Download as pdf or txt
You might also like
- Hoffman and Kunze Solution ManualDocument107 pagesHoffman and Kunze Solution ManualKANTHAVEL T100% (1)
- 3Document48 pages3Mohanad KadhimNo ratings yet
- Week 3 NotesDocument10 pagesWeek 3 Notessandhiya sunainaNo ratings yet
- Incorrectly.: IntervalsDocument7 pagesIncorrectly.: IntervalsUdbhav DikshitNo ratings yet
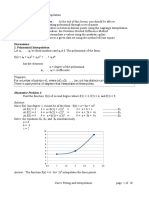
- M5. Curve Fitting and InterpolationDocument10 pagesM5. Curve Fitting and Interpolationaisen agustinNo ratings yet
- RESONANCE Equations For PreRmoDocument36 pagesRESONANCE Equations For PreRmoAyush KumarNo ratings yet
- MA107 Tutorial-2Document2 pagesMA107 Tutorial-2ayushNo ratings yet
- MMT 007Document5 pagesMMT 007romeoahmed687No ratings yet
- Homework 9: Eecs 16B Designing Information Devices and Systems II Spring 2018 J. Roychowdhury and M. MaharbizDocument12 pagesHomework 9: Eecs 16B Designing Information Devices and Systems II Spring 2018 J. Roychowdhury and M. MaharbizPuru PahujaNo ratings yet
- Modeling of Modified Fourier Technique For Solving Separable Non Linear Programming ProblemDocument13 pagesModeling of Modified Fourier Technique For Solving Separable Non Linear Programming ProblemKISHAN SINGHNo ratings yet
- Special FunctionDocument3 pagesSpecial FunctionHarshit Kumar SengarNo ratings yet
- Chapter 3Document20 pagesChapter 3Omed. HNo ratings yet
- Partial FractionsDocument6 pagesPartial FractionsEmmanuel MartinsNo ratings yet
- PDFDocument66 pagesPDFgajaNo ratings yet
- 2.quadratic EquationsDocument17 pages2.quadratic EquationsHarith HanifNo ratings yet
- Quadratic EquationsDocument19 pagesQuadratic EquationsLoh Chee WeiNo ratings yet
- 2024 Tutorial 1 Graphing Techniques I Level 0 (Solutions)Document5 pages2024 Tutorial 1 Graphing Techniques I Level 0 (Solutions)afreenazraa2007No ratings yet
- Practice Exam3 21b SolDocument6 pagesPractice Exam3 21b SolUmer Iftikhar AhmedNo ratings yet
- Interpolation - Introduction: NTH n+1Document51 pagesInterpolation - Introduction: NTH n+1atenhyunaeNo ratings yet
- Function Approximation, Interpolation, and Curve Fitting PDFDocument53 pagesFunction Approximation, Interpolation, and Curve Fitting PDFMikhail Tabucal100% (1)
- Function Approximation, Interpolation, and Curve FittingDocument53 pagesFunction Approximation, Interpolation, and Curve FittingAlexis Bryan RiveraNo ratings yet
- Tutorial-1 (Questions-DE)Document2 pagesTutorial-1 (Questions-DE)Ajay ChoudharyNo ratings yet
- GATE Electrical 2015 01 February 07 Forenoon Session Converted 2 1Document75 pagesGATE Electrical 2015 01 February 07 Forenoon Session Converted 2 1Abhinav KumarNo ratings yet
- (Chapter 3) Finite Difference MethodDocument10 pages(Chapter 3) Finite Difference MethodYen PengNo ratings yet
- Politecnico Di Torino: Bridging Course in Mathematics Sheet 1 PolynomialsDocument10 pagesPolitecnico Di Torino: Bridging Course in Mathematics Sheet 1 PolynomialsJuan Luis GonzalezNo ratings yet
- Chapter 5 Linear ProgrammingDocument63 pagesChapter 5 Linear ProgrammingViệt Minh ĐoànNo ratings yet
- Quardatic Equation-02-Solved ExamDocument14 pagesQuardatic Equation-02-Solved ExamRaju SinghNo ratings yet
- Lab 4 Newton Divided Difference Lagrange Interpolation: ObjectivesDocument9 pagesLab 4 Newton Divided Difference Lagrange Interpolation: ObjectivesAhmed AliNo ratings yet
- Quadratic EquationsDocument18 pagesQuadratic EquationsErwani KamaruddinNo ratings yet
- Linear InterpolationDocument4 pagesLinear InterpolationPrince Takyi ArthurNo ratings yet
- MIDTERMDocument12 pagesMIDTERMMarshall james G. RamirezNo ratings yet
- MA2020 - Sheet - 4 - 2024Document2 pagesMA2020 - Sheet - 4 - 2024Harshvardhan MohiteNo ratings yet
- C1C2 Revision NotesDocument12 pagesC1C2 Revision NotesWillMeadNo ratings yet
- Example: Minimizef (X) 2 X: 11 21 12 22 1 N 2 N 11 21 12 22 1 N 2 NDocument7 pagesExample: Minimizef (X) 2 X: 11 21 12 22 1 N 2 N 11 21 12 22 1 N 2 Nejg ketselaNo ratings yet
- Assignment 8: Applications of Differentiation Page 27Document8 pagesAssignment 8: Applications of Differentiation Page 27YONGCHENG LIUNo ratings yet
- 121 0Document4 pages121 0Taesoo LeeNo ratings yet
- Exercise Sheet 4Document4 pagesExercise Sheet 4Đỗ Xuân ViệtNo ratings yet
- Midterm 17-18Document2 pagesMidterm 17-18api-253679034No ratings yet
- Unit III Maths 3Document53 pagesUnit III Maths 3gkk001No ratings yet
- Grade 11 Mathematics Social ScienceDocument9 pagesGrade 11 Mathematics Social ScienceKamil AliNo ratings yet
- MPI 2324 hw6Document2 pagesMPI 2324 hw6toby121802No ratings yet
- DEMA0304-Lista2 1Document1 pageDEMA0304-Lista2 1Hadassa PereiraNo ratings yet
- MTL101-Tutorial Sheet 8Document4 pagesMTL101-Tutorial Sheet 8jayadangoliaNo ratings yet
- Differential EquationsDocument3 pagesDifferential Equationsme21b002No ratings yet
- MAS 201 Spring 2021 (CD) Differential Equations and ApplicationsDocument23 pagesMAS 201 Spring 2021 (CD) Differential Equations and ApplicationsBlue horseNo ratings yet
- Solutions To Selected Exercises: N n+1 I N I I n+1 N N n+1Document20 pagesSolutions To Selected Exercises: N n+1 I N I I n+1 N N n+1Ana AliceNo ratings yet
- GATE Civil 2021 February 10 230PM Converted 1 1Document42 pagesGATE Civil 2021 February 10 230PM Converted 1 1anurag mauryaNo ratings yet
- Assignment Sheet 1 MA2020 Differential Equations (July - November 2016)Document1 pageAssignment Sheet 1 MA2020 Differential Equations (July - November 2016)Siddharth NathanNo ratings yet
- UPSC Civil Services Main 1985 - Mathematics Calculus: Sunder LalDocument5 pagesUPSC Civil Services Main 1985 - Mathematics Calculus: Sunder Lalsayhigaurav07No ratings yet
- InterpolationDocument51 pagesInterpolationMuddys007No ratings yet
- Jinx Katana MA-214-HW2Document3 pagesJinx Katana MA-214-HW2Sarah WiseNo ratings yet
- 2233 mt1 S99sDocument5 pages2233 mt1 S99sAkoh C Josh ÜNo ratings yet
- Week 3 Practice Assignment SolutionDocument34 pagesWeek 3 Practice Assignment Solutionaadityajha675No ratings yet
- Curve Interpolation. Newton's Divided Differences. Lagrange PolynomialsDocument4 pagesCurve Interpolation. Newton's Divided Differences. Lagrange PolynomialsAhmet GelisliNo ratings yet
- Fun, ITFDocument91 pagesFun, ITFVijay PrakashNo ratings yet
- Chapter 40 - By-KamalDocument8 pagesChapter 40 - By-Kamalقاسم علاوNo ratings yet
- Mathematics For Economics and Finance: January 2016 Exam SolutionDocument11 pagesMathematics For Economics and Finance: January 2016 Exam SolutionjeanboncruNo ratings yet
- Mathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsFrom EverandMathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsNo ratings yet