Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5824)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Designware DW - Axi - GS: DatabookDocument88 pagesDesignware DW - Axi - GS: DatabookNguyễn Sĩ Nam100% (1)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- 04 PULP ChipsDocument49 pages04 PULP ChipsNguyễn Sĩ NamNo ratings yet
- Efficient Per-Flow Queueing in DRAM at OC-192 Line Rate Using Out-of-Order Execution TechniquesDocument104 pagesEfficient Per-Flow Queueing in DRAM at OC-192 Line Rate Using Out-of-Order Execution TechniquesNguyễn Sĩ NamNo ratings yet
- Lpddr5 System TrainingDocument32 pagesLpddr5 System TrainingNguyễn Sĩ NamNo ratings yet
- Skill Language Programming: Lecture Manual July 16, 2012Document609 pagesSkill Language Programming: Lecture Manual July 16, 2012Nguyễn Sĩ NamNo ratings yet
- The How To's of Advanced Mixed-Signal VerificationDocument51 pagesThe How To's of Advanced Mixed-Signal VerificationNguyễn Sĩ NamNo ratings yet
- (Arithmetic Logic Unit Architectures With Dynamically Defined PrecisionDocument131 pages(Arithmetic Logic Unit Architectures With Dynamically Defined PrecisionNguyễn Sĩ NamNo ratings yet
- Digital Design Flow: Tutorial For EDA ToolsDocument74 pagesDigital Design Flow: Tutorial For EDA ToolsNguyễn Sĩ NamNo ratings yet
- Verilog HDL Synthesis A Practical PrimerDocument245 pagesVerilog HDL Synthesis A Practical PrimerNguyễn Sĩ NamNo ratings yet
- Ic Design FinalreportDocument151 pagesIc Design FinalreportNguyễn Sĩ NamNo ratings yet
- Computer ArichitectureDocument60 pagesComputer ArichitectureNguyễn Sĩ NamNo ratings yet
- INDEV (PC Assembly Script)Document3 pagesINDEV (PC Assembly Script)Francis Roel Laude AbarcaNo ratings yet
- History - Evolution of ComputerDocument24 pagesHistory - Evolution of ComputerAkhila DakshinaNo ratings yet
- 08u 1Document31 pages08u 1Anonymous G1iPoNOKNo ratings yet
- In GATE 2010.compressedDocument18 pagesIn GATE 2010.compressedshaharukh786No ratings yet
- Dynamic Combinational Circuits: - Dynamic Circuits - Domino Logic - np-CMOS (Zipper CMOS)Document15 pagesDynamic Combinational Circuits: - Dynamic Circuits - Domino Logic - np-CMOS (Zipper CMOS)himanshu chandrakarNo ratings yet
- ARM Processors 11Document20 pagesARM Processors 11TapasKumarDashNo ratings yet
- Microcontroller 8051 - 1Document102 pagesMicrocontroller 8051 - 1api-19646376No ratings yet
- U Supply Bench Rev BDocument1 pageU Supply Bench Rev BStoica Valentin CatalinNo ratings yet
- Verilog Tutorial 3 - Kien 082009Document16 pagesVerilog Tutorial 3 - Kien 082009Trần Ngọc LâmNo ratings yet
- TF7050-M2/TF7025-M2 Setup ManualDocument69 pagesTF7050-M2/TF7025-M2 Setup ManualCameronSSNo ratings yet
- Module 5 - Digital Techniques-Eis PDFDocument3 pagesModule 5 - Digital Techniques-Eis PDFRishi sharmaNo ratings yet
- GPIODocument13 pagesGPIOJauhar NafisNo ratings yet
- Cerobfnadfenacfecudts: Cornbfnobfonod IogicDocument17 pagesCerobfnadfenacfecudts: Cornbfnobfonod IogicReshab Kumar SharmaNo ratings yet
- V4R5 640 650 730 740 S30 S40 and SB1 Problem Analysis Repair and Parts Y4459565Document1,057 pagesV4R5 640 650 730 740 S30 S40 and SB1 Problem Analysis Repair and Parts Y4459565gmawoyoNo ratings yet
- 16x2 LCD With TIVa ManualDocument9 pages16x2 LCD With TIVa ManualPivion Healthcare50% (2)
- IBM System x3400 M3: IBM Redbooks Product GuideDocument39 pagesIBM System x3400 M3: IBM Redbooks Product GuideVat PingNo ratings yet
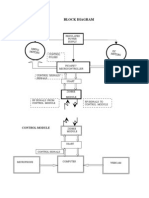
- Block Diagram: Body of RobotDocument11 pagesBlock Diagram: Body of RobotAbraham Rohith RoyNo ratings yet
- Avr 2022Document17 pagesAvr 2022Soumya Ranjan PandaNo ratings yet
- Measuring Experimental Error in Microprocessor SimulationDocument12 pagesMeasuring Experimental Error in Microprocessor SimulationblackspideymakNo ratings yet
- List of MIPS Architecture Processors - WikipediaDocument6 pagesList of MIPS Architecture Processors - WikipediaTechnical NoviceNo ratings yet
- Onetimechane TimetableDocument55 pagesOnetimechane TimetableJayadeepauyaj UppalapatiNo ratings yet
- Vector Institute Vlsi Sample PaparDocument12 pagesVector Institute Vlsi Sample Paparpvsrinivas88No ratings yet
- Chapter 13 PLC Logic and Bit Shift InstructionsDocument20 pagesChapter 13 PLC Logic and Bit Shift InstructionsReineNo ratings yet
- 74HC390 74HCT390: 1. General DescriptionDocument18 pages74HC390 74HCT390: 1. General DescriptionpaulpuscasuNo ratings yet
- 74HC14N TGSDocument4 pages74HC14N TGSLeila MoralesNo ratings yet
- Memory Expansion For Repository (Mer) : Falconstor Hardware Quickstart GuideDocument2 pagesMemory Expansion For Repository (Mer) : Falconstor Hardware Quickstart GuideAdam Van HarenNo ratings yet
- ADuC702x A DraftDocument93 pagesADuC702x A Draftmarius_haganNo ratings yet
- Asm in DeldDocument33 pagesAsm in DeldAnand GharuNo ratings yet
- K60P144M120Document94 pagesK60P144M120anandkalodeNo ratings yet
- Sm-A520f Eplis 11Document14 pagesSm-A520f Eplis 11Adan CandeasNo ratings yet