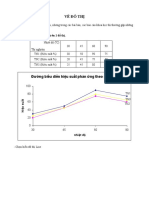
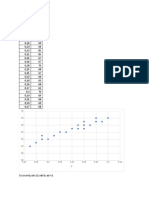
Download as xlsx, pdf, or txt
You might also like
- Huong Dan Doc Ket Qua Nghien Cuu - Nhom Cua HangDocument7 pagesHuong Dan Doc Ket Qua Nghien Cuu - Nhom Cua HangMinh AnhNo ratings yet
- CNTT Trong Hoa HocDocument144 pagesCNTT Trong Hoa HocPhuong NguyenNo ratings yet
- Bai Test UV Mo Hinh RR Level 1Document10 pagesBai Test UV Mo Hinh RR Level 1van.thanh26791No ratings yet
- Bài 5 Xu Ly Ket Qua Thi NghiemDocument13 pagesBài 5 Xu Ly Ket Qua Thi Nghiemsamlai2k3No ratings yet
- Bieu Do Tan SoDocument27 pagesBieu Do Tan Sobokki leeNo ratings yet
- Quiz Test Full 3chapter 520Document12 pagesQuiz Test Full 3chapter 520Khoa Phạm ViệtNo ratings yet
- ChâuGiaHàoDocument9 pagesChâuGiaHàoHào ChâuNo ratings yet
- Bao Cao MauDocument18 pagesBao Cao Mautrinhminh562No ratings yet
- BIỂU ĐỒ X VÀ RDocument8 pagesBIỂU ĐỒ X VÀ RDiễm TiênNo ratings yet
- Phan Tich Du LieuDocument21 pagesPhan Tich Du LieuDinh DungNo ratings yet
- thống kê ứng dụngDocument134 pagesthống kê ứng dụng21125620No ratings yet
- Bai 2 Q7 UpdatedDocument41 pagesBai 2 Q7 UpdatedTiến Nguyễn TrọngNo ratings yet
- Tiểu Luận: Tổng Liên Đoàn Lao Động Việt Nam Trường Đại Học Tôn Đức ThắngDocument78 pagesTiểu Luận: Tổng Liên Đoàn Lao Động Việt Nam Trường Đại Học Tôn Đức ThắngMAI TRAN THI NGOCNo ratings yet
- BaiTap3 Nhom17Document34 pagesBaiTap3 Nhom17tramypt2653No ratings yet
- Bài tập thống kê ứng dung và thiết kế thí nghiệmDocument24 pagesBài tập thống kê ứng dung và thiết kế thí nghiệmnhiNo ratings yet
- Chương 5Document125 pagesChương 52 VinhthanhdraoNo ratings yet
- Cách Chuyển Dạng Số LiệuDocument9 pagesCách Chuyển Dạng Số Liệunhathong.172No ratings yet
- Các bước phân tích dữ liệuDocument6 pagesCác bước phân tích dữ liệuAnh Đỗ Đặng MinhNo ratings yet
- Check SheetDocument18 pagesCheck SheetMỹ LinhNo ratings yet
- TH C Hành 2023Document2 pagesTH C Hành 2023dungnguyenquan102No ratings yet
- 2.4 - 2.6 UdthDocument13 pages2.4 - 2.6 UdthVõ Thị Tuyết NgânNo ratings yet
- Chuong 4Document30 pagesChuong 4tamb2203834No ratings yet
- Chuong 4 Truy Van Du Lieu 1442Document51 pagesChuong 4 Truy Van Du Lieu 1442White WhiteNo ratings yet
- Baitap ExcelDocument9 pagesBaitap ExcelThùy VânNo ratings yet
- Lương Nguyễn Kim ÁnhDocument10 pagesLương Nguyễn Kim Ánh02 Kim Ánh Lương NguyễnNo ratings yet
- Homework 2Document4 pagesHomework 2Hồ Thị Minh MỹNo ratings yet
- BTVN3Document3 pagesBTVN3Thi ĐinhNo ratings yet
- 5 Dang MRBDocument21 pages5 Dang MRB22125327No ratings yet
- Nhom3 TiemKiemSapXep (TT) CountingRadixDocument40 pagesNhom3 TiemKiemSapXep (TT) CountingRadixVăn MinhNo ratings yet
- 11 - A Graph Analysis - (v7.0)Document25 pages11 - A Graph Analysis - (v7.0)Nam Quang TranNo ratings yet
- Bài tập lớn ĐSTT Nhóm 8 L20Document7 pagesBài tập lớn ĐSTT Nhóm 8 L20VY TRẦN ĐOÀN NHẬTNo ratings yet
- Các Mẫu Số Đặc Trưng Của Mẫu Số Liệu Bản Chính ThứcDocument6 pagesCác Mẫu Số Đặc Trưng Của Mẫu Số Liệu Bản Chính ThứcYến LinhNo ratings yet
- Phan Tich Cum Va Ban Do Nhan ThucDocument71 pagesPhan Tich Cum Va Ban Do Nhan ThucNgơTiênSinhNo ratings yet
- Ví D Multi AnalysisDocument4 pagesVí D Multi AnalysisNguyễn OanhNo ratings yet
- Ngon-Ngu-R - Lecture-2 - Phan-Tich-Do-Thi - (Cuuduongthancong - Com)Document8 pagesNgon-Ngu-R - Lecture-2 - Phan-Tich-Do-Thi - (Cuuduongthancong - Com)NeilFaverNo ratings yet
- Xac-Suat-Thong-Ke - To-Anh-Dung - Bai-Th01 - (Cuuduongthancong - Com)Document6 pagesXac-Suat-Thong-Ke - To-Anh-Dung - Bai-Th01 - (Cuuduongthancong - Com)FlufflyNo ratings yet
- SPSS For Data AnalysisDocument5 pagesSPSS For Data AnalysisTú LêNo ratings yet
- C3 trình bày dữ liệuDocument24 pagesC3 trình bày dữ liệuDũng ĐặngNo ratings yet
- Tiền xử lý dữ liệu (Horse Colic dataset)Document10 pagesTiền xử lý dữ liệu (Horse Colic dataset)Cu BinNo ratings yet
- BÀI TẬP THỐNG KÊ ỨNG DỤNGDocument4 pagesBÀI TẬP THỐNG KÊ ỨNG DỤNGKim LeNo ratings yet
- Huong Dan Thuc Hanh Thong Ke R - BOMON-DSODocument62 pagesHuong Dan Thuc Hanh Thong Ke R - BOMON-DSOTrần Thuỳ DươngNo ratings yet
- Chương 1 Xử lý số liệu kết quả phân tíchDocument45 pagesChương 1 Xử lý số liệu kết quả phân tíchNguyễn A.ThưNo ratings yet
- Chương 3Document35 pagesChương 3Vân ThanhNo ratings yet
- Ôn Thi Giữa Kỳ Môn Thống Kê Máy Tính Và Ứng Dụng CtDocument12 pagesÔn Thi Giữa Kỳ Môn Thống Kê Máy Tính Và Ứng Dụng CtMinh Huy LêNo ratings yet
- Tien Xu Ly Du LieuDocument28 pagesTien Xu Ly Du LieuVũ NguyễnNo ratings yet
- Hướng Dẫn Bài Tập Tkhtđ.1Document54 pagesHướng Dẫn Bài Tập Tkhtđ.122842179No ratings yet
- ÔN TẬP GIỮA KÌ PHÂN TÍCH DỮ LIỆU TRONG KINH DOANHDocument5 pagesÔN TẬP GIỮA KÌ PHÂN TÍCH DỮ LIỆU TRONG KINH DOANHTường Vy Nguyễn ThịNo ratings yet
- Task 2Document3 pagesTask 2Thư AnhNo ratings yet
- BTL Cae FemDocument11 pagesBTL Cae FemAnh ĐỗNo ratings yet
- BTL2 LamThanhDuong 1912980Document23 pagesBTL2 LamThanhDuong 1912980Bá CườngNo ratings yet
- BTL dự báo Nguyễn Thị Ngọc HuyềnDocument18 pagesBTL dự báo Nguyễn Thị Ngọc HuyềnHuyền Nguyễn NgọcNo ratings yet
- Tbay khái niệm cây tìm kiếm nhị phân và cấu trúc lớp của cây tìm kiếm nhị phânDocument14 pagesTbay khái niệm cây tìm kiếm nhị phân và cấu trúc lớp của cây tìm kiếm nhị phânPhan Duy ChiếnNo ratings yet
- Sach Bai Tap Thong Ke - QTKD - EPUDocument92 pagesSach Bai Tap Thong Ke - QTKD - EPUQuỳnh ThúyNo ratings yet
- QTCL 23-27Document6 pagesQTCL 23-27Lưu ThúyNo ratings yet
- Bai Luyen Excel 01 - de BaiDocument9 pagesBai Luyen Excel 01 - de BaiTrần Xuân VũNo ratings yet
- H I Quy Ols Trong StataDocument13 pagesH I Quy Ols Trong StataQUYEN LY MYNo ratings yet
- Bài Làm SpssDocument37 pagesBài Làm SpssTrần Phương LanNo ratings yet
- BÀI THỰC HÀNH R.1 - Thống kê mô tảDocument5 pagesBÀI THỰC HÀNH R.1 - Thống kê mô tảTrần Thuỳ DươngNo ratings yet
- UntitledDocument27 pagesUntitledNinh BuiNo ratings yet
- H P Đ NG H P TÁC KINH DOANH Chung 1Document4 pagesH P Đ NG H P TÁC KINH DOANH Chung 1Ninh BuiNo ratings yet
- Vào DATA - Data Analysis - T-Test: Paired Two Sample For MeansDocument9 pagesVào DATA - Data Analysis - T-Test: Paired Two Sample For MeansNinh BuiNo ratings yet
- Ngày bán Tên hàng Đơn vị tính Số hóa đơn Số lượng Đơn giá (VND) Thành tiền (VND)Document12 pagesNgày bán Tên hàng Đơn vị tính Số hóa đơn Số lượng Đơn giá (VND) Thành tiền (VND)Ninh BuiNo ratings yet