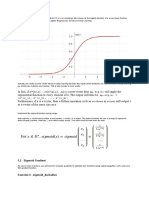
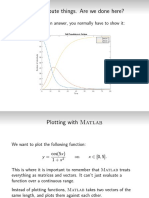
Download as pdf or txt
You might also like
- Microsoft Excel (General) Test - TestGorillaDocument10 pagesMicrosoft Excel (General) Test - TestGorillaHar Ish20% (5)
- Design and Analysis of Algorithm Question BankDocument15 pagesDesign and Analysis of Algorithm Question BankGeo ThaliathNo ratings yet
- Daikin VRV Handbook - OHUS08-1FCU-bDocument72 pagesDaikin VRV Handbook - OHUS08-1FCU-bthanhthuan100% (1)
- Lab2 Linear RegressionDocument18 pagesLab2 Linear RegressionJuan Zarate100% (1)
- Homework 2: Lasso Regression: 1.1 Data Set and Programming Problem OverviewDocument11 pagesHomework 2: Lasso Regression: 1.1 Data Set and Programming Problem OverviewMayur AgrawalNo ratings yet
- Linear Regression - Numpy and SklearnDocument7 pagesLinear Regression - Numpy and SklearnArala FolaNo ratings yet
- Exercise 03Document5 pagesExercise 03gfjggNo ratings yet
- MultivariateRGGobi PDFDocument60 pagesMultivariateRGGobi PDFDiogo BarriosNo ratings yet
- Experiment 2 v2Document10 pagesExperiment 2 v2saeed wedyanNo ratings yet
- Python Basics NympyDocument5 pagesPython Basics NympyikramNo ratings yet
- Instruction Assignment9Document3 pagesInstruction Assignment9Nurbek NussipbekovNo ratings yet
- 1.1 ID5059 1.2 Tom Kelsey - Jan 2021: February 15, 2021Document43 pages1.1 ID5059 1.2 Tom Kelsey - Jan 2021: February 15, 2021Tev WallaceNo ratings yet
- Lab NN KNN SVMDocument13 pagesLab NN KNN SVMmaaian.iancuNo ratings yet
- NumpyDocument10 pagesNumpyXY ZWNo ratings yet
- NN MTH404Document9 pagesNN MTH404mail.information0101No ratings yet
- Matlab Review PDFDocument19 pagesMatlab Review PDFMian HusnainNo ratings yet
- Problem Set 2: Working With Standard DrawDocument6 pagesProblem Set 2: Working With Standard Drawkajarban singhNo ratings yet
- Utf 8''week4Document15 pagesUtf 8''week4devendra416No ratings yet
- Curve Fitting With ScilabDocument8 pagesCurve Fitting With ScilabDiana NahielyNo ratings yet
- An Introduction To Matlab: Part 5Document5 pagesAn Introduction To Matlab: Part 5ayeshsekarNo ratings yet
- CmdieDocument8 pagesCmdieBeny AbdouNo ratings yet
- Hidden Markov Model - Implemented From Scratch - by Oleg Żero - Towards Data ScienceDocument31 pagesHidden Markov Model - Implemented From Scratch - by Oleg Żero - Towards Data SciencedroolingpandaNo ratings yet
- STA4026S 2021 - Continuous Assessment 2 Ver0.0 - 2021!09!29Document6 pagesSTA4026S 2021 - Continuous Assessment 2 Ver0.0 - 2021!09!29Millan ChibbaNo ratings yet
- KerasDocument3 pagesKerasmagas32862No ratings yet
- PythonfileDocument36 pagesPythonfilecollection58209No ratings yet
- CS 188 Introduction To Artificial Intelligence Fall 2017 Note 10 Neural Networks: MotivationDocument9 pagesCS 188 Introduction To Artificial Intelligence Fall 2017 Note 10 Neural Networks: MotivationEman JaffriNo ratings yet
- Linear Regression Using PythonDocument15 pagesLinear Regression Using PythonGnanarajNo ratings yet
- Structs Impl PRG LanDocument11 pagesStructs Impl PRG LanGoogle DocNo ratings yet
- Lab 08 - Data PreprocessingDocument9 pagesLab 08 - Data PreprocessingridaNo ratings yet
- Week 4: 2D Arrays and PlottingDocument25 pagesWeek 4: 2D Arrays and PlottingKaleab TekleNo ratings yet
- Maxbox Starter60 Machine LearningDocument8 pagesMaxbox Starter60 Machine LearningMax KleinerNo ratings yet
- # ELG 5255 Applied Machine Learning Fall 2020 # Assignment 3 (Multivariate Method)Document8 pages# ELG 5255 Applied Machine Learning Fall 2020 # Assignment 3 (Multivariate Method)raosahebNo ratings yet
- Solving Optimization Problems With JAX by Mazeyar Moeini The Startup MediumDocument9 pagesSolving Optimization Problems With JAX by Mazeyar Moeini The Startup MediumBjoern SchalteggerNo ratings yet
- Assignment 2Document4 pagesAssignment 210121011No ratings yet
- HW 7Document4 pagesHW 7adithya604No ratings yet
- ML Lab ManualDocument37 pagesML Lab Manualapekshapandekar01100% (1)
- Neural Lab 1Document5 pagesNeural Lab 1Bashar AsaadNo ratings yet
- HW 1Document8 pagesHW 1Mayur AgrawalNo ratings yet
- Matlab Slides IIIDocument26 pagesMatlab Slides IIIRicky LiunaNo ratings yet
- CS4740/5740 Introduction To NLP Fall 2017 Neural Language Models and ClassifiersDocument7 pagesCS4740/5740 Introduction To NLP Fall 2017 Neural Language Models and ClassifiersEdward LeeNo ratings yet
- Ps 4Document12 pagesPs 4Wassim AzzabiNo ratings yet
- Signal & Sytem Lab-Manval PDFDocument26 pagesSignal & Sytem Lab-Manval PDFAnonymous FEjtNQnNo ratings yet
- Exercise 03 RadonovIvan 5967988Document1 pageExercise 03 RadonovIvan 5967988ErikaNo ratings yet
- P 1Document3 pagesP 1Don QuixoteNo ratings yet
- MAE3456 - MEC3456 LAB 01: Due: 11:59PM (Sharp), Friday 12 March 2021 (End of Week 2)Document6 pagesMAE3456 - MEC3456 LAB 01: Due: 11:59PM (Sharp), Friday 12 March 2021 (End of Week 2)kainNo ratings yet
- Anomaly Detection - Problem MotivationDocument9 pagesAnomaly Detection - Problem MotivationmarcNo ratings yet
- Aula 4 (L) - Oggi La Tua Lezione È in PresenzaDocument11 pagesAula 4 (L) - Oggi La Tua Lezione È in PresenzaIlaria PapilloNo ratings yet
- CO3002/7002 Assignment 2: Question 1 (30 Marks)Document3 pagesCO3002/7002 Assignment 2: Question 1 (30 Marks)Rahul SharmaNo ratings yet
- S17aec cl05Document3 pagesS17aec cl05Khhg AgddsNo ratings yet
- 37 Using OctaveDocument13 pages37 Using Octavegrecatprep9045No ratings yet
- ML ImplementationDocument14 pagesML Implementationnoussayer mighriNo ratings yet
- cs188 sp23 Note25Document8 pagescs188 sp23 Note25sondosNo ratings yet
- Ex 3Document12 pagesEx 3Saurav ÅgarwalNo ratings yet
- Lab 2Document14 pagesLab 2Tahsin Zaman TalhaNo ratings yet
- MTH5120 Statistical Modelling I Tutorial 1Document3 pagesMTH5120 Statistical Modelling I Tutorial 1lassti hmNo ratings yet
- STA1007S Lab 6: Custom Functions: "Sample"Document6 pagesSTA1007S Lab 6: Custom Functions: "Sample"mlunguNo ratings yet
- ML Coursera Python AssignmentsDocument20 pagesML Coursera Python AssignmentsMNo ratings yet
- Ex 6Document16 pagesEx 6Pardhasaradhi NallamothuNo ratings yet
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- Automatic Differentiation Simons - Summer - School - Talk - August - 21stDocument65 pagesAutomatic Differentiation Simons - Summer - School - Talk - August - 21stBjoern SchalteggerNo ratings yet
- Solving Optimization Problems With JAX by Mazeyar Moeini The Startup MediumDocument9 pagesSolving Optimization Problems With JAX by Mazeyar Moeini The Startup MediumBjoern SchalteggerNo ratings yet
- Maxima WorkbookDocument279 pagesMaxima WorkbookBjoern SchalteggerNo ratings yet
- ELMER-Guide To FEM Simulations v03 PDFDocument53 pagesELMER-Guide To FEM Simulations v03 PDFBjoern SchalteggerNo ratings yet
- Symbolics - JL A Modern Computer Algebra System For A Modern LanguageDocument12 pagesSymbolics - JL A Modern Computer Algebra System For A Modern LanguageBjoern SchalteggerNo ratings yet
- The Slave Trade and The Jews by David Brion Davis - The New York Review of BooksDocument10 pagesThe Slave Trade and The Jews by David Brion Davis - The New York Review of BooksMatt Berkman100% (2)
- Engine Electrical SystemDocument57 pagesEngine Electrical SystemZatovonirina RazafindrainibeNo ratings yet
- Expokit: A Software Package For Computing Matrix ExponentialsDocument21 pagesExpokit: A Software Package For Computing Matrix ExponentialsAleksandarBukvaNo ratings yet
- Madison County ScoresDocument3 pagesMadison County ScoresMike BrownNo ratings yet
- A Task To Perform - Reading Comprehension - 1 ELAAROUB Abdellah IDSDDocument3 pagesA Task To Perform - Reading Comprehension - 1 ELAAROUB Abdellah IDSDZakaria NAJIBNo ratings yet
- KX Tga272lxsDocument74 pagesKX Tga272lxsAnonymous Lfgk6vygNo ratings yet
- Holacracy - The New Management System: October 2016Document11 pagesHolacracy - The New Management System: October 2016Alejandro VilladaNo ratings yet
- The Effect of Social Media Influencer On Brand Image, Self-Concept, and Purchase IntentionDocument14 pagesThe Effect of Social Media Influencer On Brand Image, Self-Concept, and Purchase IntentionLiza NoraNo ratings yet
- PSBRC Module 3 - Media Relations PowerpointDocument58 pagesPSBRC Module 3 - Media Relations PowerpointGlen LunaNo ratings yet
- Manifest Unit LCT MaiDocument2 pagesManifest Unit LCT Maiaanggunawan.awduNo ratings yet
- CC 110 Syllabus in Financial Management For Agri-Based Enterprises (F)Document11 pagesCC 110 Syllabus in Financial Management For Agri-Based Enterprises (F)Cesar Della33% (3)
- Finalised GSM OverviewDocument33 pagesFinalised GSM OverviewishanrajdorNo ratings yet
- ISR4321-V/K9 Datasheet: Quick SpecsDocument6 pagesISR4321-V/K9 Datasheet: Quick SpecsDjibril FayeNo ratings yet
- SVAN 956 User ManualDocument195 pagesSVAN 956 User Manualalin.butunoi865No ratings yet
- CurriculaDocument6 pagesCurriculaAngel ValentinNo ratings yet
- Airline PilotDocument3 pagesAirline PilotBtrs BtrstNo ratings yet
- Top Ten Questions About Land TrustsDocument17 pagesTop Ten Questions About Land TrustsRandy Hughes50% (2)
- Wealth Management ModuleDocument127 pagesWealth Management ModuleVAIBHAV BUNTY100% (3)
- Activity 1 For Lesson 5Document2 pagesActivity 1 For Lesson 5GUEVARRA EUNICE B.No ratings yet
- Peer Mentoring in A University Jazz Ensemble: by Andrew GoodrichDocument27 pagesPeer Mentoring in A University Jazz Ensemble: by Andrew GoodrichMatthew BelyeuNo ratings yet
- Project Report On Ulip & Mutual FundDocument55 pagesProject Report On Ulip & Mutual FundGovind BhakuniNo ratings yet
- Practical Guide To Securing Work From Anywhere Using Microsoft 365 Business PremiumDocument28 pagesPractical Guide To Securing Work From Anywhere Using Microsoft 365 Business PremiumPedro Palmeira RochaNo ratings yet
- The Management of Foreign Exchange RiskDocument97 pagesThe Management of Foreign Exchange RiskVajira Weerasena100% (1)
- ESG Media ListDocument4 pagesESG Media ListPoojaa ShirsatNo ratings yet
- LM Comandi Marzo 2022Document11 pagesLM Comandi Marzo 2022grazianonetNo ratings yet
- P-T-T Paths: (Type Text) (Type Text) (Type Text)Document8 pagesP-T-T Paths: (Type Text) (Type Text) (Type Text)Thirukumaran VenugopalNo ratings yet
- Ignition System: Engine Control (ECM)Document1 pageIgnition System: Engine Control (ECM)Rafael Alejandro ReyesNo ratings yet
- Issue #72Document84 pagesIssue #72baltazzar_90No ratings yet