
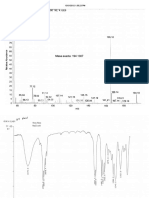
Tema6 Punto4
Tema6 Punto4
You might also like
- Single Case Methods in Clinical Psychology A Practical Guide by Stephen MorleyDocument213 pagesSingle Case Methods in Clinical Psychology A Practical Guide by Stephen MorleyPabloMarianiNo ratings yet
- MODULE-11 Practical Research PDFDocument123 pagesMODULE-11 Practical Research PDFAlyssum Marie91% (11)
- Chi-Square Test of IndependenceDocument13 pagesChi-Square Test of IndependenceNathan NathanNo ratings yet
- 3 8 C 2 Sys. Lim., N Infinity Source Limit, K InfinityDocument11 pages3 8 C 2 Sys. Lim., N Infinity Source Limit, K InfinityDiego MolinaNo ratings yet
- and Shortage Administration Cost Per Unit CDocument9 pagesand Shortage Administration Cost Per Unit CSơn Trần BảoNo ratings yet
- Raices de Ecuaciones Metodo CerradoDocument8 pagesRaices de Ecuaciones Metodo CerradoGetzemani MejiaNo ratings yet
- Sheethal - Nasu - FINAL EXAMDocument11 pagesSheethal - Nasu - FINAL EXAMSudharshni BalasubramaniyamNo ratings yet
- Ecotric ProjectDocument3 pagesEcotric Projectaadolf2004No ratings yet
- Complex Engineering Problem of Thermodynamics 2Document20 pagesComplex Engineering Problem of Thermodynamics 2Shahabuddin Khan NiaziNo ratings yet
- A. Bos B. Ny C. CH D. Ind 1. Det 2. Pit 3. Buf: Shipping Costs 8 2 35 11 12 3 31 5 10 1 34 9Document103 pagesA. Bos B. Ny C. CH D. Ind 1. Det 2. Pit 3. Buf: Shipping Costs 8 2 35 11 12 3 31 5 10 1 34 9kavya guptaNo ratings yet
- Para Maã Ana 1Document7 pagesPara Maã Ana 1VirginiaNo ratings yet
- Concrete Tensile CDP PropsDocument22 pagesConcrete Tensile CDP PropsHizbawi Sisay100% (1)
- Lampiran 3: Hasil Pengolahan Data Dengan SPSS 21.0: Case Processing SummaryDocument7 pagesLampiran 3: Hasil Pengolahan Data Dengan SPSS 21.0: Case Processing SummaryDenny PaatNo ratings yet
- RascuDocument3 pagesRascuГеорге УнгурянуNo ratings yet
- ASSIGNMENT 2 Thermodynamic ShammilDocument17 pagesASSIGNMENT 2 Thermodynamic ShammilNor Hamizah HassanNo ratings yet
- Experiment: Sheet Resistance and the Calculation of Resistivity () or Thickness (t) and Thermal coefficient of Resistivity (α)Document4 pagesExperiment: Sheet Resistance and the Calculation of Resistivity () or Thickness (t) and Thermal coefficient of Resistivity (α)AdityaNo ratings yet
- RegressionDocument4 pagesRegressionasNo ratings yet
- Simplex Actual Eff Report: CottonDocument6 pagesSimplex Actual Eff Report: CottonDanish NawazNo ratings yet
- Parametros Actividad (Recuperado) - 091156Document27 pagesParametros Actividad (Recuperado) - 091156Isme DurstNo ratings yet
- SPC Calculator 1Document15 pagesSPC Calculator 1NarasimharaghavanPuliyurKrishnaswamyNo ratings yet
- Diagrama P-Xy Ideal - No IdealDocument3 pagesDiagrama P-Xy Ideal - No IdealUrslan Scray KrepersNo ratings yet
- Kapal Tanker: Ocean Pioner: General DataDocument14 pagesKapal Tanker: Ocean Pioner: General DataTesalonika DebyNo ratings yet
- Total Variance ExplainedDocument9 pagesTotal Variance ExplainedVân Anh Phan BùiNo ratings yet
- Week 4 - Cont. Week 3 Slides - UpdatedDocument43 pagesWeek 4 - Cont. Week 3 Slides - UpdatedSin TungNo ratings yet
- Uji Validitas Variabel Factor Analysis: Leader Member Exchange (LMX) (X1)Document9 pagesUji Validitas Variabel Factor Analysis: Leader Member Exchange (LMX) (X1)endangsukesiNo ratings yet
- RegressionDocument6 pagesRegressionian92193No ratings yet
- Analisis Faktor 1. Analisis Faktor Variabel Desentralisasi: KMO and Bartlett's TestDocument5 pagesAnalisis Faktor 1. Analisis Faktor Variabel Desentralisasi: KMO and Bartlett's TestIvan FherdifhaNo ratings yet
- Regression StatisticsDocument4 pagesRegression Statisticsshintya nadaNo ratings yet
- Regression StatisticsDocument4 pagesRegression Statisticsshintya nadaNo ratings yet
- Grafica K Vs Da/Dn: Hago La Regresion Lineal Con LogaritmosDocument3 pagesGrafica K Vs Da/Dn: Hago La Regresion Lineal Con Logaritmossebastian becerraNo ratings yet
- Tugas 3 Reno Susanto Example 2.9Document2 pagesTugas 3 Reno Susanto Example 2.9Kagak AjekNo ratings yet
- 1766 Bcom 19 Excel FileDocument6 pages1766 Bcom 19 Excel FileDaniyal WahabNo ratings yet
- Uji Validitas Tugas Pak RahmatDocument3 pagesUji Validitas Tugas Pak RahmatDewi CandraNo ratings yet
- PE - Tutorial4 - 60011180012 - Bhavya ModiDocument5 pagesPE - Tutorial4 - 60011180012 - Bhavya Modibhavya modiNo ratings yet
- Case Study BQT About Sunglass StoresDocument5 pagesCase Study BQT About Sunglass StoresztgaffNo ratings yet
- Tutorial 12Document9 pagesTutorial 12HENG QUAN PANNo ratings yet
- Area 1 Area 2Document8 pagesArea 1 Area 2Raúl BorbúaNo ratings yet
- Frequency Analysis For Computation For Distribution System: Babak District, Island Garden City of SamalDocument4 pagesFrequency Analysis For Computation For Distribution System: Babak District, Island Garden City of SamalAilanKhenDasallaNo ratings yet
- Artea: Name - Anamika Gupta PGP ID - PGP37399Document1 pageArtea: Name - Anamika Gupta PGP ID - PGP37399055ANAMIKA GUPTANo ratings yet
- Experiment No - 5 Power Plants: Name: - Shayan Ahmed Raghib - Regd. No. - 2015-ME-08 - Date: - 26/02/19Document2 pagesExperiment No - 5 Power Plants: Name: - Shayan Ahmed Raghib - Regd. No. - 2015-ME-08 - Date: - 26/02/19SaAhRaNo ratings yet
- Wiggins IPR TryDocument22 pagesWiggins IPR TryAkbar PutraNo ratings yet
- HW2 Ans RevDocument14 pagesHW2 Ans RevanonymoussionNo ratings yet
- Error Function Table: (x) = π e dtDocument55 pagesError Function Table: (x) = π e dtLưu Văn ĐứcNo ratings yet
- YEARDocument14 pagesYEARtassawarNo ratings yet
- D&D CS1 Pes1202202920 PDFDocument6 pagesD&D CS1 Pes1202202920 PDFmohammed yaseenNo ratings yet
- Mgt201 1st AssignmentDocument2 pagesMgt201 1st AssignmentAL UMARNo ratings yet
- 'MITS6002 Business Analytics: Assignment 3Document11 pages'MITS6002 Business Analytics: Assignment 3ZERO TO VARIABLENo ratings yet
- All Combinations LatestDocument13 pagesAll Combinations Latestmahmoud salamaNo ratings yet
- FM Assignment 2Document9 pagesFM Assignment 2Sanskar SharmaNo ratings yet
- FKCJHDGHFVBVDocument59 pagesFKCJHDGHFVBVrosalenaaudinaNo ratings yet
- Thermistor ElkDocument9 pagesThermistor ElkJUANNo ratings yet
- Factor Analysis: KMO and Bartlett's TestDocument31 pagesFactor Analysis: KMO and Bartlett's TestNgateno TenoNo ratings yet
- Phân Tích EFADocument5 pagesPhân Tích EFAAn PhúcNo ratings yet
- B.G.M.U. - Referat 2 SlavkoDocument7 pagesB.G.M.U. - Referat 2 SlavkoVioleta PopaNo ratings yet
- (Build-Up Test) : Ráctica Ruebas de EstauraciónDocument2 pages(Build-Up Test) : Ráctica Ruebas de EstauraciónrenatoNo ratings yet
- 4G KPI Report - 24082018Document147 pages4G KPI Report - 24082018adarsh singhNo ratings yet
- Book 1Document5 pagesBook 1Andersonkevin GwenhureNo ratings yet
- Statistics Assignment - 2-3Document7 pagesStatistics Assignment - 2-3NavinNo ratings yet
- Assignment Module-9 Coefficient of CorrelationDocument4 pagesAssignment Module-9 Coefficient of CorrelationFranchesca CuraNo ratings yet
- MM Conversion ChartDocument3 pagesMM Conversion Chartkm1790No ratings yet
- Practica de Aleatorios TDDocument15 pagesPractica de Aleatorios TDRonald AlburaNo ratings yet
- More Minute Math Drills, Grades 3 - 6: Multiplication and DivisionFrom EverandMore Minute Math Drills, Grades 3 - 6: Multiplication and DivisionRating: 5 out of 5 stars5/5 (1)
- 2020 CustomerEducationPlaybookDocument16 pages2020 CustomerEducationPlaybookViniloNo ratings yet
- Decision Making Styles Among It ProfessionalsDocument7 pagesDecision Making Styles Among It ProfessionalsAnonymous CwJeBCAXpNo ratings yet
- Lesson 8 Hypothesis Testing With One Sample.v3lectureDocument70 pagesLesson 8 Hypothesis Testing With One Sample.v3lecturekyle encarnacionNo ratings yet
- Pengaruh Kualitas Pelayanan Dan Keragaman Produk Terhadap Kepuasan Konsumen Pada Toko King Di Malang Hendro Yuwono, Syamswana YuwanaDocument16 pagesPengaruh Kualitas Pelayanan Dan Keragaman Produk Terhadap Kepuasan Konsumen Pada Toko King Di Malang Hendro Yuwono, Syamswana YuwanaAchmad Dzikriy Naufal TsuwwibaNo ratings yet
- Master Report Format TemplateDocument2 pagesMaster Report Format TemplateKavita SukhijaNo ratings yet
- Priya 2020 Case Study Methodology of Qualitative Research Key Attributes and Navigating The Conundrums in ItsDocument17 pagesPriya 2020 Case Study Methodology of Qualitative Research Key Attributes and Navigating The Conundrums in ItsWayan Gede Adi SuastawanNo ratings yet
- Chapter 5 - Demand Estimation - Farrukh Wazir Khan - Fall22Document22 pagesChapter 5 - Demand Estimation - Farrukh Wazir Khan - Fall22IFRA AFZALNo ratings yet
- Kul 6 - Bias Dan Confounding Dalam EpidemiologiDocument52 pagesKul 6 - Bias Dan Confounding Dalam EpidemiologibenzabensaaNo ratings yet
- MCQDocument2 pagesMCQEngr Mujahid IqbalNo ratings yet
- SamplingDocument17 pagesSamplingManika GuptaNo ratings yet
- Lesson 1 Basic StatisticsDocument7 pagesLesson 1 Basic StatisticsRoxette Turingan TalosigNo ratings yet
- Impact Factor: Formula For CalculationDocument4 pagesImpact Factor: Formula For CalculationTamoor TariqNo ratings yet
- Practical Research 1 Quarter 1 - Module 4: Quantitative and Qualitative ResearchDocument13 pagesPractical Research 1 Quarter 1 - Module 4: Quantitative and Qualitative ResearchMark Allen LabasanNo ratings yet
- NTA JEE 2024 - 27 29 30 31 Jan 1st Feb 2024Document42 pagesNTA JEE 2024 - 27 29 30 31 Jan 1st Feb 2024manivignesh130407No ratings yet
- Mooney Problem Check ListDocument5 pagesMooney Problem Check ListAman ZahraNo ratings yet
- This Content Downloaded From 118.71.190.165 On Tue, 16 Aug 2022 15:31:50 UTCDocument15 pagesThis Content Downloaded From 118.71.190.165 On Tue, 16 Aug 2022 15:31:50 UTCseconbbNo ratings yet
- Testing of HypothesisDocument37 pagesTesting of Hypothesisabhinav jangirNo ratings yet
- Test - Random NumbersDocument47 pagesTest - Random NumbersYumeNo ratings yet
- Swati+B WaterManagementSystem ManalotoCastillo ALDocument5 pagesSwati+B WaterManagementSystem ManalotoCastillo ALEthan OuroNo ratings yet
- A Dream of A Retirement - The Longitudinal ExperiencesDocument21 pagesA Dream of A Retirement - The Longitudinal Experiences201900856No ratings yet
- Additional RRL WoohooDocument7 pagesAdditional RRL Woohoomitzi lorillaNo ratings yet
- A Comparative Study of Data Splitting Algorithms For Machine Learning Model SelectionDocument29 pagesA Comparative Study of Data Splitting Algorithms For Machine Learning Model SelectionELIANENo ratings yet
- Chapter 2. GeES 3026 Geography and Environmental Studies 2022Document49 pagesChapter 2. GeES 3026 Geography and Environmental Studies 2022moges lakeNo ratings yet
- 2019 Jan Assignment ARMDocument1 page2019 Jan Assignment ARMtinuvalsapaulNo ratings yet
- Research Design Canvas: Name: Title of ThesisDocument2 pagesResearch Design Canvas: Name: Title of Thesisaswar teknikNo ratings yet
- Research Paper Procedure ExampleDocument6 pagesResearch Paper Procedure Examplegsrkoxplg100% (1)
- SPIR SSPA Foundations of Statistical Analysis 2022Document2 pagesSPIR SSPA Foundations of Statistical Analysis 2022foxNo ratings yet
























































































Download as pdf or txt
You might also like
- Single Case Methods in Clinical Psychology A Practical Guide by Stephen MorleyDocument213 pagesSingle Case Methods in Clinical Psychology A Practical Guide by Stephen MorleyPabloMarianiNo ratings yet
- MODULE-11 Practical Research PDFDocument123 pagesMODULE-11 Practical Research PDFAlyssum Marie91% (11)
- Chi-Square Test of IndependenceDocument13 pagesChi-Square Test of IndependenceNathan NathanNo ratings yet
- 3 8 C 2 Sys. Lim., N Infinity Source Limit, K InfinityDocument11 pages3 8 C 2 Sys. Lim., N Infinity Source Limit, K InfinityDiego MolinaNo ratings yet
- and Shortage Administration Cost Per Unit CDocument9 pagesand Shortage Administration Cost Per Unit CSơn Trần BảoNo ratings yet
- Raices de Ecuaciones Metodo CerradoDocument8 pagesRaices de Ecuaciones Metodo CerradoGetzemani MejiaNo ratings yet
- Sheethal - Nasu - FINAL EXAMDocument11 pagesSheethal - Nasu - FINAL EXAMSudharshni BalasubramaniyamNo ratings yet
- Ecotric ProjectDocument3 pagesEcotric Projectaadolf2004No ratings yet
- Complex Engineering Problem of Thermodynamics 2Document20 pagesComplex Engineering Problem of Thermodynamics 2Shahabuddin Khan NiaziNo ratings yet
- A. Bos B. Ny C. CH D. Ind 1. Det 2. Pit 3. Buf: Shipping Costs 8 2 35 11 12 3 31 5 10 1 34 9Document103 pagesA. Bos B. Ny C. CH D. Ind 1. Det 2. Pit 3. Buf: Shipping Costs 8 2 35 11 12 3 31 5 10 1 34 9kavya guptaNo ratings yet
- Para Maã Ana 1Document7 pagesPara Maã Ana 1VirginiaNo ratings yet
- Concrete Tensile CDP PropsDocument22 pagesConcrete Tensile CDP PropsHizbawi Sisay100% (1)
- Lampiran 3: Hasil Pengolahan Data Dengan SPSS 21.0: Case Processing SummaryDocument7 pagesLampiran 3: Hasil Pengolahan Data Dengan SPSS 21.0: Case Processing SummaryDenny PaatNo ratings yet
- RascuDocument3 pagesRascuГеорге УнгурянуNo ratings yet
- ASSIGNMENT 2 Thermodynamic ShammilDocument17 pagesASSIGNMENT 2 Thermodynamic ShammilNor Hamizah HassanNo ratings yet
- Experiment: Sheet Resistance and the Calculation of Resistivity () or Thickness (t) and Thermal coefficient of Resistivity (α)Document4 pagesExperiment: Sheet Resistance and the Calculation of Resistivity () or Thickness (t) and Thermal coefficient of Resistivity (α)AdityaNo ratings yet
- RegressionDocument4 pagesRegressionasNo ratings yet
- Simplex Actual Eff Report: CottonDocument6 pagesSimplex Actual Eff Report: CottonDanish NawazNo ratings yet
- Parametros Actividad (Recuperado) - 091156Document27 pagesParametros Actividad (Recuperado) - 091156Isme DurstNo ratings yet
- SPC Calculator 1Document15 pagesSPC Calculator 1NarasimharaghavanPuliyurKrishnaswamyNo ratings yet
- Diagrama P-Xy Ideal - No IdealDocument3 pagesDiagrama P-Xy Ideal - No IdealUrslan Scray KrepersNo ratings yet
- Kapal Tanker: Ocean Pioner: General DataDocument14 pagesKapal Tanker: Ocean Pioner: General DataTesalonika DebyNo ratings yet
- Total Variance ExplainedDocument9 pagesTotal Variance ExplainedVân Anh Phan BùiNo ratings yet
- Week 4 - Cont. Week 3 Slides - UpdatedDocument43 pagesWeek 4 - Cont. Week 3 Slides - UpdatedSin TungNo ratings yet
- Uji Validitas Variabel Factor Analysis: Leader Member Exchange (LMX) (X1)Document9 pagesUji Validitas Variabel Factor Analysis: Leader Member Exchange (LMX) (X1)endangsukesiNo ratings yet
- RegressionDocument6 pagesRegressionian92193No ratings yet
- Analisis Faktor 1. Analisis Faktor Variabel Desentralisasi: KMO and Bartlett's TestDocument5 pagesAnalisis Faktor 1. Analisis Faktor Variabel Desentralisasi: KMO and Bartlett's TestIvan FherdifhaNo ratings yet
- Regression StatisticsDocument4 pagesRegression Statisticsshintya nadaNo ratings yet
- Regression StatisticsDocument4 pagesRegression Statisticsshintya nadaNo ratings yet
- Grafica K Vs Da/Dn: Hago La Regresion Lineal Con LogaritmosDocument3 pagesGrafica K Vs Da/Dn: Hago La Regresion Lineal Con Logaritmossebastian becerraNo ratings yet
- Tugas 3 Reno Susanto Example 2.9Document2 pagesTugas 3 Reno Susanto Example 2.9Kagak AjekNo ratings yet
- 1766 Bcom 19 Excel FileDocument6 pages1766 Bcom 19 Excel FileDaniyal WahabNo ratings yet
- Uji Validitas Tugas Pak RahmatDocument3 pagesUji Validitas Tugas Pak RahmatDewi CandraNo ratings yet
- PE - Tutorial4 - 60011180012 - Bhavya ModiDocument5 pagesPE - Tutorial4 - 60011180012 - Bhavya Modibhavya modiNo ratings yet
- Case Study BQT About Sunglass StoresDocument5 pagesCase Study BQT About Sunglass StoresztgaffNo ratings yet
- Tutorial 12Document9 pagesTutorial 12HENG QUAN PANNo ratings yet
- Area 1 Area 2Document8 pagesArea 1 Area 2Raúl BorbúaNo ratings yet
- Frequency Analysis For Computation For Distribution System: Babak District, Island Garden City of SamalDocument4 pagesFrequency Analysis For Computation For Distribution System: Babak District, Island Garden City of SamalAilanKhenDasallaNo ratings yet
- Artea: Name - Anamika Gupta PGP ID - PGP37399Document1 pageArtea: Name - Anamika Gupta PGP ID - PGP37399055ANAMIKA GUPTANo ratings yet
- Experiment No - 5 Power Plants: Name: - Shayan Ahmed Raghib - Regd. No. - 2015-ME-08 - Date: - 26/02/19Document2 pagesExperiment No - 5 Power Plants: Name: - Shayan Ahmed Raghib - Regd. No. - 2015-ME-08 - Date: - 26/02/19SaAhRaNo ratings yet
- Wiggins IPR TryDocument22 pagesWiggins IPR TryAkbar PutraNo ratings yet
- HW2 Ans RevDocument14 pagesHW2 Ans RevanonymoussionNo ratings yet
- Error Function Table: (x) = π e dtDocument55 pagesError Function Table: (x) = π e dtLưu Văn ĐứcNo ratings yet
- YEARDocument14 pagesYEARtassawarNo ratings yet
- D&D CS1 Pes1202202920 PDFDocument6 pagesD&D CS1 Pes1202202920 PDFmohammed yaseenNo ratings yet
- Mgt201 1st AssignmentDocument2 pagesMgt201 1st AssignmentAL UMARNo ratings yet
- 'MITS6002 Business Analytics: Assignment 3Document11 pages'MITS6002 Business Analytics: Assignment 3ZERO TO VARIABLENo ratings yet
- All Combinations LatestDocument13 pagesAll Combinations Latestmahmoud salamaNo ratings yet
- FM Assignment 2Document9 pagesFM Assignment 2Sanskar SharmaNo ratings yet
- FKCJHDGHFVBVDocument59 pagesFKCJHDGHFVBVrosalenaaudinaNo ratings yet
- Thermistor ElkDocument9 pagesThermistor ElkJUANNo ratings yet
- Factor Analysis: KMO and Bartlett's TestDocument31 pagesFactor Analysis: KMO and Bartlett's TestNgateno TenoNo ratings yet
- Phân Tích EFADocument5 pagesPhân Tích EFAAn PhúcNo ratings yet
- B.G.M.U. - Referat 2 SlavkoDocument7 pagesB.G.M.U. - Referat 2 SlavkoVioleta PopaNo ratings yet
- (Build-Up Test) : Ráctica Ruebas de EstauraciónDocument2 pages(Build-Up Test) : Ráctica Ruebas de EstauraciónrenatoNo ratings yet
- 4G KPI Report - 24082018Document147 pages4G KPI Report - 24082018adarsh singhNo ratings yet
- Book 1Document5 pagesBook 1Andersonkevin GwenhureNo ratings yet
- Statistics Assignment - 2-3Document7 pagesStatistics Assignment - 2-3NavinNo ratings yet
- Assignment Module-9 Coefficient of CorrelationDocument4 pagesAssignment Module-9 Coefficient of CorrelationFranchesca CuraNo ratings yet
- MM Conversion ChartDocument3 pagesMM Conversion Chartkm1790No ratings yet
- Practica de Aleatorios TDDocument15 pagesPractica de Aleatorios TDRonald AlburaNo ratings yet
- More Minute Math Drills, Grades 3 - 6: Multiplication and DivisionFrom EverandMore Minute Math Drills, Grades 3 - 6: Multiplication and DivisionRating: 5 out of 5 stars5/5 (1)
- 2020 CustomerEducationPlaybookDocument16 pages2020 CustomerEducationPlaybookViniloNo ratings yet
- Decision Making Styles Among It ProfessionalsDocument7 pagesDecision Making Styles Among It ProfessionalsAnonymous CwJeBCAXpNo ratings yet
- Lesson 8 Hypothesis Testing With One Sample.v3lectureDocument70 pagesLesson 8 Hypothesis Testing With One Sample.v3lecturekyle encarnacionNo ratings yet
- Pengaruh Kualitas Pelayanan Dan Keragaman Produk Terhadap Kepuasan Konsumen Pada Toko King Di Malang Hendro Yuwono, Syamswana YuwanaDocument16 pagesPengaruh Kualitas Pelayanan Dan Keragaman Produk Terhadap Kepuasan Konsumen Pada Toko King Di Malang Hendro Yuwono, Syamswana YuwanaAchmad Dzikriy Naufal TsuwwibaNo ratings yet
- Master Report Format TemplateDocument2 pagesMaster Report Format TemplateKavita SukhijaNo ratings yet
- Priya 2020 Case Study Methodology of Qualitative Research Key Attributes and Navigating The Conundrums in ItsDocument17 pagesPriya 2020 Case Study Methodology of Qualitative Research Key Attributes and Navigating The Conundrums in ItsWayan Gede Adi SuastawanNo ratings yet
- Chapter 5 - Demand Estimation - Farrukh Wazir Khan - Fall22Document22 pagesChapter 5 - Demand Estimation - Farrukh Wazir Khan - Fall22IFRA AFZALNo ratings yet
- Kul 6 - Bias Dan Confounding Dalam EpidemiologiDocument52 pagesKul 6 - Bias Dan Confounding Dalam EpidemiologibenzabensaaNo ratings yet
- MCQDocument2 pagesMCQEngr Mujahid IqbalNo ratings yet
- SamplingDocument17 pagesSamplingManika GuptaNo ratings yet
- Lesson 1 Basic StatisticsDocument7 pagesLesson 1 Basic StatisticsRoxette Turingan TalosigNo ratings yet
- Impact Factor: Formula For CalculationDocument4 pagesImpact Factor: Formula For CalculationTamoor TariqNo ratings yet
- Practical Research 1 Quarter 1 - Module 4: Quantitative and Qualitative ResearchDocument13 pagesPractical Research 1 Quarter 1 - Module 4: Quantitative and Qualitative ResearchMark Allen LabasanNo ratings yet
- NTA JEE 2024 - 27 29 30 31 Jan 1st Feb 2024Document42 pagesNTA JEE 2024 - 27 29 30 31 Jan 1st Feb 2024manivignesh130407No ratings yet
- Mooney Problem Check ListDocument5 pagesMooney Problem Check ListAman ZahraNo ratings yet
- This Content Downloaded From 118.71.190.165 On Tue, 16 Aug 2022 15:31:50 UTCDocument15 pagesThis Content Downloaded From 118.71.190.165 On Tue, 16 Aug 2022 15:31:50 UTCseconbbNo ratings yet
- Testing of HypothesisDocument37 pagesTesting of Hypothesisabhinav jangirNo ratings yet
- Test - Random NumbersDocument47 pagesTest - Random NumbersYumeNo ratings yet
- Swati+B WaterManagementSystem ManalotoCastillo ALDocument5 pagesSwati+B WaterManagementSystem ManalotoCastillo ALEthan OuroNo ratings yet
- A Dream of A Retirement - The Longitudinal ExperiencesDocument21 pagesA Dream of A Retirement - The Longitudinal Experiences201900856No ratings yet
- Additional RRL WoohooDocument7 pagesAdditional RRL Woohoomitzi lorillaNo ratings yet
- A Comparative Study of Data Splitting Algorithms For Machine Learning Model SelectionDocument29 pagesA Comparative Study of Data Splitting Algorithms For Machine Learning Model SelectionELIANENo ratings yet
- Chapter 2. GeES 3026 Geography and Environmental Studies 2022Document49 pagesChapter 2. GeES 3026 Geography and Environmental Studies 2022moges lakeNo ratings yet
- 2019 Jan Assignment ARMDocument1 page2019 Jan Assignment ARMtinuvalsapaulNo ratings yet
- Research Design Canvas: Name: Title of ThesisDocument2 pagesResearch Design Canvas: Name: Title of Thesisaswar teknikNo ratings yet
- Research Paper Procedure ExampleDocument6 pagesResearch Paper Procedure Examplegsrkoxplg100% (1)
- SPIR SSPA Foundations of Statistical Analysis 2022Document2 pagesSPIR SSPA Foundations of Statistical Analysis 2022foxNo ratings yet