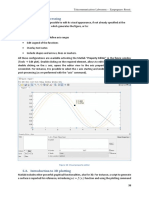
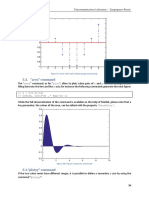
Download as pdf or txt
You might also like
- Selection of Liquid & Vapour SeparatorDocument33 pagesSelection of Liquid & Vapour SeparatorVismit BansalNo ratings yet
- Self EvaluationDocument4 pagesSelf EvaluationSonu Singh100% (2)
- Integrated Planning For Transition To Low-Carbon Distribution System With Renewable Energy Generation and Demand ResponseDocument13 pagesIntegrated Planning For Transition To Low-Carbon Distribution System With Renewable Energy Generation and Demand ResponseAnonymous ZVnJ6n5TGNo ratings yet
- An Adaptive Large Neighborhood Search Heuristic For The Pollution-Routing ProblemDocument15 pagesAn Adaptive Large Neighborhood Search Heuristic For The Pollution-Routing ProblemRUBEN ALBERTO RAMOS HUAROCNo ratings yet
- OptimizationDocument4 pagesOptimizationmariaNo ratings yet
- Real Gas Flow Simulation in Damaged Distribution PipelinesDocument8 pagesReal Gas Flow Simulation in Damaged Distribution PipelinesJorge Andrés Palacio CardonaNo ratings yet
- The Simulation of Natural Gas Gathering Pipeline NetworkDocument5 pagesThe Simulation of Natural Gas Gathering Pipeline Networkjeff_shawNo ratings yet
- Optimal Placement of Distributed Generation in Electric Distribution NetworksDocument5 pagesOptimal Placement of Distributed Generation in Electric Distribution NetworksIsaac OrtegaNo ratings yet
- A Novel Approach To Multi-Objective Efficiency Optimisation For A Distribution Transformer Based On The Taguchi MethodDocument7 pagesA Novel Approach To Multi-Objective Efficiency Optimisation For A Distribution Transformer Based On The Taguchi MethodMurat YildizNo ratings yet
- International Journal of Heat and Mass Transfer: Reza Behrou, Alberto Pizzolato, Antoni Forner-CuencaDocument21 pagesInternational Journal of Heat and Mass Transfer: Reza Behrou, Alberto Pizzolato, Antoni Forner-Cuenca5415 Karim Aly HassanNo ratings yet
- Optimization of Vapor Compression Cycle Based On Genetic AlgorithmDocument5 pagesOptimization of Vapor Compression Cycle Based On Genetic AlgorithmAshish BhardwajNo ratings yet
- Paper - Fluxograma NSGA-IIDocument14 pagesPaper - Fluxograma NSGA-IIReveloApraezCesarNo ratings yet
- Synthesis of Long-Period Fiber Gratings With A Lagrange Multiplier Optimization MethodDocument14 pagesSynthesis of Long-Period Fiber Gratings With A Lagrange Multiplier Optimization Methodmuyucel3No ratings yet
- Ordinal Optimisation Approach For Locating and Sizing of Distributed GenerationDocument11 pagesOrdinal Optimisation Approach For Locating and Sizing of Distributed GenerationAhmed WestministerNo ratings yet
- Performance of Axial Compressor StagesDocument11 pagesPerformance of Axial Compressor StagesBiswajit Jena100% (1)
- Binary PSO Based Dynamic Multi-Objective Model For DG Planning Under UncertaintyDocument12 pagesBinary PSO Based Dynamic Multi-Objective Model For DG Planning Under UncertaintyLuisa Fernanda Buitrago ArroyaveNo ratings yet
- A Hybrid Tool To Combine Multi-Objective Optimization and Multi-Criterion Decision Making inDocument14 pagesA Hybrid Tool To Combine Multi-Objective Optimization and Multi-Criterion Decision Making inhalilNo ratings yet
- A Fully Decentralized Dual Consensus Method For Carbon Trading Powerdispatch With Wind PowerDocument11 pagesA Fully Decentralized Dual Consensus Method For Carbon Trading Powerdispatch With Wind PowerOpera AndersonNo ratings yet
- Simulation Model of A Permanent Magnet Synchronous Generator For Grid StudiesDocument6 pagesSimulation Model of A Permanent Magnet Synchronous Generator For Grid StudiesRupesh Arun KumarNo ratings yet
- The Effect of Propeller Scaling Methodology On The Performance PredictionDocument17 pagesThe Effect of Propeller Scaling Methodology On The Performance PredictionHa DaNo ratings yet
- Design Applicable 3D Microfluidic Functional Units Using 2D Topology Optimization With Length Scale ConstraintsDocument14 pagesDesign Applicable 3D Microfluidic Functional Units Using 2D Topology Optimization With Length Scale ConstraintsARABONo ratings yet
- B2 2 PDFDocument4 pagesB2 2 PDFKiranNo ratings yet
- Development of An Ejector For Passive Hydrogen Recirculation in PEM Fuel Cell Systems by Applying 2D CFD SimulationDocument16 pagesDevelopment of An Ejector For Passive Hydrogen Recirculation in PEM Fuel Cell Systems by Applying 2D CFD SimulationJosé Ricardo ProchnowNo ratings yet
- Calculating Collection Efficiencies For Electrostatic PrecipitatorsDocument8 pagesCalculating Collection Efficiencies For Electrostatic Precipitatorsnum0067No ratings yet
- Distribution System Operation With Renewables and Energy Storage A Linear Programming Based Multistage Robust Feasibility ApproachDocument12 pagesDistribution System Operation With Renewables and Energy Storage A Linear Programming Based Multistage Robust Feasibility ApproachRobert PanaitNo ratings yet
- Application of Deep Artificial Neural Networks To Multi-Dimensional Flamelet Libraries and Spray FlamesDocument18 pagesApplication of Deep Artificial Neural Networks To Multi-Dimensional Flamelet Libraries and Spray FlamesMoatasim FarooqueNo ratings yet
- Soft Computing Technique Based Economic Load Dispatch Using Improved Particle Swarm OptimizationDocument7 pagesSoft Computing Technique Based Economic Load Dispatch Using Improved Particle Swarm OptimizationAditya TiwariNo ratings yet
- EGY D 23 05201 - ReviewerDocument24 pagesEGY D 23 05201 - ReviewerWEIWEI YANGNo ratings yet
- A Low Power 1-MHz Continuous-Time M Using A Passive Loop Filter Designed With A Genetic Algorithm ToolDocument4 pagesA Low Power 1-MHz Continuous-Time M Using A Passive Loop Filter Designed With A Genetic Algorithm Toolguna rajNo ratings yet
- Incorporating Direct Load Control Demand Response Into Active 2023 Applied EDocument11 pagesIncorporating Direct Load Control Demand Response Into Active 2023 Applied EIbadurrahman KahfiNo ratings yet
- Optimal Operation of PV-Battery-Diesel MicroGrid For Industrial Loads Under Grid BlackoutsDocument5 pagesOptimal Operation of PV-Battery-Diesel MicroGrid For Industrial Loads Under Grid Blackoutslaap85No ratings yet
- Solar Energy: A A A A B A A CDocument1 pageSolar Energy: A A A A B A A CAamir AmirNo ratings yet
- OPF InMulticarrier Energy SystemsDocument10 pagesOPF InMulticarrier Energy SystemsPradeep DauhareNo ratings yet
- A Multi-Objective Optimization Model For Gas Pipeline OperationsDocument34 pagesA Multi-Objective Optimization Model For Gas Pipeline OperationsMasoud NasiriNo ratings yet
- Multi-Objective Complementary Scheduling of hydro-thermal-RE Power System Via A Multi-Objective Hybrid Grey Wolf OptimizerDocument15 pagesMulti-Objective Complementary Scheduling of hydro-thermal-RE Power System Via A Multi-Objective Hybrid Grey Wolf OptimizerMir JamalNo ratings yet
- GPT Free SensitivityDocument17 pagesGPT Free SensitivityTodo VinylNo ratings yet
- Effective Method For Optimal Allocation of Distributed Generation Units in Meshed Electric Power SystemsDocument12 pagesEffective Method For Optimal Allocation of Distributed Generation Units in Meshed Electric Power SystemsAhmed WestministerNo ratings yet
- DefendDocument12 pagesDefendMAcryan Pacquiao PactolNo ratings yet
- 1 s2.0 S0378779622008550 MainDocument9 pages1 s2.0 S0378779622008550 MainROIBER VASQUEZ TAPIANo ratings yet
- AndamanDocument9 pagesAndamansnehaNo ratings yet
- Jbuckland Asme Dscoctober2008Document7 pagesJbuckland Asme Dscoctober2008José SilvaNo ratings yet
- Galluzzi Et Al. - 2018 - Optimized Design and Characterization of Motor-PumDocument12 pagesGalluzzi Et Al. - 2018 - Optimized Design and Characterization of Motor-PumSantiago Puma Puma AraujoNo ratings yet
- Reliability-Oriented Networking Planning VSC - JOURNALDocument10 pagesReliability-Oriented Networking Planning VSC - JOURNALDaniel Adolfo Medina CarvajalNo ratings yet
- Energy: Brede A.L. Hagen, Roberto Agromayor, Petter NeksåDocument17 pagesEnergy: Brede A.L. Hagen, Roberto Agromayor, Petter NeksåAhmad YaniNo ratings yet
- Energy Management of Community MicrogridDocument26 pagesEnergy Management of Community Microgrid1DS18CV060 SACHINNo ratings yet
- Revisit The Electricity Price Formulation - A Formal Definition, Proofs, and ExamplesDocument12 pagesRevisit The Electricity Price Formulation - A Formal Definition, Proofs, and ExamplesTshepang GaeatlholweNo ratings yet
- Gas Network ModelingDocument26 pagesGas Network ModelingManuel Angulo BustilloNo ratings yet
- Optimal Design of Pipe Network by An Improved Genetic AlgorithmDocument12 pagesOptimal Design of Pipe Network by An Improved Genetic AlgorithmJR GANo ratings yet
- A Tension Distribution Algorithm For Cable-Driven Parallel Robots Operating Beyond Their Wrench-Feasible WorkspaceDocument7 pagesA Tension Distribution Algorithm For Cable-Driven Parallel Robots Operating Beyond Their Wrench-Feasible WorkspaceSiddharth UNo ratings yet
- Multi Layer Testing: Theory and PracticeDocument7 pagesMulti Layer Testing: Theory and PracticeeckoNo ratings yet
- Operation of Distribution Network With Optimal Placement and Sizing of Dispatchable DGs and Shunt CapacitorsDocument12 pagesOperation of Distribution Network With Optimal Placement and Sizing of Dispatchable DGs and Shunt CapacitorsSiti Annisa SyalsabilaNo ratings yet
- A Novel Integration Technique For Optimal Network ReconfigurationDocument12 pagesA Novel Integration Technique For Optimal Network Reconfigurationmuh.salimkhamimNo ratings yet
- Distillation Pinch Point & More - Angelo LuciaDocument23 pagesDistillation Pinch Point & More - Angelo LuciaWillbrynner Pereira MarquesNo ratings yet
- Simulation of Layer Thickness PDFDocument5 pagesSimulation of Layer Thickness PDFRiazAhmadNo ratings yet
- Applied Energy: Renato Galluzzi, Yijun Xu, Nicola Amati, Andrea TonoliDocument12 pagesApplied Energy: Renato Galluzzi, Yijun Xu, Nicola Amati, Andrea TonoliLucas DuarteNo ratings yet
- Accelerating Quantum Monte Carlo Simulations of Real Materials On GPU ClustersDocument12 pagesAccelerating Quantum Monte Carlo Simulations of Real Materials On GPU ClustersAdip ChyNo ratings yet
- Journal Pre-Proof: IntegrationDocument9 pagesJournal Pre-Proof: IntegrationKarima Ben salahNo ratings yet
- 1 s2.0 S2773153722000287 MainDocument15 pages1 s2.0 S2773153722000287 MainWesley Jeevadason (RA1913005011014)No ratings yet
- An Analysis of Optimal Power Flow Based For - 2021 - International Journal of ElDocument10 pagesAn Analysis of Optimal Power Flow Based For - 2021 - International Journal of ElGcNo ratings yet
- 10 1109ceit 2016 7929049Document5 pages10 1109ceit 2016 7929049KarimNo ratings yet
- A Novel Method in Classifying and Analysing Faults in Renewable Energy Power TransformersDocument7 pagesA Novel Method in Classifying and Analysing Faults in Renewable Energy Power TransformersAlawy AbdoNo ratings yet
- Modeling and Control of Power Electronic Converters for Microgrid ApplicationsFrom EverandModeling and Control of Power Electronic Converters for Microgrid ApplicationsNo ratings yet
- p39 PDFDocument1 pagep39 PDFclaudyaneNo ratings yet
- Background On Signals and Matlab Operations: Telecommunications Laboratory - Zampognaro RosetiDocument1 pageBackground On Signals and Matlab Operations: Telecommunications Laboratory - Zampognaro RoseticlaudyaneNo ratings yet
- 2758-Article Text-4915-2-10-20220301Document7 pages2758-Article Text-4915-2-10-20220301claudyaneNo ratings yet
- Predictive Analysis of Fluid-Hammer Effect On LNG Regasification System Pipeline NetworkDocument6 pagesPredictive Analysis of Fluid-Hammer Effect On LNG Regasification System Pipeline NetworkclaudyaneNo ratings yet
- Hicss 2016Document10 pagesHicss 2016claudyaneNo ratings yet
- X (-5:.01:3) PlotDocument1 pageX (-5:.01:3) PlotclaudyaneNo ratings yet
- Artigo 2 Convexity Issues in System IdentificationDocument9 pagesArtigo 2 Convexity Issues in System IdentificationclaudyaneNo ratings yet
- 4.3. Script / Function Control FlowDocument1 page4.3. Script / Function Control FlowclaudyaneNo ratings yet
- 5.2. Plot Post-Processing: Telecommunications Laboratory - Zampognaro RosetiDocument1 page5.2. Plot Post-Processing: Telecommunications Laboratory - Zampognaro RoseticlaudyaneNo ratings yet
- 5.3. "Area" Command: Telecommunications Laboratory - Zampognaro RosetiDocument1 page5.3. "Area" Command: Telecommunications Laboratory - Zampognaro RoseticlaudyaneNo ratings yet
- Figure 8: Stem Command ExampleDocument1 pageFigure 8: Stem Command ExampleclaudyaneNo ratings yet
- 2.6.6 Packages: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.6.6 Packages: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Importing Objects From Modules Into The Main Namespace: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pageImporting Objects From Modules Into The Main Namespace: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pagePython Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.6.5 Scripts or Modules? How To Organize Your Code: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.6.5 Scripts or Modules? How To Organize Your Code: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pagePython Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pagePython Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.6.1 Scripts: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.6.1 Scripts: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.5.8 Functions Are Objects: 2.6 Reusing Code: Scripts and ModulesDocument1 page2.5.8 Functions Are Objects: 2.6 Reusing Code: Scripts and ModulesclaudyaneNo ratings yet
- 2.5.4 Passed by Value: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.5.4 Passed by Value: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.6.1 Scripts: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.6.1 Scripts: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.5.6 Variable Number of Parameters: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.5.6 Variable Number of Parameters: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.5.4 Passed by Value: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.5.4 Passed by Value: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 1.3 The Interactive Workflow: Ipython and A Text Editor: 1.3.1 Command Line InteractionDocument1 page1.3 The Interactive Workflow: Ipython and A Text Editor: 1.3.1 Command Line InteractionclaudyaneNo ratings yet
- Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pagePython Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.4.2 For/Range: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.4.2 For/Range: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pagePython Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pagePython Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Keeping Track of Enumeration Number: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pageKeeping Track of Enumeration Number: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Strings: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pageStrings: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- School Grade Level Teacher Charish Mae O. Demegillo Learning Area Quarter Date: Time: SectionsDocument4 pagesSchool Grade Level Teacher Charish Mae O. Demegillo Learning Area Quarter Date: Time: SectionsRoss AnaNo ratings yet
- Chantal Udasco)Document70 pagesChantal Udasco)yantiNo ratings yet
- Stephanieengelletrref 318Document2 pagesStephanieengelletrref 318api-394541889No ratings yet
- Noah Carr - ResumeDocument1 pageNoah Carr - Resumeapi-639527273No ratings yet
- Cambridge International Advanced Subsidiary and Advanced LevelDocument8 pagesCambridge International Advanced Subsidiary and Advanced LevelAbdulBasitBilalSheikhNo ratings yet
- Computer Algebra Systems: Permitted But Are They Used?: Robyn Pierce & Caroline BardiniDocument11 pagesComputer Algebra Systems: Permitted But Are They Used?: Robyn Pierce & Caroline Bardinizeque85No ratings yet
- Presentation of ResearchDocument59 pagesPresentation of ResearchsemerederibeNo ratings yet
- The Creative Side of Advertising and Message StrategyDocument36 pagesThe Creative Side of Advertising and Message StrategysakthivelNo ratings yet
- Evaluation of An Arabic Chatbot Based On Extractive Question-Answering Transfer Learning and Language TransformersDocument25 pagesEvaluation of An Arabic Chatbot Based On Extractive Question-Answering Transfer Learning and Language TransformersChaimaa BouafoudNo ratings yet
- Department of Theatre and Film Studies: Nnamdi Azikiwe UniversityDocument7 pagesDepartment of Theatre and Film Studies: Nnamdi Azikiwe Universityanon_453956231No ratings yet
- Ralf Hinze, Dan Marsden - Introducing String Diagrams - The Art of Category Theory-Cambridge University Press (2023)Document197 pagesRalf Hinze, Dan Marsden - Introducing String Diagrams - The Art of Category Theory-Cambridge University Press (2023)Renato SilvaNo ratings yet
- BPE 222-AquaticsDocument15 pagesBPE 222-AquaticsEric Pascual IndieNo ratings yet
- 1 Endorsement March 5, 2019: East Cabadbaran District Sanghan Elementary School School ID 131578Document2 pages1 Endorsement March 5, 2019: East Cabadbaran District Sanghan Elementary School School ID 131578lei SaguitariusNo ratings yet
- Duthmala The Morphodynamic Functioning of The Dom-Hydrotheek (Stowa) 444915Document104 pagesDuthmala The Morphodynamic Functioning of The Dom-Hydrotheek (Stowa) 444915LisaStrakhovaNo ratings yet
- Resume - Mackenzie Cullen 1Document1 pageResume - Mackenzie Cullen 1api-502329402No ratings yet
- A Clinical Supervision Model in Bachelor Nursing Education - Purpose, Content and EvaluationDocument7 pagesA Clinical Supervision Model in Bachelor Nursing Education - Purpose, Content and EvaluationDian NovitaNo ratings yet
- Candidate Basic Information SheetDocument6 pagesCandidate Basic Information Sheetdubai_santanuNo ratings yet
- January 2016 Postgraduate Application FormDocument8 pagesJanuary 2016 Postgraduate Application FormAhmad Syafi'iNo ratings yet
- Asena Safai 5F : He'S A Natural Professor Mcgonagall Seeker A Monstrous Dog With Three HeadsDocument1 pageAsena Safai 5F : He'S A Natural Professor Mcgonagall Seeker A Monstrous Dog With Three HeadsBest FriendsNo ratings yet
- Data Analytics BrouchureDocument15 pagesData Analytics BrouchureSoubhagya Kumar ParidaNo ratings yet
- Versace Tiana 18354795 Edpr3003 A2Document6 pagesVersace Tiana 18354795 Edpr3003 A2api-314238812No ratings yet
- Contoh Curriculum VitaeDocument13 pagesContoh Curriculum VitaeIdo Widya YudhatamaNo ratings yet
- CAT6A Reference GuideDocument56 pagesCAT6A Reference GuideMarcilio CarvalhoNo ratings yet
- 12 HPGD1103 T9Document13 pages12 HPGD1103 T9aton hudaNo ratings yet
- Ants Straight Line - BrucksteinDocument4 pagesAnts Straight Line - Brucksteinpzizzle1243No ratings yet
- An Introduction To MS WordDocument5 pagesAn Introduction To MS WordGLENN MENDOZANo ratings yet
- Abraham EjiguDocument86 pagesAbraham EjiguBugna werdaNo ratings yet
- PS4 Mom IiDocument1 pagePS4 Mom IiMuhammad QasimNo ratings yet