Download as docx, pdf, or txt
You might also like
- Expense TrackerDocument38 pagesExpense TrackerSIDDESHWAR VASAMNo ratings yet
- FINAL YEAR PROJECT Design and Construction of IoT Power Control System With Metering For HomesDocument49 pagesFINAL YEAR PROJECT Design and Construction of IoT Power Control System With Metering For HomesDrew NyingiNo ratings yet
- Online Water Billing System DocumentationDocument87 pagesOnline Water Billing System DocumentationNesruden Abamoga100% (15)
- PIC Microcontroller Projects in C: Basic to AdvancedFrom EverandPIC Microcontroller Projects in C: Basic to AdvancedRating: 5 out of 5 stars5/5 (10)
- React Native ReportDocument65 pagesReact Native ReportFocDevsNo ratings yet
- Tutor Finder Mobile ApplicationDocument71 pagesTutor Finder Mobile ApplicationRana afaqNo ratings yet
- Blockchains: Architecture, Design and Use CasesDocument26 pagesBlockchains: Architecture, Design and Use Caseseira kNo ratings yet
- Open Source Demystified Level 1 Bachelor of Computer Applications (Bca)Document45 pagesOpen Source Demystified Level 1 Bachelor of Computer Applications (Bca)Davis ArnoldNo ratings yet
- Laboratory Component: Data Structures Laboratory (BCSL305) : Department of Computer Science and EngineeringDocument101 pagesLaboratory Component: Data Structures Laboratory (BCSL305) : Department of Computer Science and Engineeringmonishabc2No ratings yet
- Sample 2Document41 pagesSample 2dhirenraaz60No ratings yet
- Open Source Demystified Level 1Document22 pagesOpen Source Demystified Level 1Davis ArnoldNo ratings yet
- Containers Best PracticesDocument35 pagesContainers Best PracticesPrasanna9 UppuNo ratings yet
- Industrial Training Report - 21BCS11166 - MERRY - HAYONGDocument28 pagesIndustrial Training Report - 21BCS11166 - MERRY - HAYONGrobahe7624No ratings yet
- User Manual Vayu Pravah 1027Document51 pagesUser Manual Vayu Pravah 1027veenagn9No ratings yet
- Bluetooth Car Using ArduinoDocument49 pagesBluetooth Car Using ArduinoRainy ThakurNo ratings yet
- Ccaldwell Stuff Ride Final Project Report All PartsDocument50 pagesCcaldwell Stuff Ride Final Project Report All Partsapi-472231319No ratings yet
- Carter McHugh - Open Source Building Performance - Undergraduate ThesisDocument46 pagesCarter McHugh - Open Source Building Performance - Undergraduate ThesiscmchughNo ratings yet
- Nyansiongo Tea Factory System ReportDocument64 pagesNyansiongo Tea Factory System Reportnoel merengeniNo ratings yet
- 21BCS11044 - Anurag Bharti - Training ReportDocument21 pages21BCS11044 - Anurag Bharti - Training ReportAnurag BhartiNo ratings yet
- IUB Project Final ReportDocument16 pagesIUB Project Final ReportAdam adam100% (1)
- Faculty of Science: Project Title: Online Android Suggestion Box AppDocument25 pagesFaculty of Science: Project Title: Online Android Suggestion Box AppJulius nchagwaNo ratings yet
- 2022 - Identifying Trade-Offs Associated With Cross-Platform Mobile Development ToolsDocument166 pages2022 - Identifying Trade-Offs Associated With Cross-Platform Mobile Development ToolsVăn Điệp PhạmNo ratings yet
- Jonathan Hussey - 10010000 Honours Report 2014 Final ReviewedDocument128 pagesJonathan Hussey - 10010000 Honours Report 2014 Final ReviewedAlexandru IonescuNo ratings yet
- An Assessment of The Industry Foundation Classes Openbim Format For Cross-Platform Building Information Modelling Work Ows For Architectural HeritageDocument71 pagesAn Assessment of The Industry Foundation Classes Openbim Format For Cross-Platform Building Information Modelling Work Ows For Architectural HeritageJefferson Widodo100% (1)
- Software Requirements Specification For: Good2GiveDocument50 pagesSoftware Requirements Specification For: Good2GiveBilal KhanNo ratings yet
- Bubble-In Digital Testing SystemDocument85 pagesBubble-In Digital Testing SystemalhanshNo ratings yet
- Project Greg 1 1Document67 pagesProject Greg 1 1GabrielNo ratings yet
- Choosing The Right Programming Language and Hiring Top Coders For Your Next ProjectDocument17 pagesChoosing The Right Programming Language and Hiring Top Coders For Your Next ProjectI KatiaNo ratings yet
- RJ - 2023175Document100 pagesRJ - 2023175Tech FiFtyNo ratings yet
- Individual Project (ENGD3800)Document73 pagesIndividual Project (ENGD3800)Sekaram WenitonNo ratings yet
- National Institute of Transport: Project Title: Student's Name: Student's Registration NoDocument22 pagesNational Institute of Transport: Project Title: Student's Name: Student's Registration NoFelinus MtajwahaNo ratings yet
- Benson Wachira - 27327 - Assignsubmission - File - Benson Wachira - Real Estate Management ApplicationDocument61 pagesBenson Wachira - 27327 - Assignsubmission - File - Benson Wachira - Real Estate Management Applicationshital shermaleNo ratings yet
- Project Management Manual Part II RequirementsDocument120 pagesProject Management Manual Part II RequirementsKyawt Kay Khine Oo100% (1)
- HOL Computer VisionDocument81 pagesHOL Computer VisionbudisuNo ratings yet
- Kamiru - Adoption of Open Source Software by The Telecommunications Industry in KenyaDocument69 pagesKamiru - Adoption of Open Source Software by The Telecommunications Industry in KenyaJoel BiwottNo ratings yet
- Design and Implementation of A Hostel's Room Allocation SysytemDocument61 pagesDesign and Implementation of A Hostel's Room Allocation Sysytemitskenzy21No ratings yet
- Aayush ReportDocument24 pagesAayush Reportmkz01041No ratings yet
- Rubrics-4 21bca2000 SanjayDocument26 pagesRubrics-4 21bca2000 Sanjayyaduvanshiak05No ratings yet
- 4th Year Report Denis Gichana (AutoRecovered)Document67 pages4th Year Report Denis Gichana (AutoRecovered)njengadmnc111No ratings yet
- FINAL REOPRT TemplateDocument23 pagesFINAL REOPRT TemplateKainat MirNo ratings yet
- Phonebook 1 (AutoRecovered)Document19 pagesPhonebook 1 (AutoRecovered)khushboo badliNo ratings yet
- Comparison Between C# and Java: Degree ProjectDocument50 pagesComparison Between C# and Java: Degree ProjectadelomarhassanNo ratings yet
- The British College: Coursework Submission CoversheetDocument60 pagesThe British College: Coursework Submission CoversheetGarima KCNo ratings yet
- College Enquiry ChatbotDocument62 pagesCollege Enquiry Chatbotsajith alapatiNo ratings yet
- BIT ProjectDocument55 pagesBIT ProjectShenesh Dissanayaka0% (1)
- Moh Web ReportDocument36 pagesMoh Web Reportnimanshu harshNo ratings yet
- MATERIALDocument64 pagesMATERIALayaka akolo emmanuelNo ratings yet
- The Implication and Benefit of The Use of Softwares in Building ProjectDocument30 pagesThe Implication and Benefit of The Use of Softwares in Building ProjectRonnie OtienoNo ratings yet
- B Tech Project ReportDocument29 pagesB Tech Project ReportRishita ThakurNo ratings yet
- Medical Lab ProjectDocument48 pagesMedical Lab ProjectDERRICK OCHIENGNo ratings yet
- Interpreting Hand Sign Into TextDocument11 pagesInterpreting Hand Sign Into TextRoland PeruchoNo ratings yet
- Yishak MaereguDocument66 pagesYishak MaereguHebron DawitNo ratings yet
- MCA Avinash REport - 107 - MTE - ReportDocument43 pagesMCA Avinash REport - 107 - MTE - Reportfaizanrasool650No ratings yet
- Nyansiongo Tea Factory System ReportDocument64 pagesNyansiongo Tea Factory System ReportOwen Clevers50% (4)
- Software Supply Chain 2019 Report-June 22 PDFDocument57 pagesSoftware Supply Chain 2019 Report-June 22 PDFЕвгений БабичNo ratings yet
- Authorware Tutorial PDFDocument84 pagesAuthorware Tutorial PDFMannMannNo ratings yet
- 2020 07 Burg Feriani PDFDocument127 pages2020 07 Burg Feriani PDFJade TirolNo ratings yet
- Data Science Report FormatDocument16 pagesData Science Report FormatShobhit SinhaNo ratings yet
- ICP Project Development SpecificationDocument77 pagesICP Project Development SpecificationjeffmilumNo ratings yet
- Hoàng Triều Dương (BKC12322) -Assignment 1 Lần 1- SDLCDocument36 pagesHoàng Triều Dương (BKC12322) -Assignment 1 Lần 1- SDLCDương TriềuNo ratings yet
- Court MNGMNT SysDocument41 pagesCourt MNGMNT SysSandy OfficialNo ratings yet
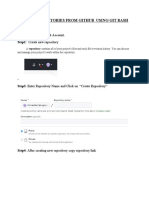
- Clone Repositories From Github Using Git Bash: Step 1:-Login To Github Account. Step2: Create New RepositoryDocument9 pagesClone Repositories From Github Using Git Bash: Step 1:-Login To Github Account. Step2: Create New RepositoryDavis ArnoldNo ratings yet
- Open Source Demystified Level 1Document22 pagesOpen Source Demystified Level 1Davis ArnoldNo ratings yet
- Open Source Demystified Level 1 Bachelor of Computer Applications (Bca)Document45 pagesOpen Source Demystified Level 1 Bachelor of Computer Applications (Bca)Davis ArnoldNo ratings yet
- SclupturesDocument2 pagesSclupturesDavis ArnoldNo ratings yet
- Documentation of D.I.Y COOKING RAJESH A (21BCAC50) H&FDocument72 pagesDocumentation of D.I.Y COOKING RAJESH A (21BCAC50) H&FDavis ArnoldNo ratings yet
- of D.I.Y COOKING 1-5 RAJESH .A (21BCAC50)Document4 pagesof D.I.Y COOKING 1-5 RAJESH .A (21BCAC50)Davis ArnoldNo ratings yet
- NarratorDocument15 pagesNarratorDavis ArnoldNo ratings yet
- OPSunit 1&2Document9 pagesOPSunit 1&2Davis ArnoldNo ratings yet
- SSRN Id4640556Document22 pagesSSRN Id4640556ypes61205No ratings yet
- Hyperledger FabricDocument383 pagesHyperledger FabricSwatee Paithankar BedreNo ratings yet
- Block Chain Fundamentals and HyperledgerDocument42 pagesBlock Chain Fundamentals and HyperledgerFatema TurnaNo ratings yet
- Construction Quality Management With BlockchainsDocument16 pagesConstruction Quality Management With BlockchainsAsfand KhalidNo ratings yet
- This Study Resource Was: CelloDocument4 pagesThis Study Resource Was: CelloVijju Battini100% (1)
- About Ibm Food Trust - 89017389USENDocument17 pagesAbout Ibm Food Trust - 89017389USENMatheus SpartalisNo ratings yet
- Beat AbftDocument14 pagesBeat AbftRoels MajorNo ratings yet
- Hyper LedgerDocument15 pagesHyper LedgervijaymspNo ratings yet
- Brochure For Online FDP On Blockchain & Its Application From 04th - 10th May, 2020 PDFDocument2 pagesBrochure For Online FDP On Blockchain & Its Application From 04th - 10th May, 2020 PDFBapon100% (1)
- Launchpad Development Services - MobiloitteDocument1 pageLaunchpad Development Services - MobiloitteMobiloitte TechnologiesNo ratings yet
- Fabric v2.4 AppDevDocument27 pagesFabric v2.4 AppDevBilgehan SavguNo ratings yet
- The Potential For Blockchain Technology in Corporate GovernanceDocument32 pagesThe Potential For Blockchain Technology in Corporate GovernanceasdNo ratings yet
- Blockchain MergedDocument71 pagesBlockchain Mergedcvam04No ratings yet
- Fusing Identity Management HL7 and Blockchain IntoDocument7 pagesFusing Identity Management HL7 and Blockchain IntomaoNo ratings yet
- Final International Trade CourseworkDocument3 pagesFinal International Trade CourseworkQuin RashellNo ratings yet
- MSC Cs Syllabus Sem-III & IV (Cbcs Revised) 2022-23Document49 pagesMSC Cs Syllabus Sem-III & IV (Cbcs Revised) 2022-23tapasya2097No ratings yet
- Understanding Blockchain Technology and How To Get Involved: July 2018Document17 pagesUnderstanding Blockchain Technology and How To Get Involved: July 2018PemetaanPendidikanNo ratings yet
- Review REMME BC Solution 022018Document42 pagesReview REMME BC Solution 022018Микола РевичNo ratings yet
- Smart Parking: Iot and Blockchain: Abdul WahabDocument83 pagesSmart Parking: Iot and Blockchain: Abdul WahabNoobstaxD AhmedNo ratings yet
- Appendix 1Document35 pagesAppendix 1Purvi SharmaNo ratings yet
- Swift Annual Review 2017Document21 pagesSwift Annual Review 2017williamhancharekNo ratings yet
- A Survey of Blockchain Applications in The FinTech SectorDocument44 pagesA Survey of Blockchain Applications in The FinTech SectorBhishek KumarNo ratings yet
- Hyperledger: Ruchita Nishad Patel Priyanshi Yash Kothari Harsh Mandaliya Nihar RavalDocument22 pagesHyperledger: Ruchita Nishad Patel Priyanshi Yash Kothari Harsh Mandaliya Nihar RavalHarsh MandaliaNo ratings yet
- Priyanka Y Resume1Document3 pagesPriyanka Y Resume1velusnNo ratings yet
- BPAS: Blockchain-Assisted Privacy-Preserving Authentication System For VehicularDocument10 pagesBPAS: Blockchain-Assisted Privacy-Preserving Authentication System For VehicularمحمدNo ratings yet
- Hyperledger Fabric Multi Host NetworkDocument13 pagesHyperledger Fabric Multi Host NetworkVjay BaskarNo ratings yet
- The Anatomy of Blockchain Database Systems Blockchain Database SystemDocument7 pagesThe Anatomy of Blockchain Database Systems Blockchain Database SystemInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Why Train With LF April 2020Document45 pagesWhy Train With LF April 2020Abhishek SinghNo ratings yet
- An Overview of Blockchain Technology Based On A Study of Public AwarenessDocument9 pagesAn Overview of Blockchain Technology Based On A Study of Public Awarenessحسان فضل الشعيبيNo ratings yet