Download as pdf or txt
You might also like
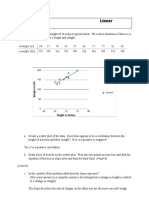
- Linear Regression LabDocument6 pagesLinear Regression Labapi-356010793100% (2)
- PROJECT 1 STA 108 BaruDocument28 pagesPROJECT 1 STA 108 Baruwani75% (8)
- Managing Quality (1) PPT SlidesDocument69 pagesManaging Quality (1) PPT Slidesdiana valdezNo ratings yet
- DocDocument4 pagesDoc42 Shanmugapriyaa DNo ratings yet
- Decision Science NotesDocument11 pagesDecision Science NotesMrugendraNo ratings yet
- Divorce Prediction System: Devansh Kapoor 179202050Document12 pagesDivorce Prediction System: Devansh Kapoor 179202050AmanNo ratings yet
- Syllabus of Machine LearningDocument19 pagesSyllabus of Machine Learninggauri krishnamoorthyNo ratings yet
- Konsep EnsembleDocument52 pagesKonsep Ensemblehary170893No ratings yet
- Decision TreeDocument57 pagesDecision TreeArjun KhoslaNo ratings yet
- Decision Tree and Sensitivity AnalysisDocument18 pagesDecision Tree and Sensitivity AnalysisAnonymous Gn9MI0VNo ratings yet
- 3.popular Machine Learning AlgorithmDocument11 pages3.popular Machine Learning AlgorithmMuhammad ShoaibNo ratings yet
- Data Analytics - Unit-IVDocument21 pagesData Analytics - Unit-IVbhavya.shivani1473No ratings yet
- Operational Research NotesDocument16 pagesOperational Research NotesVansh SharmaNo ratings yet
- TestDocument1 pageTestVivek Kumar RuhilNo ratings yet
- Agglomerative Is A Bottom-Up Technique, But Divisive Is A Top-Down TechniqueDocument8 pagesAgglomerative Is A Bottom-Up Technique, But Divisive Is A Top-Down Techniquetirth patelNo ratings yet
- Lecture-I-Mathematical ModelingDocument5 pagesLecture-I-Mathematical Modelingmumtaz aliNo ratings yet
- Decision TreeDocument57 pagesDecision TreePrabhjit Singh100% (1)
- Data Minning Unit 2-1Document10 pagesData Minning Unit 2-1yadavchilkiNo ratings yet
- Decision Science 1Document14 pagesDecision Science 1Abhishek sharmaNo ratings yet
- Interval. For Example, A Decision On Whether To Make or Buy A Product Is Static in Nature (See The Web ChapterDocument6 pagesInterval. For Example, A Decision On Whether To Make or Buy A Product Is Static in Nature (See The Web ChapterShubham MishraNo ratings yet
- A Review On Multi-Criteria Decision Making Methods For Cloud Service RankingDocument3 pagesA Review On Multi-Criteria Decision Making Methods For Cloud Service Rankingdileepvk1978No ratings yet
- CodesDocument3 pagesCodesRITESH TRIPATHINo ratings yet
- Data MiningDocument18 pagesData MiningNelson RajaNo ratings yet
- Analysis, and Result InterpretationDocument6 pagesAnalysis, and Result InterpretationDainikMitraNo ratings yet
- Lecture Note 5Document7 pagesLecture Note 5vivek guptaNo ratings yet
- 8614 (1) - 1Document17 pages8614 (1) - 1Saqib KhalidNo ratings yet
- Group7 - Decision Tree AnalysisDocument8 pagesGroup7 - Decision Tree Analysisshubham sainiNo ratings yet
- Solved With ChatGPTDocument3 pagesSolved With ChatGPTMd. Mahbubur RahmanNo ratings yet
- Managerial Computer LabDocument14 pagesManagerial Computer Labvikas jaimanNo ratings yet
- Kernels, Model Selection and Feature SelectionDocument5 pagesKernels, Model Selection and Feature SelectionGautam VashishtNo ratings yet
- Basic Sens Analysis Review PDFDocument26 pagesBasic Sens Analysis Review PDFPratik D UpadhyayNo ratings yet
- ISIMDocument14 pagesISIMFibonnaci BacktrackNo ratings yet
- COMP1801 - Copy 1Document18 pagesCOMP1801 - Copy 1SujiKrishnanNo ratings yet
- Decision Tree RDocument5 pagesDecision Tree RDivya BNo ratings yet
- Three-Way Decisions For Handling Uncertainty in Machine Learning A Narrative ReviewDocument16 pagesThree-Way Decisions For Handling Uncertainty in Machine Learning A Narrative ReviewAnwar ShahNo ratings yet
- Implementation of Differential Evolutionary Algorithm For Different ApproachesDocument6 pagesImplementation of Differential Evolutionary Algorithm For Different ApproachesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- OT Model Question AnswersDocument4 pagesOT Model Question Answersroushan0324No ratings yet
- Set-01.DT & Random ForestDocument28 pagesSet-01.DT & Random ForestRafi AhmedNo ratings yet
- A Review of Supervised Learning Based Classification For Text To Speech SystemDocument8 pagesA Review of Supervised Learning Based Classification For Text To Speech SystemInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- TrainmaterialDocument33 pagesTrainmaterialHarshit PandayNo ratings yet
- Refection Paper 3 - Management ScienceDocument3 pagesRefection Paper 3 - Management ScienceAnne Anne Cabeltis-MañaboNo ratings yet
- Multidimensional Scaling: Multidimensional Scaling (MDS) Is A Set of RelatedDocument16 pagesMultidimensional Scaling: Multidimensional Scaling (MDS) Is A Set of RelatedJatinder SainiNo ratings yet
- Expected Monetary Value (EMV) Calculation StepsDocument4 pagesExpected Monetary Value (EMV) Calculation StepsApurva JawadeNo ratings yet
- Perception Mapping: Purchase Behaviour of Mobile Phones: Gagandeep Singh Sudhanshu ShekharDocument28 pagesPerception Mapping: Purchase Behaviour of Mobile Phones: Gagandeep Singh Sudhanshu ShekharSyed Muhammad DaniyalNo ratings yet
- Unit V - Big Data ProgrammingDocument22 pagesUnit V - Big Data ProgrammingjasmineNo ratings yet
- Cosc2753 A1 MCDocument8 pagesCosc2753 A1 MCHuy NguyenNo ratings yet
- 5 Review PaperDocument7 pages5 Review PaperGorishsharmaNo ratings yet
- Machine Learning For BeginnersDocument30 pagesMachine Learning For BeginnersVansh Jatana100% (1)
- Discovering Knowledge in Data: Lecture Review ofDocument20 pagesDiscovering Knowledge in Data: Lecture Review ofmofoelNo ratings yet
- MC LearningDocument4 pagesMC LearningswapnilNo ratings yet
- Decision TreesDocument5 pagesDecision TreesUchennaNo ratings yet
- Machine Learning NotesDocument112 pagesMachine Learning Notesmubin.pathan765No ratings yet
- Decision Theory (Or-Assignment)Document3 pagesDecision Theory (Or-Assignment)Saurabh Nlyk100% (1)
- Dimensionality Reduction-PCA FA LDADocument12 pagesDimensionality Reduction-PCA FA LDAJavada JavadaNo ratings yet
- All NotesDocument6 pagesAll Notestiajung humtsoeNo ratings yet
- Batch 17 - Semester 3 Question Bank Big Data & Business AnalyticsDocument25 pagesBatch 17 - Semester 3 Question Bank Big Data & Business AnalyticsAnn Amitha AntonyNo ratings yet
- Discretization Techniques A Recent SurveyDocument12 pagesDiscretization Techniques A Recent SurveytiaNo ratings yet
- Unit 2Document11 pagesUnit 2hollowpurple156No ratings yet
- A Survey On Feature Ranking by Means of Evolutionary ComputationDocument6 pagesA Survey On Feature Ranking by Means of Evolutionary ComputationRuxandra StoeanNo ratings yet
- Ôn Thi KTDLDocument18 pagesÔn Thi KTDL20521292No ratings yet
- DA (All CHP.)Document14 pagesDA (All CHP.)Sushant ThiteNo ratings yet
- What Is Data?Document8 pagesWhat Is Data?RITESH TRIPATHINo ratings yet
- Assignment 1 Tps551Document12 pagesAssignment 1 Tps551halifeanrentapNo ratings yet
- Housing SlidesDocument8 pagesHousing SlideshalifeanrentapNo ratings yet
- Halifean Rentap 2020836444 Mind MappingDocument1 pageHalifean Rentap 2020836444 Mind MappinghalifeanrentapNo ratings yet
- Halifean Rentap 2020836444 Tutorial 2Document9 pagesHalifean Rentap 2020836444 Tutorial 2halifeanrentapNo ratings yet
- Halifean Rentap - 2020836444 - Toturial 3 (A) - (B)Document4 pagesHalifean Rentap - 2020836444 - Toturial 3 (A) - (B)halifeanrentapNo ratings yet
- Halifean Rentap - 2020836444Document3 pagesHalifean Rentap - 2020836444halifeanrentapNo ratings yet
- Spss 23 P 3Document21 pagesSpss 23 P 3Sajid AhmadNo ratings yet
- Descriptive Statistics: Tabular and Graphical MethodsDocument34 pagesDescriptive Statistics: Tabular and Graphical MethodsAudrey BienNo ratings yet
- SPSSTutorial Math CrackerDocument43 pagesSPSSTutorial Math CrackerKami4038No ratings yet
- Dela Pena-Act102-K7 Ass4Document12 pagesDela Pena-Act102-K7 Ass4Danielle Nicole Crisostomo BrocoyNo ratings yet
- Year 13 S2 ProjectDocument9 pagesYear 13 S2 Projectnew yearNo ratings yet
- Mis 121620003Document39 pagesMis 121620003Gaurav PawarNo ratings yet
- R-Cheatsheet: Help Numerical Summaries Linear RegressionDocument2 pagesR-Cheatsheet: Help Numerical Summaries Linear RegressionSieben DoppeltNo ratings yet
- 1.a. Descriptive Statistics (Part A)Document86 pages1.a. Descriptive Statistics (Part A)Debleena MitraNo ratings yet
- NEW Lesson 3 in ST 2, Economics of Agriculture, December 25, 2023Document249 pagesNEW Lesson 3 in ST 2, Economics of Agriculture, December 25, 2023beberliepangandoyonNo ratings yet
- JMPDocument45 pagesJMPmoilo8602No ratings yet
- QMB SolutionsDocument180 pagesQMB SolutionsPierre Rodriguez0% (1)
- SigmaPlot 2001 User's GuideDocument522 pagesSigmaPlot 2001 User's Guiderahmatnba100% (1)
- An IBM SPSS® Companion To Political Analysis - Philip H. H. Pollock IIIDocument319 pagesAn IBM SPSS® Companion To Political Analysis - Philip H. H. Pollock IIIPatricio CamejoNo ratings yet
- Chapter 2: Descriptive Statistics: Tabular and Graphical MethodsDocument7 pagesChapter 2: Descriptive Statistics: Tabular and Graphical Methodscik sitiNo ratings yet
- Statistic Notes For Third Year B.Com.Document3 pagesStatistic Notes For Third Year B.Com.Vicky GadhiaNo ratings yet
- Bivariate Visualizations: Alex ScrivenDocument45 pagesBivariate Visualizations: Alex ScrivenNikol CotrinaNo ratings yet
- A Scatter PlotDocument5 pagesA Scatter PlotsrinivasurajNo ratings yet
- 7 QC ToolsDocument81 pages7 QC ToolsDonny Agus PrasetyoNo ratings yet
- FIN 612 Notes PDFDocument34 pagesFIN 612 Notes PDFIvy Bucks WanjikuNo ratings yet
- Core Data Analysis Worksheet 7 Ex3.2Document10 pagesCore Data Analysis Worksheet 7 Ex3.2chris brownNo ratings yet
- Unit 9 Test Review KEY-1Document12 pagesUnit 9 Test Review KEY-1aaronjdavis0510No ratings yet
- Chapter 1 PDFDocument32 pagesChapter 1 PDFCharleneKronstedtNo ratings yet
- Dimas Eko P - 5019Document13 pagesDimas Eko P - 5019Dimas Eko PrasetyoNo ratings yet
- ECO 391-007 Lecture Handout For Chapter 15 SPRING 2003 Regression Analysis Sections 15.1, 15.2Document22 pagesECO 391-007 Lecture Handout For Chapter 15 SPRING 2003 Regression Analysis Sections 15.1, 15.2Noah HNo ratings yet
- PDFDocument114 pagesPDFSmart SarimNo ratings yet
- Interview Que & AnswDocument33 pagesInterview Que & AnswRadheshyam RaiNo ratings yet
- Mathematics 12Document21 pagesMathematics 12Vanissa Bianca S. LlanosNo ratings yet