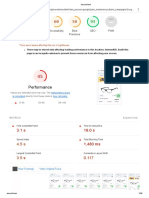
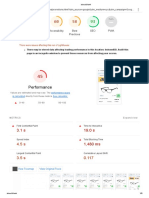
Download as pdf or txt
You might also like
- Machine Learning Lab Manual 06Document8 pagesMachine Learning Lab Manual 06Raheel Aslam100% (1)
- Experiment No.: 9: T. Y. B. Tech (CSE) - II Subject: Open Source Lab-IIDocument4 pagesExperiment No.: 9: T. Y. B. Tech (CSE) - II Subject: Open Source Lab-IIASHISH MALINo ratings yet
- Feature Selection Techniques in ML With Python-1Document7 pagesFeature Selection Techniques in ML With Python-1Дхиа ЕддинеNo ratings yet
- The Art of Finding The Best Features For Machine Learning - by Rebecca Vickery - Towards Data ScienceDocument14 pagesThe Art of Finding The Best Features For Machine Learning - by Rebecca Vickery - Towards Data ScienceHamdan Gani, S.Kom., MTNo ratings yet
- AAM 1st Unit QBDocument4 pagesAAM 1st Unit QBSachin MahaleNo ratings yet
- Scikit LearnDocument17 pagesScikit LearnRRNo ratings yet
- Scikit - Notes MLDocument12 pagesScikit - Notes MLVulli Leela Venkata Phanindra100% (1)
- 11.feature Selection, ExtractionDocument38 pages11.feature Selection, ExtractionLUV ARORANo ratings yet
- ML - Expt 7Document6 pagesML - Expt 7mitali.201433201No ratings yet
- Machine Learning Program 4 (Mohan)Document7 pagesMachine Learning Program 4 (Mohan)21EE076 NIDHINNo ratings yet
- The Implication of Statistical Analysis and Feature Engineering For Model Building Using Machine Learning AlgorithmsDocument11 pagesThe Implication of Statistical Analysis and Feature Engineering For Model Building Using Machine Learning AlgorithmsijcsesNo ratings yet
- Machine Learning Lab: Raheel Aslam (74-FET/BSEE/F16)Document3 pagesMachine Learning Lab: Raheel Aslam (74-FET/BSEE/F16)Raheel AslamNo ratings yet
- Unit 1 Machine LearningDocument10 pagesUnit 1 Machine Learningsahugungun76No ratings yet
- Coe ProjectsDocument7 pagesCoe ProjectstApIsHNo ratings yet
- AI Phase4Document11 pagesAI Phase4techusama4No ratings yet
- Final Project ImplementationDocument3 pagesFinal Project Implementationmail.information0101No ratings yet
- TD2345Document3 pagesTD2345ashitaka667No ratings yet
- Introduction To ScikitDocument9 pagesIntroduction To ScikitASHUTOSH TRIVEDINo ratings yet
- Machine Learning Part: Domain OverviewDocument20 pagesMachine Learning Part: Domain Overviewsurya prakashNo ratings yet
- Lab Manual-ANNDocument7 pagesLab Manual-ANNfaizan majidNo ratings yet
- 10 PDFDocument12 pages10 PDFAishwarya DasNo ratings yet
- Ishan Aiml 1Document3 pagesIshan Aiml 1Ishan AhujaNo ratings yet
- T3 BdaDocument27 pagesT3 BdaChirag JainNo ratings yet
- ML FinalDocument34 pagesML Final4023 KeerthanaNo ratings yet
- ML Activity KalyanDocument21 pagesML Activity Kalyanaishwarya kalyanNo ratings yet
- PatternDocument1 pagePatternahmadkhalilNo ratings yet
- Blue Futuristic Technology PresentationDocument19 pagesBlue Futuristic Technology PresentationnikhilmavuruNo ratings yet
- Lab #3Document12 pagesLab #3Akriti NigamNo ratings yet
- Machine Learning NotesDocument6 pagesMachine Learning NotesNikhita NairNo ratings yet
- Machine Learning Lab ManualDocument23 pagesMachine Learning Lab ManualPrakash JeevaNo ratings yet
- Machine Learning For Data ScienceDocument20 pagesMachine Learning For Data SciencepraveenakgNo ratings yet
- PRACTICAL5Document23 pagesPRACTICAL5thundergamerz403No ratings yet
- Ranking Features Based On Predictive Power - Importance of The Class LabelsDocument11 pagesRanking Features Based On Predictive Power - Importance of The Class LabelsJuanNo ratings yet
- Basics Machine LearningDocument6 pagesBasics Machine LearningSajid Hussain SNo ratings yet
- ML - Practical FileDocument15 pagesML - Practical FileJatin MathurNo ratings yet
- Feature SelectionDocument8 pagesFeature SelectionAbinaya CNo ratings yet
- Deep Learning VocabularyDocument6 pagesDeep Learning Vocabularyjaffar bikatNo ratings yet
- Machine Learning Project Car Price Prediction AlgorithmDocument4 pagesMachine Learning Project Car Price Prediction AlgorithmRuqaiya AliNo ratings yet
- 21 Machine Learning Using Scikit Learn Ipynb Colaboratory PDFDocument23 pages21 Machine Learning Using Scikit Learn Ipynb Colaboratory PDFJagadeesh Kumar100% (1)
- DM - MOD - 1 Part IIIDocument12 pagesDM - MOD - 1 Part IIIsandrarajuofficialNo ratings yet
- 1.4 Feature SelectionDocument12 pages1.4 Feature SelectionmohamedNo ratings yet
- 6 - Steps of The Classification Algorithm in Supervised LearningDocument15 pages6 - Steps of The Classification Algorithm in Supervised LearningRajendra ChadalawadaNo ratings yet
- Kabir Data Preprocessing PythonDocument14 pagesKabir Data Preprocessing PythonEl Arbi Abdellaoui AlaouiNo ratings yet
- Chapter 11Document19 pagesChapter 11ramarajuNo ratings yet
- BigData Assessment2 26230605Document14 pagesBigData Assessment2 26230605abaid choughtaiNo ratings yet
- STIKDocument5 pagesSTIKabebawNo ratings yet
- CH 4Document106 pagesCH 4Abebe BekeleNo ratings yet
- ICT-4202, DIP Lab Manual - 8Document20 pagesICT-4202, DIP Lab Manual - 8any.pc2500No ratings yet
- Whole ML PDF 1614408656Document214 pagesWhole ML PDF 1614408656Kshatrapati Singh100% (1)
- Data PrepDocument5 pagesData PrepHimanshu ShrivastavaNo ratings yet
- Learning With Python: TOPIC: ML AlgorithmsDocument32 pagesLearning With Python: TOPIC: ML AlgorithmsMukul SharmaNo ratings yet
- ML Unit 1Document27 pagesML Unit 1SUJATA SONWANENo ratings yet
- An Introduction To Feature SelectionDocument45 pagesAn Introduction To Feature SelectionprediatechNo ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- Deep Learning For Credit Risk 1713932406Document13 pagesDeep Learning For Credit Risk 1713932406Irshita KhirvatNo ratings yet
- Exp 4Document10 pagesExp 4jayNo ratings yet
- Machine LearningDocument1 pageMachine LearningabellorodelcuteNo ratings yet
- WEKA Lab ManualDocument107 pagesWEKA Lab ManualRamesh Kumar100% (1)
- Unit - 3 Feature EngineeringDocument29 pagesUnit - 3 Feature EngineeringSoumya MishraNo ratings yet
- DATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSFrom EverandDATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSNo ratings yet
- EXTRADocument1 pageEXTRAshekh dhrupalNo ratings yet
- 777 PDFDocument1 page777 PDFshekh dhrupalNo ratings yet
- E-Ticket/Reservation Voucher: G193486127 1631RJTBVNAC45 Ac LuxuryDocument1 pageE-Ticket/Reservation Voucher: G193486127 1631RJTBVNAC45 Ac Luxuryshekh dhrupalNo ratings yet
- E-Ticket/Reservation Voucher: G316764176 Rajkot Busport Ac LuxuryDocument1 pageE-Ticket/Reservation Voucher: G316764176 Rajkot Busport Ac Luxuryshekh dhrupalNo ratings yet
- E-Ticket/Reservation Voucher: G1647861354 1631RJTBVNAC45 Ac Luxury UDocument1 pageE-Ticket/Reservation Voucher: G1647861354 1631RJTBVNAC45 Ac Luxury Ushekh dhrupalNo ratings yet
- Lenskat ExpandedDocument39 pagesLenskat Expandedshekh dhrupalNo ratings yet
- IT DepartmentDocument1 pageIT Departmentshekh dhrupalNo ratings yet
- Lenskart SummaryDocument6 pagesLenskart Summaryshekh dhrupalNo ratings yet
- Zomato SummaryDocument5 pagesZomato Summaryshekh dhrupalNo ratings yet