Download as pdf or txt
You might also like
- Bda - Unit 2Document56 pagesBda - Unit 2Kajal VaniyaNo ratings yet
- Exp3_BDI_60004200124Document5 pagesExp3_BDI_60004200124neelgabani69No ratings yet
- Unit-Iv CC&BD CS71Document148 pagesUnit-Iv CC&BD CS71HaelNo ratings yet
- 3 HadoopDocument40 pages3 HadoopBoby SharmaNo ratings yet
- Module-2 PPT-1Document126 pagesModule-2 PPT-1Lahari bilimaleNo ratings yet
- BigData Unit 2Document56 pagesBigData Unit 2Ravi YadavNo ratings yet
- Unit 3.1Document88 pagesUnit 3.1Awadhesh MauryaNo ratings yet
- Business Intelligence & Big Data Analytics-CSE3124YDocument26 pagesBusiness Intelligence & Big Data Analytics-CSE3124YsplokbovNo ratings yet
- Unit IIIDocument86 pagesUnit IIIFarhan SjNo ratings yet
- Data Storage Data Processing: Hadoop Distributed File System (HDFS) MapreduceDocument35 pagesData Storage Data Processing: Hadoop Distributed File System (HDFS) MapreduceSUDHEER REDDYNo ratings yet
- Unit - IIDocument64 pagesUnit - IIpraneelp2000No ratings yet
- Bda Summer 2022 SolutionDocument30 pagesBda Summer 2022 SolutionVivekNo ratings yet
- Introduction To HadoopDocument52 pagesIntroduction To Hadoopanytingac1No ratings yet
- SEN-762 Advanced Big Data AnalyticsDocument39 pagesSEN-762 Advanced Big Data AnalyticsبالیراجپوتNo ratings yet
- Unit II Big Data AnalyticsDocument11 pagesUnit II Big Data Analyticsbeelogger4321No ratings yet
- BDA - Unit-2Document24 pagesBDA - Unit-2Aishwarya RayasamNo ratings yet
- Introduction To HadoopDocument5 pagesIntroduction To HadoopHanumanthu GouthamiNo ratings yet
- HDFSDocument13 pagesHDFSkannyNo ratings yet
- BDA Lab Assignment 2Document18 pagesBDA Lab Assignment 2parth shahNo ratings yet
- BDA Lab Assignment 1 PDFDocument20 pagesBDA Lab Assignment 1 PDFparth shahNo ratings yet
- Bda Lab 1Document9 pagesBda Lab 1Mohit GangwaniNo ratings yet
- CC Unit 5Document43 pagesCC Unit 5prassadyashwinNo ratings yet
- Introduction To Big Data and HadoopDocument29 pagesIntroduction To Big Data and HadoopManoj K Upadhyaya100% (1)
- Chapter 4_Hadoop EcosystemDocument24 pagesChapter 4_Hadoop EcosystemAbhishek NazareNo ratings yet
- Unit IVDocument65 pagesUnit IVRaghavendra Vithal GoudNo ratings yet
- Unit-2 HadoopDocument16 pagesUnit-2 Hadoopabhaypratapverma6969No ratings yet
- HDFS ArchitectureDocument47 pagesHDFS Architecturekrishan GoyalNo ratings yet
- DSBDA ORAL Question BankDocument6 pagesDSBDA ORAL Question BankSUnny100% (1)
- BD Unit-IIINotesDocument17 pagesBD Unit-IIINoteskhushitikoo.workNo ratings yet
- HadoopDocument71 pagesHadoopouadaouiamine2No ratings yet
- Os BittuDocument10 pagesOs BittuVishwa MoorthyNo ratings yet
- Hadoop ISE 2Document25 pagesHadoop ISE 2SHREENIWAS LAXMANRAO CHATENo ratings yet
- Hadoop Distributed File System: Presented by Mohammad Sufiyan Nagaraju Kola Prudhvi Krishna KamireddyDocument17 pagesHadoop Distributed File System: Presented by Mohammad Sufiyan Nagaraju Kola Prudhvi Krishna KamireddySufiyan MohammadNo ratings yet
- Hadoop File SystemDocument2 pagesHadoop File SystemAradhana HingneNo ratings yet
- Cloud ComputingDocument19 pagesCloud ComputingAfia FaryadNo ratings yet
- BDA 3rd Unit QBDocument4 pagesBDA 3rd Unit QBSachin MahaleNo ratings yet
- HADOOPDocument40 pagesHADOOPsaadiaiftikhar123No ratings yet
- Unit-2 Hadoop HDFS HadoopecosystemDocument25 pagesUnit-2 Hadoop HDFS Hadoopecosystemsisodiyaa853No ratings yet
- Hadoop Building BlocksDocument30 pagesHadoop Building BlocksKavyaNo ratings yet
- UntitledDocument37 pagesUntitledashaNo ratings yet
- BFS U2Document17 pagesBFS U2Durga BishtNo ratings yet
- Unit II Big DataDocument27 pagesUnit II Big Datarohitmarale77No ratings yet
- Hadoop and Java Ques - AnsDocument222 pagesHadoop and Java Ques - AnsraviNo ratings yet
- BDA NotesDocument25 pagesBDA Notesmrudula.sbNo ratings yet
- Jump Start With Hadoop Getting Started WDocument16 pagesJump Start With Hadoop Getting Started Wsatish.sathya.a2012No ratings yet
- UNIT 3 HDFS, Hadoop Environment Part 1Document9 pagesUNIT 3 HDFS, Hadoop Environment Part 1works8606No ratings yet
- Unit 1 Haoop ArchitectureDocument26 pagesUnit 1 Haoop ArchitectureAnirudh PrakashNo ratings yet
- Big Data Analytics Lab ExperimentsDocument16 pagesBig Data Analytics Lab ExperimentsKiran alex ChallagiriNo ratings yet
- Hadoop With PythonDocument71 pagesHadoop With PythonCarlosEduardoC.daSilva100% (5)
- Module 1 PDFDocument42 pagesModule 1 PDFM YaseenNo ratings yet
- BigData Hadoop Lesson03Document48 pagesBigData Hadoop Lesson03usmanziaibianNo ratings yet
- Hadoop Distributed File SystemDocument3 pagesHadoop Distributed File SystemAkhila ShajiNo ratings yet
- Experiment No 1Document13 pagesExperiment No 1Aman JainNo ratings yet
- U-2 P-1Document38 pagesU-2 P-1Domakonda NehaNo ratings yet
- Hadoop OverviewDocument16 pagesHadoop OverviewSunil D Patil100% (1)
- Bda Exp 1Document6 pagesBda Exp 1Raj mehtaNo ratings yet
- Unit-3 (HDFS)Document59 pagesUnit-3 (HDFS)tripathineeharikaNo ratings yet
- Unit 3Document61 pagesUnit 3Ramstage TestingNo ratings yet
- Hadoop Interview1Document27 pagesHadoop Interview1paramreddy2000No ratings yet
- Tableau CalculationsDocument52 pagesTableau Calculationssowjanya kandukuriNo ratings yet
- HadoopDocument23 pagesHadoopsowjanya kandukuriNo ratings yet
- HDFS - RackawarenessDocument21 pagesHDFS - Rackawarenesssowjanya kandukuriNo ratings yet
- Big Data AnalyticsDocument16 pagesBig Data Analyticssowjanya kandukuriNo ratings yet
- Apache Spark PDFDocument34 pagesApache Spark PDFsowjanya kandukuriNo ratings yet
- GST BasicsDocument11 pagesGST Basicssowjanya kandukuriNo ratings yet
- Amendents in Companys Act 2013Document45 pagesAmendents in Companys Act 2013sowjanya kandukuriNo ratings yet
- Sale of Goods ActDocument10 pagesSale of Goods Actsowjanya kandukuriNo ratings yet
- New Comapany Act 2013Document30 pagesNew Comapany Act 2013sowjanya kandukuriNo ratings yet
- Sas Interview QuestionDocument68 pagesSas Interview QuestionNagesh Khandare0% (1)
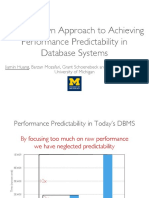
- A Top-Down Approach To Achieving Performance Predictability in Database SystemsDocument47 pagesA Top-Down Approach To Achieving Performance Predictability in Database SystemsvisaobuonNo ratings yet
- 04 - Oracle Reports Developer 10g Build ReportsDocument2 pages04 - Oracle Reports Developer 10g Build ReportsNabileNassimNo ratings yet
- XPP A DocDocument142 pagesXPP A DocNik20132013No ratings yet
- ADSODocument8 pagesADSOMohan Chand Reddy ANo ratings yet
- Canteen Management SystemDocument9 pagesCanteen Management Systemaddy63% (8)
- Javeria Ismail (20) Database MCQsDocument3 pagesJaveria Ismail (20) Database MCQsMehwish ShabbirNo ratings yet
- Unit No.4 Parallel DatabaseDocument32 pagesUnit No.4 Parallel DatabasePadre BhojNo ratings yet
- As e Config UnixDocument134 pagesAs e Config UnixAnonymous YDmrNZehNTNo ratings yet
- Database CosmeticsDocument33 pagesDatabase CosmeticsOkieNo ratings yet
- Pgdca 103Document5 pagesPgdca 103drbhaveshNo ratings yet
- SQL Basics Cheat Sheet A4Document2 pagesSQL Basics Cheat Sheet A4Maurizio RosaNo ratings yet
- Delphi Getting Started With SQL Part 1 PDFDocument6 pagesDelphi Getting Started With SQL Part 1 PDFnagat4rNo ratings yet
- TN Appsvr142 How To Query A SQL Database and Display in DataGrid View in Archestra Graphic - InSource KnowledgeCenterDocument9 pagesTN Appsvr142 How To Query A SQL Database and Display in DataGrid View in Archestra Graphic - InSource KnowledgeCenterTaleb EajalNo ratings yet
- Quick Reference BimlExtensionsDocument3 pagesQuick Reference BimlExtensionsİbrahim SezenNo ratings yet
- St. Rita of Cascia 2023 St. Paul University PhilippinesDocument9 pagesSt. Rita of Cascia 2023 St. Paul University PhilippinesAaron ConstantinoNo ratings yet
- XII MS Computer Science PB-1 (2023-24)Document9 pagesXII MS Computer Science PB-1 (2023-24)ujjwaldixit9452No ratings yet
- Validation Based ProtocolDocument11 pagesValidation Based Protocol-Nikhil BhatiaNo ratings yet
- (Java Database Connectivity) : Why Use JDBC?Document24 pages(Java Database Connectivity) : Why Use JDBC?AVANI SINGHNo ratings yet
- Windows System CallsDocument4 pagesWindows System Callsshivani porwalNo ratings yet
- OAT - Unit 5 MS AccessDocument15 pagesOAT - Unit 5 MS Accessshivam ashishNo ratings yet
- DBBL PO (Software) Question PatternDocument3 pagesDBBL PO (Software) Question PatternTazwar MohammedNo ratings yet
- TP - SAP Flight Data ModelDocument5 pagesTP - SAP Flight Data ModelMohamed CherrakNo ratings yet
- Introduction To DatabasesDocument37 pagesIntroduction To DatabasesADITYA SINGHNo ratings yet
- Ee PDF 2021-Jun-30 by Parker 66q VceDocument9 pagesEe PDF 2021-Jun-30 by Parker 66q VcejowbrowNo ratings yet
- 2/A.P1 Explain How The Features of A Relational Database Are Used For Database ManagementDocument8 pages2/A.P1 Explain How The Features of A Relational Database Are Used For Database ManagementBonzowoNo ratings yet
- Best Practices For Database SecurityDocument12 pagesBest Practices For Database SecurityAbdullah S. Ben SaeedNo ratings yet
- Hive PresentationDocument18 pagesHive PresentationVenkatesh NarisettyNo ratings yet
- Data Analytics RoadmapDocument15 pagesData Analytics RoadmapcoolsparkofficialNo ratings yet
- Database ManagementDocument14 pagesDatabase ManagementCj AntonioNo ratings yet