 pagesManaging Expats and Their Effectiveness: A Comparative StudyWahib LahnitiNo ratings yet
- Hypothesis TestingDocument51 pagesHypothesis TestingwedjefdbenmcveNo ratings yet
- WEEK 7 - Two Sample Mean TestDocument26 pagesWEEK 7 - Two Sample Mean TestMeagan SheenNo ratings yet
- SB Test Bank Chapter 9Document46 pagesSB Test Bank Chapter 9Linh KhánhNo ratings yet
- A Study On Job Satisfaction Among The Employees in Sri Matha Spinning Mills Private Limited, DindigulDocument22 pagesA Study On Job Satisfaction Among The Employees in Sri Matha Spinning Mills Private Limited, DindigulJoseph RajNo ratings yet
- A Critical Analysis of The Influence of Start-Up Factors in Small Businesses and Entrepreneurial Ventures in South AfricaDocument12 pagesA Critical Analysis of The Influence of Start-Up Factors in Small Businesses and Entrepreneurial Ventures in South AfricaalidarlooNo ratings yet
- Group 9 Final ManuscriptDocument24 pagesGroup 9 Final ManuscriptMary Alwina TabasaNo ratings yet
- Impact of Mobile Phone Usage On AcademicDocument11 pagesImpact of Mobile Phone Usage On AcademicLorrein PeraltaNo ratings yet
- Writing Your Research Hypothesis: LessonDocument14 pagesWriting Your Research Hypothesis: LessonGodwill Oliva100% (1)
- 75 - Physics 2nd Year PDFDocument11 pages75 - Physics 2nd Year PDFMahmud Rahman BizoyNo ratings yet
- Two Sample Z Two TailedtemplateDocument4 pagesTwo Sample Z Two Tailedtemplatevirendra navadiyaNo ratings yet
- AS Extended Buisnesss ReportDocument25 pagesAS Extended Buisnesss ReportROHINI ROKDENo ratings yet
- Practice Exam1 2021Document9 pagesPractice Exam1 2021silNo ratings yet
- 2020-3-Pen-Jit SinDocument3 pages2020-3-Pen-Jit SinKeertana SubramaniamNo ratings yet
- T-Test For Two Independent SamplesDocument44 pagesT-Test For Two Independent SamplesFlourlyn Garcia SottoNo ratings yet
- Estimation and Hypothesis Testing: Two Populations: Prem Mann, Introductory Statistics, 7/EDocument131 pagesEstimation and Hypothesis Testing: Two Populations: Prem Mann, Introductory Statistics, 7/EMajhar Hossain ShafatNo ratings yet
- Research Methodology (Syllabus & Question Papers) PDFDocument10 pagesResearch Methodology (Syllabus & Question Papers) PDFkarthiNo ratings yet
- Stat 8Document48 pagesStat 8dinda dwicahyariniNo ratings yet
- Accounting Information: Business Scale, Msme Business Age and Owner Education LevelDocument7 pagesAccounting Information: Business Scale, Msme Business Age and Owner Education LevelThe IjbmtNo ratings yet
- HR Analytics-: Data & Analysis StrategiesDocument27 pagesHR Analytics-: Data & Analysis StrategiesArchito GoswamiNo ratings yet
- Lecture 10 Inference About Means and Proportions With Two Populations - ExercisesDocument56 pagesLecture 10 Inference About Means and Proportions With Two Populations - ExercisesYihao Quan0% (1)
- Profitability Analysis of Select Automobile Companies in India - With Special Reference To Tata Motors and Mahindra and MahindraDocument9 pagesProfitability Analysis of Select Automobile Companies in India - With Special Reference To Tata Motors and Mahindra and MahindraKshama KadwadNo ratings yet
- The T-Value For A One-Tailed Test With 1% Significance Level and 18 Degrees of Freedom Is 2.878. According To The T Value TableDocument3 pagesThe T-Value For A One-Tailed Test With 1% Significance Level and 18 Degrees of Freedom Is 2.878. According To The T Value TableRichmond BaculinaoNo ratings yet
- 4310 Exam 2Document11 pages4310 Exam 2Hung PhanNo ratings yet