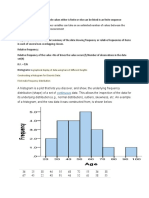
Download as docx, pdf, or txt
You might also like
- Graphical Representation of DataDocument12 pagesGraphical Representation of DataJanzen A. GabioNo ratings yet
- Graphical PresentationDocument6 pagesGraphical PresentationAtiqah RazifNo ratings yet
- VisualizationDocument27 pagesVisualizationsbapoorvaa1No ratings yet
- Types of Graphs Used in Math and StatisticsDocument14 pagesTypes of Graphs Used in Math and StatisticsElmalyn Bernarte0% (1)
- Data Visualization & Data Exploration - Unit IIDocument26 pagesData Visualization & Data Exploration - Unit IIpurusingh23No ratings yet
- Graphical PresentationDocument6 pagesGraphical PresentationHarsh ThakurNo ratings yet
- I. About Graphs: What Is A Graph?Document29 pagesI. About Graphs: What Is A Graph?Mae DinDinNo ratings yet
- Physics PresentationDocument7 pagesPhysics PresentationZuliana NurvidiatiNo ratings yet
- Case VariableDocument4 pagesCase VariableneethiNo ratings yet
- 2-3 Histograms, Frequency Polygons, and Ogives: Chp.2 Page 1Document2 pages2-3 Histograms, Frequency Polygons, and Ogives: Chp.2 Page 1Suniel ChhetriNo ratings yet
- Graphical RepresentationDocument34 pagesGraphical RepresentationYukti SharmaNo ratings yet
- Brand Loyalty: SERVICE. We HaveDocument38 pagesBrand Loyalty: SERVICE. We Havesaad farooqNo ratings yet
- Data RepresentationDocument66 pagesData RepresentationMarydelle SubitoNo ratings yet
- Project IN Math: Submitted To: Submitted byDocument8 pagesProject IN Math: Submitted To: Submitted byChrissaNo ratings yet
- 5 - Histograms, Frequency Polygons and OglivesDocument26 pages5 - Histograms, Frequency Polygons and OglivesRomell Ambal RamosNo ratings yet
- Foundation Notes 2013Document25 pagesFoundation Notes 2013Anonymous wXV066fANo ratings yet
- Plot (Graphics)Document9 pagesPlot (Graphics)amelia99No ratings yet
- Picturing Distributions With GraphsDocument21 pagesPicturing Distributions With GraphsFernan CaboteNo ratings yet
- Instru CompensateDocument41 pagesInstru CompensateSharmaine Manahan-SipinNo ratings yet
- Forms of Presentation of DataDocument29 pagesForms of Presentation of Dataton-ton elcanoNo ratings yet
- Scatter PlotDocument5 pagesScatter PlotNavdeep raoNo ratings yet
- A Relative Frequency Histogram Uses The SameDocument1 pageA Relative Frequency Histogram Uses The SameDyna BalloconNo ratings yet
- CHAPTER 2 Descriptive StatisticsDocument5 pagesCHAPTER 2 Descriptive StatisticsPark MinaNo ratings yet
- 2/ Organizing and Visualizing Variables: DcovaDocument4 pages2/ Organizing and Visualizing Variables: DcovaThong PhanNo ratings yet
- MachineryDocument9 pagesMachineryAditya KumarNo ratings yet
- How To Graph A Frequency DistributionDocument4 pagesHow To Graph A Frequency DistributionJasmin AjoNo ratings yet
- BBM AssignmentsDocument13 pagesBBM AssignmentsSky FallNo ratings yet
- Difference Between (Median, Mean, Mode, Range, Midrange) (Descriptive Statistics)Document11 pagesDifference Between (Median, Mean, Mode, Range, Midrange) (Descriptive Statistics)mahmoudNo ratings yet
- Unit 1.2Document4 pagesUnit 1.2Akash kumarNo ratings yet
- 9390 - 4301operationalisation II - Data AnalysisDocument32 pages9390 - 4301operationalisation II - Data AnalysisAmiya ArnavNo ratings yet
- Diskusi 7 BING4102Document8 pagesDiskusi 7 BING4102istiqomah100% (1)
- MathematicsDocument9 pagesMathematicsJoseph VijuNo ratings yet
- STATS Ogive DefinitionDocument6 pagesSTATS Ogive DefinitionPranav PasteNo ratings yet
- Statistics: By: ReemDocument17 pagesStatistics: By: ReemYo DeveraNo ratings yet
- San Carlos University Engineering Faculty Technical Language School Technical English 4 Eng. Carlos MuñozDocument17 pagesSan Carlos University Engineering Faculty Technical Language School Technical English 4 Eng. Carlos MuñozPablo José RosalesNo ratings yet
- DataDocument10 pagesDataAnindita GhoseNo ratings yet
- Graphical Representation of DataDocument6 pagesGraphical Representation of DataJustine Louise Bravo FerrerNo ratings yet
- 2 Presenting Data in Charts and TablesDocument35 pages2 Presenting Data in Charts and TablesAdha Estu RizqiNo ratings yet
- Chap 8 MathscapeDocument53 pagesChap 8 MathscapeHarry LiuNo ratings yet
- Dao Long Term ProjectDocument113 pagesDao Long Term ProjectRNo ratings yet
- SASADocument5 pagesSASAMichaella MaderableNo ratings yet
- Scatter PlotsDocument4 pagesScatter Plotsapi-150547803No ratings yet
- HistogramDocument3 pagesHistogramkarthikbolluNo ratings yet
- LEC-5 Probability and StatsDocument28 pagesLEC-5 Probability and StatsZepoxNo ratings yet
- Bba 104Document6 pagesBba 104shashi kumarNo ratings yet
- Stats Week 1 PDFDocument6 pagesStats Week 1 PDFAnonymous n0S2m9sR1ENo ratings yet
- Lecture 2 NotesDocument15 pagesLecture 2 NotesSerenaNo ratings yet
- Frequency Distribution ExampleDocument6 pagesFrequency Distribution ExampleMadison HartfieldNo ratings yet
- Correspondence AnalysisDocument19 pagesCorrespondence AnalysisCART11No ratings yet
- A Scatter PlotDocument5 pagesA Scatter PlotsrinivasurajNo ratings yet
- Lecture4 Mech SUDocument17 pagesLecture4 Mech SUNazeeh Abdulrhman AlbokaryNo ratings yet
- Graphs Are Picture Representatives For 1 or More Sets of Information and How These Visually Relate To One AnotherDocument3 pagesGraphs Are Picture Representatives For 1 or More Sets of Information and How These Visually Relate To One AnotherHani Delas AlasNo ratings yet
- Statistical Data Presentation ToolsDocument21 pagesStatistical Data Presentation Toolsvisual3d0% (1)
- Statistics and Probability DictionaryDocument6 pagesStatistics and Probability DictionaryJanna PiqueroNo ratings yet
- Glossary of TermsDocument7 pagesGlossary of TermsKathzkaMaeAgcaoiliNo ratings yet
- Introductory Statistics (Chapter 2)Document3 pagesIntroductory Statistics (Chapter 2)Riezel PepitoNo ratings yet
- Presentation 1Document16 pagesPresentation 1geo raganasNo ratings yet
- Introductory of Statistics - Chapter 4Document5 pagesIntroductory of Statistics - Chapter 4Riezel PepitoNo ratings yet
- Unit 2 MLDocument201 pagesUnit 2 MLShubhi SrivastavaNo ratings yet
- Trifocal Tensor: Exploring Depth, Motion, and Structure in Computer VisionFrom EverandTrifocal Tensor: Exploring Depth, Motion, and Structure in Computer VisionNo ratings yet
- Uts ReviewerDocument9 pagesUts Reviewerkevin funtallesNo ratings yet
- THESISDocument11 pagesTHESISkevin funtallesNo ratings yet
- Module For Unit 2Document32 pagesModule For Unit 2kevin funtallesNo ratings yet
- ECO Midterm ReviewerDocument15 pagesECO Midterm Reviewerkevin funtallesNo ratings yet
- STS Outline Chap.2Document6 pagesSTS Outline Chap.2kevin funtallesNo ratings yet
- UntitledDocument1 pageUntitledkevin funtallesNo ratings yet
- Entrep GroupDocument2 pagesEntrep Groupkevin funtallesNo ratings yet
- Element of Arts - : Reviewer in MapehDocument1 pageElement of Arts - : Reviewer in Mapehkevin funtallesNo ratings yet
- Badminton CourtDocument2 pagesBadminton Courtkevin funtallesNo ratings yet
- Art AppreciationDocument1 pageArt Appreciationkevin funtallesNo ratings yet
- Linear and Non Linear TextsDocument15 pagesLinear and Non Linear TextsTeacher JhenNo ratings yet
- How To Describe ChartsDocument10 pagesHow To Describe ChartsVũ TuấnNo ratings yet
- Sap Graph ABAP Reports (Programs)Document5 pagesSap Graph ABAP Reports (Programs)Max Dos AnjosNo ratings yet
- Academic Sample Writing TasksDocument10 pagesAcademic Sample Writing TasksJoshua DanielNo ratings yet
- Work and Method StudyDocument82 pagesWork and Method StudyRafiuzzama ShaikNo ratings yet
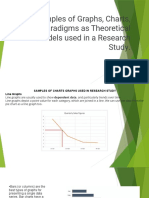
- Graphs, Charts, ParadigmDocument11 pagesGraphs, Charts, ParadigmStephanie ChuNo ratings yet
- FEB2022! Academic IELTS Writing Task 1Document19 pagesFEB2022! Academic IELTS Writing Task 1Angela BravoNo ratings yet
- 3 Working With JavaFX UI Components PDFDocument442 pages3 Working With JavaFX UI Components PDFLeon LyuNo ratings yet
- Differentiated Lesson PlanDocument2 pagesDifferentiated Lesson Planapi-209836486No ratings yet
- Exercises c2Document5 pagesExercises c2Giang NgânNo ratings yet
- Using Visual AidsDocument5 pagesUsing Visual AidsRajkumar PalmanaphanNo ratings yet
- Bahan Ajar Academic SpeakingDocument13 pagesBahan Ajar Academic SpeakingWindyNo ratings yet
- Diskusi 7 BING4102Document8 pagesDiskusi 7 BING4102istiqomah100% (1)
- How To Talk About A Visual AidDocument4 pagesHow To Talk About A Visual AidAnderNo ratings yet
- Skillsoft Course TranscriptDocument28 pagesSkillsoft Course TranscriptgreatpicNo ratings yet
- Math108x Doc omarisreportCSdocDocument4 pagesMath108x Doc omarisreportCSdocDAVID OLANo ratings yet
- Dayforce Compensation ModuleDocument102 pagesDayforce Compensation ModuleRawan AqilNo ratings yet
- LS-3-Math And-Prob Sol SkillsDocument11 pagesLS-3-Math And-Prob Sol SkillsJuvilla BatrinaNo ratings yet
- Unit 11 Market ResearchDocument10 pagesUnit 11 Market ResearchLunaNo ratings yet
- Lesson 19 - XY Plotting Using The Charting Pane - Rev BDocument18 pagesLesson 19 - XY Plotting Using The Charting Pane - Rev BManu MachadoNo ratings yet
- Kaltenbach PosterDocument1 pageKaltenbach Posterapi-248012682No ratings yet
- Session #Hsuchat: Total Tweets UsersDocument6 pagesSession #Hsuchat: Total Tweets UsersTweet BinderNo ratings yet
- Bar Graphs and Pie ChartsDocument9 pagesBar Graphs and Pie ChartsMuhammad AwaisNo ratings yet
- Handouts in Education Technology 1 Topic 6: Visuals: Real Objects Still Pictures DrawingsDocument9 pagesHandouts in Education Technology 1 Topic 6: Visuals: Real Objects Still Pictures DrawingsLouRaine TolentinoNo ratings yet
- Math 2830 Chapter 02 SlidesDocument42 pagesMath 2830 Chapter 02 SlidesChristian Rhey NebreNo ratings yet
- Epicor ERP Build An Executive Dashboard CourseDocument55 pagesEpicor ERP Build An Executive Dashboard CourseJorge Vargas100% (1)
- Crystal Reports TutorialDocument86 pagesCrystal Reports TutorialseitancalinNo ratings yet
- Manual Simul8 CompletoDocument109 pagesManual Simul8 CompletoDiana OrtegaNo ratings yet
- MadgeTech ReleaseNotesDocument9 pagesMadgeTech ReleaseNotesWANKHAMANo ratings yet
- Electronic Spreadsheet Class 9Document8 pagesElectronic Spreadsheet Class 9PREETI KAUSHIK83% (6)