
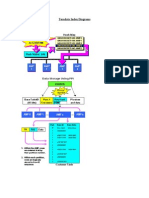
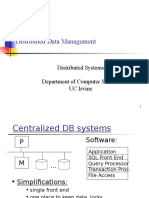
BISP Teradata Basics
BISP Teradata Basics
You might also like
- Performativity and The Image. Narrative, Representation, and The Uruk VaseDocument8 pagesPerformativity and The Image. Narrative, Representation, and The Uruk VaseMiguel Carceller SindreuNo ratings yet
- Guidelines For Writing Academic Papers at ESB 2018-09-13Document25 pagesGuidelines For Writing Academic Papers at ESB 2018-09-13SKNo ratings yet
- RPT Bi Tahun 2 SemakanDocument12 pagesRPT Bi Tahun 2 SemakanNemo Teddy100% (1)
- Teradata Architecture PDF FreeDocument89 pagesTeradata Architecture PDF Freemail4moorthyNo ratings yet
- Teradata ArchitectureDocument89 pagesTeradata ArchitecturelogeshwaranNo ratings yet
- Teradata ArchitectureDocument27 pagesTeradata ArchitectureMahesh GhattamaneniNo ratings yet
- Teradata ArchitectureDocument27 pagesTeradata Architecturesivakrishna100% (1)
- Teradata OverviewDocument64 pagesTeradata OverviewVincenzo PresuttoNo ratings yet
- Aws (S3, Iam, Ec2, Emr and Redshift)Document16 pagesAws (S3, Iam, Ec2, Emr and Redshift)AkashRai100% (1)
- Teradata Beginner's Guide - ArchitectureDocument12 pagesTeradata Beginner's Guide - ArchitecturenirmalphNo ratings yet
- ADBMS Parallel and Distributed DatabasesDocument98 pagesADBMS Parallel and Distributed DatabasesTulipNo ratings yet
- Lecture 1 Parallel DatabasesDocument30 pagesLecture 1 Parallel DatabasesKumkumo Kussia KossaNo ratings yet
- Pegappt 161230102048Document8 pagesPegappt 161230102048BhargavNo ratings yet
- Major Components of Teradata ArchitectureDocument51 pagesMajor Components of Teradata Architectureinfa4adiNo ratings yet
- Target Corporation: Teradata Index DiagramsDocument9 pagesTarget Corporation: Teradata Index DiagramsVijay KumarNo ratings yet
- System Models For Distributed and Cloud ComputingDocument22 pagesSystem Models For Distributed and Cloud Computingchamp riderNo ratings yet
- Classification of Distributed Computing SystemsDocument14 pagesClassification of Distributed Computing Systemssuga1990No ratings yet
- Parallel Programming Platforms (Part 1) : CSE3057Y Parallel and Distributed SystemsDocument38 pagesParallel Programming Platforms (Part 1) : CSE3057Y Parallel and Distributed SystemssplokbovNo ratings yet
- Data Management and Information ProcessingDocument25 pagesData Management and Information ProcessingAbel IngawNo ratings yet
- Elective-I Advanced Database Management Systems: Unit IiDocument141 pagesElective-I Advanced Database Management Systems: Unit IiPranil Nandeshwar100% (1)
- Introduction To DBMSDocument37 pagesIntroduction To DBMSKIRUTHIKA KNo ratings yet
- Unit-5 Part1Document85 pagesUnit-5 Part1himateja mygopulaNo ratings yet
- What Is A Data Warehouse?Document7 pagesWhat Is A Data Warehouse?jupudiguptaNo ratings yet
- SystemModelsforDistributedandCloudComputing PDFDocument15 pagesSystemModelsforDistributedandCloudComputing PDFRavinderNo ratings yet
- Database Performance Optimization. Andrey AvtomonovDocument26 pagesDatabase Performance Optimization. Andrey AvtomonovK Kunal Raj100% (1)
- Teradata ArchitectureDocument5 pagesTeradata ArchitectureAnand VaNo ratings yet
- Teradata Day1Document21 pagesTeradata Day1Pindiganti100% (1)
- TEAM 1 TechDocument19 pagesTEAM 1 TechCsvv VardhanNo ratings yet
- Infrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITDocument32 pagesInfrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITTanushree ShenviNo ratings yet
- Explicitly Parallel PlatformsDocument90 pagesExplicitly Parallel PlatformswmanjonjoNo ratings yet
- Introduction of DSDocument41 pagesIntroduction of DSHarsh NebhwaniNo ratings yet
- Teradata Frequently Asking QuestionsDocument46 pagesTeradata Frequently Asking QuestionsSagarNo ratings yet
- b104 Rdbms ArchDocument11 pagesb104 Rdbms ArchanandNo ratings yet
- Parallel Computer Models: CEG 4131 Computer Architecture III Miodrag BolicDocument27 pagesParallel Computer Models: CEG 4131 Computer Architecture III Miodrag BolicShylaja BNo ratings yet
- Lecture 3 - ThreadsDocument28 pagesLecture 3 - Threadsfiraol.buloNo ratings yet
- TDD: Topics in Distributed Databases: Parallel Database Management SystemsDocument38 pagesTDD: Topics in Distributed Databases: Parallel Database Management SystemsTatiana umbaNo ratings yet
- Parallel Computing: Overview: John Urbanic Urbanic@psc - EduDocument34 pagesParallel Computing: Overview: John Urbanic Urbanic@psc - EduanjnasharmaNo ratings yet
- TERADATADocument55 pagesTERADATABada SainathNo ratings yet
- MC5501 Cloud ComputingDocument24 pagesMC5501 Cloud Computingsajithabanu banuNo ratings yet
- Microprocesadores Y Microcontroladores: Profesor: Javier Ferney Castillo Garcia Cel: 315 465 7286Document50 pagesMicroprocesadores Y Microcontroladores: Profesor: Javier Ferney Castillo Garcia Cel: 315 465 7286Raul Steven Ramos MuñozNo ratings yet
- Hardware Accleration For MLDocument26 pagesHardware Accleration For MLSai SumanthNo ratings yet
- Lecture 4 Network Topologies For Parallel ArchitectureDocument34 pagesLecture 4 Network Topologies For Parallel Architecturenimranoor137No ratings yet
- Parallel ProcessingDocument35 pagesParallel ProcessingGetu GeneneNo ratings yet
- HPC Lectures 1 5Document18 pagesHPC Lectures 1 5mohamed samyNo ratings yet
- Unit 1Document25 pagesUnit 1rishisharma4201No ratings yet
- Lecture 09Document25 pagesLecture 09Syed BadshahNo ratings yet
- Week 02Document115 pagesWeek 02muhammad shoaibNo ratings yet
- Parallel ProcessingDocument22 pagesParallel Processingsouravmittal2023No ratings yet
- Lecture - 1: The Database EnvironmentDocument29 pagesLecture - 1: The Database EnvironmentDina NabilNo ratings yet
- DDB SlidesDocument67 pagesDDB SlidesyNo ratings yet
- CICS 504 Computer OrganizationDocument35 pagesCICS 504 Computer OrganizationdollykaushalNo ratings yet
- A Summary On "Characterizing Processor Architectures For Programmable Network Interfaces"Document6 pagesA Summary On "Characterizing Processor Architectures For Programmable Network Interfaces"svasanth007No ratings yet
- DSA ReviewerDocument2 pagesDSA ReviewerACE RUSSELL DE SILVANo ratings yet
- Basics of Parallel Programming: Unit-1Document79 pagesBasics of Parallel Programming: Unit-1jai shree krishnaNo ratings yet
- cs668 Lec1 ParallelArchDocument18 pagescs668 Lec1 ParallelArchIshAureaNo ratings yet
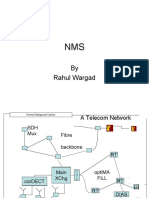
- By Rahul WargadDocument25 pagesBy Rahul WargadKailazhNo ratings yet
- Dbms IntroDocument36 pagesDbms IntroayanbaratNo ratings yet
- Cluster Computing4Document43 pagesCluster Computing4manikeshNo ratings yet
- Distributed DBMS IssuesDocument18 pagesDistributed DBMS IssuesAdiba khanNo ratings yet
- Lecture-13-14 Parallel and Distributed Systems Programming Models-JameelDocument70 pagesLecture-13-14 Parallel and Distributed Systems Programming Models-JameelAbdul BariiNo ratings yet
- Surya Software SolutionsDocument28 pagesSurya Software SolutionsGumadi Naresh KumarNo ratings yet
- "Unleashing the Power of Assembly Language: Mastering the World's Most Efficient Code"From Everand"Unleashing the Power of Assembly Language: Mastering the World's Most Efficient Code"No ratings yet
- MDN 0214DG PDFDocument112 pagesMDN 0214DG PDFJf SunnyNo ratings yet
- 1 Introduction To Data Science R Programming Edited 1 1Document74 pages1 Introduction To Data Science R Programming Edited 1 1Mamadou DiakiteNo ratings yet
- Program Design in COBOLDocument17 pagesProgram Design in COBOLAbdulwhhab Ali Al-ShehriNo ratings yet
- Task and Response Types PDFDocument14 pagesTask and Response Types PDFGuadalupe GódlenNo ratings yet
- Android Application On Agriculture DocumentationDocument29 pagesAndroid Application On Agriculture DocumentationVenugopal Chikkegowda67% (18)
- PPP Lesson Plan 2nd ClassDocument4 pagesPPP Lesson Plan 2nd Classapi-25730842450% (2)
- Improving The Performance of Business Rules and Calculation Scripts (ID 855821.1)Document1 pageImproving The Performance of Business Rules and Calculation Scripts (ID 855821.1)Damian KozaNo ratings yet
- Unit 9 Short Test 2B: GrammarDocument1 pageUnit 9 Short Test 2B: GrammarNiko626No ratings yet
- 2024 Spring ProjectDocument7 pages2024 Spring ProjectWentai NanNo ratings yet
- Literacy Homework Week 2 and 3 Term 4 2021Document1 pageLiteracy Homework Week 2 and 3 Term 4 2021api-395353190No ratings yet
- Oral Com Lesson 1 and 2Document31 pagesOral Com Lesson 1 and 2Russel BayaNo ratings yet
- Open Recruitment of Cambridge Teacher in BatamDocument2 pagesOpen Recruitment of Cambridge Teacher in BatamRia Chuswatun HasanahNo ratings yet
- KPIDocument671 pagesKPIdrummondlucianoNo ratings yet
- Norman Thomson Functional Programming With APLDocument2 pagesNorman Thomson Functional Programming With APLalexNo ratings yet
- English Essay BookDocument7 pagesEnglish Essay Bookaxmljinbf100% (1)
- NIOS Class 12 Chemistry October 2022 Past PaperDocument24 pagesNIOS Class 12 Chemistry October 2022 Past PaperthisNo ratings yet
- MIRC Auto-Join ScriptDocument5 pagesMIRC Auto-Join ScriptgamamewNo ratings yet
- Directions: Read and Analyze Each Item. Write The Letter of The Correct Answer On Your Answer SheetDocument5 pagesDirections: Read and Analyze Each Item. Write The Letter of The Correct Answer On Your Answer SheetRafaela OngNo ratings yet
- Stream Allmatch in Java With Examples - GeeksforGeeksDocument6 pagesStream Allmatch in Java With Examples - GeeksforGeeksAbsCoder SaxonNo ratings yet
- Midterm ExamDocument19 pagesMidterm ExamAndriyNo ratings yet
- GC 2024 04 28Document25 pagesGC 2024 04 28Angelica ToroNo ratings yet
- RH1ASB Unit 2 Marketing FINALDocument35 pagesRH1ASB Unit 2 Marketing FINALHex Dlt Jr.No ratings yet
- SAS #12 Speaking ENG189 SwuDocument6 pagesSAS #12 Speaking ENG189 SwumiaaNo ratings yet
- Lesson 3 Measures of Central TendencyDocument6 pagesLesson 3 Measures of Central TendencyEvelyn LabhananNo ratings yet
- II-English (Badhon, Pinky)Document5 pagesII-English (Badhon, Pinky)Lopa BhowmikNo ratings yet
- 07 Introduction To Organic ChemistryDocument28 pages07 Introduction To Organic ChemistryM BNo ratings yet
- This Is That Is Lesson Plan English 1Document2 pagesThis Is That Is Lesson Plan English 1FaithmaeSelmaGambe75% (8)























































































Download as pdf or txt
You might also like
- Performativity and The Image. Narrative, Representation, and The Uruk VaseDocument8 pagesPerformativity and The Image. Narrative, Representation, and The Uruk VaseMiguel Carceller SindreuNo ratings yet
- Guidelines For Writing Academic Papers at ESB 2018-09-13Document25 pagesGuidelines For Writing Academic Papers at ESB 2018-09-13SKNo ratings yet
- RPT Bi Tahun 2 SemakanDocument12 pagesRPT Bi Tahun 2 SemakanNemo Teddy100% (1)
- Teradata Architecture PDF FreeDocument89 pagesTeradata Architecture PDF Freemail4moorthyNo ratings yet
- Teradata ArchitectureDocument89 pagesTeradata ArchitecturelogeshwaranNo ratings yet
- Teradata ArchitectureDocument27 pagesTeradata ArchitectureMahesh GhattamaneniNo ratings yet
- Teradata ArchitectureDocument27 pagesTeradata Architecturesivakrishna100% (1)
- Teradata OverviewDocument64 pagesTeradata OverviewVincenzo PresuttoNo ratings yet
- Aws (S3, Iam, Ec2, Emr and Redshift)Document16 pagesAws (S3, Iam, Ec2, Emr and Redshift)AkashRai100% (1)
- Teradata Beginner's Guide - ArchitectureDocument12 pagesTeradata Beginner's Guide - ArchitecturenirmalphNo ratings yet
- ADBMS Parallel and Distributed DatabasesDocument98 pagesADBMS Parallel and Distributed DatabasesTulipNo ratings yet
- Lecture 1 Parallel DatabasesDocument30 pagesLecture 1 Parallel DatabasesKumkumo Kussia KossaNo ratings yet
- Pegappt 161230102048Document8 pagesPegappt 161230102048BhargavNo ratings yet
- Major Components of Teradata ArchitectureDocument51 pagesMajor Components of Teradata Architectureinfa4adiNo ratings yet
- Target Corporation: Teradata Index DiagramsDocument9 pagesTarget Corporation: Teradata Index DiagramsVijay KumarNo ratings yet
- System Models For Distributed and Cloud ComputingDocument22 pagesSystem Models For Distributed and Cloud Computingchamp riderNo ratings yet
- Classification of Distributed Computing SystemsDocument14 pagesClassification of Distributed Computing Systemssuga1990No ratings yet
- Parallel Programming Platforms (Part 1) : CSE3057Y Parallel and Distributed SystemsDocument38 pagesParallel Programming Platforms (Part 1) : CSE3057Y Parallel and Distributed SystemssplokbovNo ratings yet
- Data Management and Information ProcessingDocument25 pagesData Management and Information ProcessingAbel IngawNo ratings yet
- Elective-I Advanced Database Management Systems: Unit IiDocument141 pagesElective-I Advanced Database Management Systems: Unit IiPranil Nandeshwar100% (1)
- Introduction To DBMSDocument37 pagesIntroduction To DBMSKIRUTHIKA KNo ratings yet
- Unit-5 Part1Document85 pagesUnit-5 Part1himateja mygopulaNo ratings yet
- What Is A Data Warehouse?Document7 pagesWhat Is A Data Warehouse?jupudiguptaNo ratings yet
- SystemModelsforDistributedandCloudComputing PDFDocument15 pagesSystemModelsforDistributedandCloudComputing PDFRavinderNo ratings yet
- Database Performance Optimization. Andrey AvtomonovDocument26 pagesDatabase Performance Optimization. Andrey AvtomonovK Kunal Raj100% (1)
- Teradata ArchitectureDocument5 pagesTeradata ArchitectureAnand VaNo ratings yet
- Teradata Day1Document21 pagesTeradata Day1Pindiganti100% (1)
- TEAM 1 TechDocument19 pagesTEAM 1 TechCsvv VardhanNo ratings yet
- Infrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITDocument32 pagesInfrastructure of Data Warehouse: Ms. Ashwini Rao Asst - Prof.ITTanushree ShenviNo ratings yet
- Explicitly Parallel PlatformsDocument90 pagesExplicitly Parallel PlatformswmanjonjoNo ratings yet
- Introduction of DSDocument41 pagesIntroduction of DSHarsh NebhwaniNo ratings yet
- Teradata Frequently Asking QuestionsDocument46 pagesTeradata Frequently Asking QuestionsSagarNo ratings yet
- b104 Rdbms ArchDocument11 pagesb104 Rdbms ArchanandNo ratings yet
- Parallel Computer Models: CEG 4131 Computer Architecture III Miodrag BolicDocument27 pagesParallel Computer Models: CEG 4131 Computer Architecture III Miodrag BolicShylaja BNo ratings yet
- Lecture 3 - ThreadsDocument28 pagesLecture 3 - Threadsfiraol.buloNo ratings yet
- TDD: Topics in Distributed Databases: Parallel Database Management SystemsDocument38 pagesTDD: Topics in Distributed Databases: Parallel Database Management SystemsTatiana umbaNo ratings yet
- Parallel Computing: Overview: John Urbanic Urbanic@psc - EduDocument34 pagesParallel Computing: Overview: John Urbanic Urbanic@psc - EduanjnasharmaNo ratings yet
- TERADATADocument55 pagesTERADATABada SainathNo ratings yet
- MC5501 Cloud ComputingDocument24 pagesMC5501 Cloud Computingsajithabanu banuNo ratings yet
- Microprocesadores Y Microcontroladores: Profesor: Javier Ferney Castillo Garcia Cel: 315 465 7286Document50 pagesMicroprocesadores Y Microcontroladores: Profesor: Javier Ferney Castillo Garcia Cel: 315 465 7286Raul Steven Ramos MuñozNo ratings yet
- Hardware Accleration For MLDocument26 pagesHardware Accleration For MLSai SumanthNo ratings yet
- Lecture 4 Network Topologies For Parallel ArchitectureDocument34 pagesLecture 4 Network Topologies For Parallel Architecturenimranoor137No ratings yet
- Parallel ProcessingDocument35 pagesParallel ProcessingGetu GeneneNo ratings yet
- HPC Lectures 1 5Document18 pagesHPC Lectures 1 5mohamed samyNo ratings yet
- Unit 1Document25 pagesUnit 1rishisharma4201No ratings yet
- Lecture 09Document25 pagesLecture 09Syed BadshahNo ratings yet
- Week 02Document115 pagesWeek 02muhammad shoaibNo ratings yet
- Parallel ProcessingDocument22 pagesParallel Processingsouravmittal2023No ratings yet
- Lecture - 1: The Database EnvironmentDocument29 pagesLecture - 1: The Database EnvironmentDina NabilNo ratings yet
- DDB SlidesDocument67 pagesDDB SlidesyNo ratings yet
- CICS 504 Computer OrganizationDocument35 pagesCICS 504 Computer OrganizationdollykaushalNo ratings yet
- A Summary On "Characterizing Processor Architectures For Programmable Network Interfaces"Document6 pagesA Summary On "Characterizing Processor Architectures For Programmable Network Interfaces"svasanth007No ratings yet
- DSA ReviewerDocument2 pagesDSA ReviewerACE RUSSELL DE SILVANo ratings yet
- Basics of Parallel Programming: Unit-1Document79 pagesBasics of Parallel Programming: Unit-1jai shree krishnaNo ratings yet
- cs668 Lec1 ParallelArchDocument18 pagescs668 Lec1 ParallelArchIshAureaNo ratings yet
- By Rahul WargadDocument25 pagesBy Rahul WargadKailazhNo ratings yet
- Dbms IntroDocument36 pagesDbms IntroayanbaratNo ratings yet
- Cluster Computing4Document43 pagesCluster Computing4manikeshNo ratings yet
- Distributed DBMS IssuesDocument18 pagesDistributed DBMS IssuesAdiba khanNo ratings yet
- Lecture-13-14 Parallel and Distributed Systems Programming Models-JameelDocument70 pagesLecture-13-14 Parallel and Distributed Systems Programming Models-JameelAbdul BariiNo ratings yet
- Surya Software SolutionsDocument28 pagesSurya Software SolutionsGumadi Naresh KumarNo ratings yet
- "Unleashing the Power of Assembly Language: Mastering the World's Most Efficient Code"From Everand"Unleashing the Power of Assembly Language: Mastering the World's Most Efficient Code"No ratings yet
- MDN 0214DG PDFDocument112 pagesMDN 0214DG PDFJf SunnyNo ratings yet
- 1 Introduction To Data Science R Programming Edited 1 1Document74 pages1 Introduction To Data Science R Programming Edited 1 1Mamadou DiakiteNo ratings yet
- Program Design in COBOLDocument17 pagesProgram Design in COBOLAbdulwhhab Ali Al-ShehriNo ratings yet
- Task and Response Types PDFDocument14 pagesTask and Response Types PDFGuadalupe GódlenNo ratings yet
- Android Application On Agriculture DocumentationDocument29 pagesAndroid Application On Agriculture DocumentationVenugopal Chikkegowda67% (18)
- PPP Lesson Plan 2nd ClassDocument4 pagesPPP Lesson Plan 2nd Classapi-25730842450% (2)
- Improving The Performance of Business Rules and Calculation Scripts (ID 855821.1)Document1 pageImproving The Performance of Business Rules and Calculation Scripts (ID 855821.1)Damian KozaNo ratings yet
- Unit 9 Short Test 2B: GrammarDocument1 pageUnit 9 Short Test 2B: GrammarNiko626No ratings yet
- 2024 Spring ProjectDocument7 pages2024 Spring ProjectWentai NanNo ratings yet
- Literacy Homework Week 2 and 3 Term 4 2021Document1 pageLiteracy Homework Week 2 and 3 Term 4 2021api-395353190No ratings yet
- Oral Com Lesson 1 and 2Document31 pagesOral Com Lesson 1 and 2Russel BayaNo ratings yet
- Open Recruitment of Cambridge Teacher in BatamDocument2 pagesOpen Recruitment of Cambridge Teacher in BatamRia Chuswatun HasanahNo ratings yet
- KPIDocument671 pagesKPIdrummondlucianoNo ratings yet
- Norman Thomson Functional Programming With APLDocument2 pagesNorman Thomson Functional Programming With APLalexNo ratings yet
- English Essay BookDocument7 pagesEnglish Essay Bookaxmljinbf100% (1)
- NIOS Class 12 Chemistry October 2022 Past PaperDocument24 pagesNIOS Class 12 Chemistry October 2022 Past PaperthisNo ratings yet
- MIRC Auto-Join ScriptDocument5 pagesMIRC Auto-Join ScriptgamamewNo ratings yet
- Directions: Read and Analyze Each Item. Write The Letter of The Correct Answer On Your Answer SheetDocument5 pagesDirections: Read and Analyze Each Item. Write The Letter of The Correct Answer On Your Answer SheetRafaela OngNo ratings yet
- Stream Allmatch in Java With Examples - GeeksforGeeksDocument6 pagesStream Allmatch in Java With Examples - GeeksforGeeksAbsCoder SaxonNo ratings yet
- Midterm ExamDocument19 pagesMidterm ExamAndriyNo ratings yet
- GC 2024 04 28Document25 pagesGC 2024 04 28Angelica ToroNo ratings yet
- RH1ASB Unit 2 Marketing FINALDocument35 pagesRH1ASB Unit 2 Marketing FINALHex Dlt Jr.No ratings yet
- SAS #12 Speaking ENG189 SwuDocument6 pagesSAS #12 Speaking ENG189 SwumiaaNo ratings yet
- Lesson 3 Measures of Central TendencyDocument6 pagesLesson 3 Measures of Central TendencyEvelyn LabhananNo ratings yet
- II-English (Badhon, Pinky)Document5 pagesII-English (Badhon, Pinky)Lopa BhowmikNo ratings yet
- 07 Introduction To Organic ChemistryDocument28 pages07 Introduction To Organic ChemistryM BNo ratings yet
- This Is That Is Lesson Plan English 1Document2 pagesThis Is That Is Lesson Plan English 1FaithmaeSelmaGambe75% (8)