Download as pdf or txt
You might also like
- Learning SD-WAN with Cisco: Transform Your Existing WAN Into a Cost-effective NetworkFrom EverandLearning SD-WAN with Cisco: Transform Your Existing WAN Into a Cost-effective NetworkNo ratings yet
- Meraki SD WanDocument35 pagesMeraki SD WanTadeu MeloNo ratings yet
- Assignment 2 Task C-D-EDocument9 pagesAssignment 2 Task C-D-ELone Grace Cuenca100% (1)
- Plant Design For Slurry HandlingDocument6 pagesPlant Design For Slurry HandlingJose BustosNo ratings yet
- Studi Kasus SCMDocument8 pagesStudi Kasus SCMMuflihul Khair0% (5)
- MT PPT2 - Switching Concepts and VLANsDocument52 pagesMT PPT2 - Switching Concepts and VLANsmj fullenteNo ratings yet
- Virtual Local Area NetworksDocument26 pagesVirtual Local Area Networksamar_mba10No ratings yet
- Virtual Local Area Networks: Varadarajan.5@osu - EduDocument19 pagesVirtual Local Area Networks: Varadarajan.5@osu - EduRahulDevNo ratings yet
- Networking For Virtualization: Deep DiveDocument7 pagesNetworking For Virtualization: Deep DiveAli TouseefNo ratings yet
- Transmission Algorithm For Video Streaming Over Cellular NetworksDocument17 pagesTransmission Algorithm For Video Streaming Over Cellular NetworksAyahna Ravi TennovNo ratings yet
- Switching Concepts, VLANs and Inter-VLAN RoutingDocument93 pagesSwitching Concepts, VLANs and Inter-VLAN RoutingMemo LOlNo ratings yet
- Transmission Algorithm For Video Streaming Over Cellular NetworksDocument17 pagesTransmission Algorithm For Video Streaming Over Cellular NetworksPhuong OtNo ratings yet
- 2 - Chapter TwoDocument31 pages2 - Chapter Twoeng.kerillous.samirNo ratings yet
- W AcronymsDocument4 pagesW AcronymsJessica a MillerNo ratings yet
- Unit1 VLAN VSANDocument63 pagesUnit1 VLAN VSANBhumika BiyaniNo ratings yet
- 5.1 Key Points of Wireless Coverage DeploymentDocument19 pages5.1 Key Points of Wireless Coverage Deploymentchristyan leonNo ratings yet
- Tutorial 9 TITLE: Implementation of Dynamic Tunnels: Kartikey Mandloi J028Document2 pagesTutorial 9 TITLE: Implementation of Dynamic Tunnels: Kartikey Mandloi J028HARSH MATHURNo ratings yet
- CNv6 Chapter6Document42 pagesCNv6 Chapter6Hannibal ImterNo ratings yet
- Meraki SD-WANDocument32 pagesMeraki SD-WANRaj Karan0% (1)
- NET301 Chapter6 QualityofServiceDocument42 pagesNET301 Chapter6 QualityofServiceKyla PinedaNo ratings yet
- Network Security: Hosted By: Ed-Lab Pakistan and Risk AssociatesDocument25 pagesNetwork Security: Hosted By: Ed-Lab Pakistan and Risk AssociatesHamzaZahidNo ratings yet
- Distributed Call Admission Control For Ad Hoc Networks: Shahrokh Valaee and Baochun LiDocument5 pagesDistributed Call Admission Control For Ad Hoc Networks: Shahrokh Valaee and Baochun Lijasneetk_1No ratings yet
- Module 2: Switching Concepts: Switching, Routing, and Wireless Essentials v7.0 (SRWE)Document14 pagesModule 2: Switching Concepts: Switching, Routing, and Wireless Essentials v7.0 (SRWE)jerwin dacumosNo ratings yet
- 3.1 MAC ProtocolDocument48 pages3.1 MAC ProtocolVENKATA SAI KRISHNA YAGANTINo ratings yet
- Cisco Datacenter Security: György Ács Security Consulting Systems Engineer 2016 JuneDocument38 pagesCisco Datacenter Security: György Ács Security Consulting Systems Engineer 2016 JuneVolvoxdjNo ratings yet
- CNv6 instructorPPT Chapter6Document44 pagesCNv6 instructorPPT Chapter6mohammedqundiNo ratings yet
- Unit 1 Continued 2Document59 pagesUnit 1 Continued 2Biraj RegmiNo ratings yet
- Net ch2Document61 pagesNet ch2Abdurehman B HasenNo ratings yet
- Asynchronous Transfer Mode Assignment No.1: Ques 1. Compare Various Switching ModelsDocument6 pagesAsynchronous Transfer Mode Assignment No.1: Ques 1. Compare Various Switching Modelsjkj2010No ratings yet
- Ds Wan Series inDocument9 pagesDs Wan Series inSujeet KumarNo ratings yet
- Unit 5 Mesh Networks Upto 802Document26 pagesUnit 5 Mesh Networks Upto 802pravi2010No ratings yet
- Chapter 5 Network TypesDocument33 pagesChapter 5 Network Typesبشار القدسيNo ratings yet
- Lecture 5 Vlan SanDocument59 pagesLecture 5 Vlan SanZeyRoX GamingNo ratings yet
- On The Price of Security in LargeDocument4 pagesOn The Price of Security in LargesathishNo ratings yet
- Module 2 - VLANs and VTPDocument38 pagesModule 2 - VLANs and VTPBinh Nguyen HuyNo ratings yet
- EN01 Data Center Network OverviewDocument63 pagesEN01 Data Center Network OverviewAlfi Triana MufidahNo ratings yet
- Slide 3Document32 pagesSlide 3leatherworld.z8No ratings yet
- ST PPT2-1 - Switching ConceptsDocument15 pagesST PPT2-1 - Switching Conceptsmj fullenteNo ratings yet
- 20-Storm ControlDocument9 pages20-Storm ControlKelvin YangNo ratings yet
- SM CAC Best PracticesDocument35 pagesSM CAC Best PracticesCarl CunninghamNo ratings yet
- Rajant SpecSheet Slipstream-041223Document2 pagesRajant SpecSheet Slipstream-041223javier.lopez.duranNo ratings yet
- (IJCST-V12I2P12) :A.Ashok KumarDocument9 pages(IJCST-V12I2P12) :A.Ashok Kumareditor1ijcstNo ratings yet
- Kratos DataDefender Network Packet Loss Protection Data SheetDocument2 pagesKratos DataDefender Network Packet Loss Protection Data SheetarzeszutNo ratings yet
- Unit 2cloudstack Architecture 3Document32 pagesUnit 2cloudstack Architecture 3Sahil Kumar GuptaNo ratings yet
- Ciena Waveserver - DSDocument2 pagesCiena Waveserver - DSrobert adamsNo ratings yet
- Itnet - Midterm ReviewerDocument15 pagesItnet - Midterm Reviewerandreajade.cawaya10No ratings yet
- Security Protocols For Wireless Sensor NetworkDocument39 pagesSecurity Protocols For Wireless Sensor NetworkChetan RanaNo ratings yet
- WAN Optimization FrameworkDocument40 pagesWAN Optimization FrameworkVinamra KumarNo ratings yet
- Network-Assisted Mobile Computing With Optimal Uplink Query ProcessingDocument16 pagesNetwork-Assisted Mobile Computing With Optimal Uplink Query ProcessingPonnu ANo ratings yet
- Virtual Local Area Network Technology and Applications: (VLAN)Document4 pagesVirtual Local Area Network Technology and Applications: (VLAN)ahedNo ratings yet
- 1b. Switching Concepts - Rev 2022Document15 pages1b. Switching Concepts - Rev 2022Rhesa FirmansyahNo ratings yet
- SD WanDocument4 pagesSD WanFernala Sejmen-BanjacNo ratings yet
- Module 2: Switching Concepts: Switching, Routing, and Wireless Essentials v7.0 (SRWE)Document17 pagesModule 2: Switching Concepts: Switching, Routing, and Wireless Essentials v7.0 (SRWE)Lama AhmadNo ratings yet
- Vsphere Challenge LabDocument4 pagesVsphere Challenge LabsivakumarNo ratings yet
- WAN TechnologiesDocument14 pagesWAN Technologiesrao raoNo ratings yet
- CSE423 Notes2Document7 pagesCSE423 Notes2Ranjith SKNo ratings yet
- 1.7 Switching DomainsDocument4 pages1.7 Switching DomainsSyifa FauziahNo ratings yet
- Brksan-2883 - 2018-1-15Document15 pagesBrksan-2883 - 2018-1-15anilNo ratings yet
- What Is SAN Zoning?: Hard Zoning Soft ZoningDocument10 pagesWhat Is SAN Zoning?: Hard Zoning Soft ZoningPabbathi Prabhakar0% (1)
- San Zoing-1Document3 pagesSan Zoing-1MadhuriNomulaNo ratings yet
- WLAN and PANDocument67 pagesWLAN and PANShashi Shekhar AzadNo ratings yet
- Data Encryption Best Practices For Edge EnvironmentsDocument7 pagesData Encryption Best Practices For Edge Environmentspk bsdkNo ratings yet
- DCIG - SvSAN - Vmw-Analyst-Comparison PDFDocument3 pagesDCIG - SvSAN - Vmw-Analyst-Comparison PDFpk bsdkNo ratings yet
- ESG Showcase StorMagic Apr 2020Document5 pagesESG Showcase StorMagic Apr 2020pk bsdkNo ratings yet
- 10th Marksheet PDFDocument1 page10th Marksheet PDFpk bsdkNo ratings yet
- Coursera ML Certificate T2LTUXAUCEQT PDFDocument1 pageCoursera ML Certificate T2LTUXAUCEQT PDFpk bsdkNo ratings yet
- Panel Features: Square-D Fabricator and Control Systems EnterpriseDocument1 pagePanel Features: Square-D Fabricator and Control Systems EnterpriseCallista CollectionsNo ratings yet
- Experiment 4 Turbine CharacteristicsDocument12 pagesExperiment 4 Turbine CharacteristicsChong Ru YinNo ratings yet
- P&Z Electronic (Dongguan) Co.,LtdDocument3 pagesP&Z Electronic (Dongguan) Co.,LtdTRMNo ratings yet
- ARANDANOSDocument5 pagesARANDANOSCarolinaNo ratings yet
- Research On Sustainable Development of Textile Industrial Clusters in The Process of GlobalizationDocument5 pagesResearch On Sustainable Development of Textile Industrial Clusters in The Process of GlobalizationSam AbdulNo ratings yet
- Turbodrain EnglDocument8 pagesTurbodrain EnglIonut BuzescuNo ratings yet
- Quinone-Based Molecular Electrochemistry and Their Contributions To Medicinal Chemistry: A Look at The Present and FutureDocument9 pagesQuinone-Based Molecular Electrochemistry and Their Contributions To Medicinal Chemistry: A Look at The Present and FutureSanti Osorio DiezNo ratings yet
- Covellite PDFDocument1 pageCovellite PDFRyoga RizkyNo ratings yet
- Full Download Strategies For Teaching Learners With Special Needs 11th Edition Polloway Test BankDocument36 pagesFull Download Strategies For Teaching Learners With Special Needs 11th Edition Polloway Test Banklevidelpnrr100% (30)
- Technical Data: Air ConditioningDocument17 pagesTechnical Data: Air ConditioningTomaž BajželjNo ratings yet
- Fil-Chin Engineering: To: Limketkai Attn: Mr. Eduard Oh Re: Heat ExchangerDocument6 pagesFil-Chin Engineering: To: Limketkai Attn: Mr. Eduard Oh Re: Heat ExchangerKeith Henrich M. ChuaNo ratings yet
- Daftar Harga 2021 (Abjad)Document9 pagesDaftar Harga 2021 (Abjad)Arahmaniansyah HenkzNo ratings yet
- Drop Tower MQP Final ReportDocument70 pagesDrop Tower MQP Final ReportFABIAN FIENGONo ratings yet
- EN ISO 13503-2 (2006) (E) CodifiedDocument8 pagesEN ISO 13503-2 (2006) (E) CodifiedEzgi PelitNo ratings yet
- Assignment2 NamocDocument5 pagesAssignment2 NamocHenry Darius NamocNo ratings yet
- RAS AQ DIYproteinskimmer ManualDocument8 pagesRAS AQ DIYproteinskimmer ManualBishri LatiffNo ratings yet
- Paper 2222Document16 pagesPaper 2222Abhijeet GholapNo ratings yet
- 2021 - 1 - Alternative Sampling Arrangement For Chemical Composition Tests For General Acceptance (GA) ApplicationDocument5 pages2021 - 1 - Alternative Sampling Arrangement For Chemical Composition Tests For General Acceptance (GA) Applicationkumshing88cwNo ratings yet
- Remedial Uas B.ing LM (Intani Julien Putri Xii Ipa 6)Document9 pagesRemedial Uas B.ing LM (Intani Julien Putri Xii Ipa 6)Intani JulienNo ratings yet
- 7.8.2 Example - Basic Column Control: Chapter 7 - C F I DDocument4 pages7.8.2 Example - Basic Column Control: Chapter 7 - C F I DnmulyonoNo ratings yet
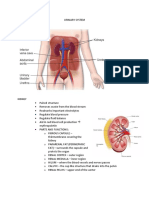
- Urinary SystemDocument9 pagesUrinary SystemMary Joyce RamosNo ratings yet
- Lesson Plan Format (Acad)Document4 pagesLesson Plan Format (Acad)Aienna Lacaya MatabalanNo ratings yet
- PVC Pressure Pipes and Fittings Catalogue (Pannon Pipe)Document8 pagesPVC Pressure Pipes and Fittings Catalogue (Pannon Pipe)vuthy prakNo ratings yet
- EW74Ëó+ Á+ ÚDocument9 pagesEW74Ëó+ Á+ Úundibal rivasNo ratings yet
- Week 1: Introduction: NM NM Ev Ev E DT T P EDocument9 pagesWeek 1: Introduction: NM NM Ev Ev E DT T P EInstituto Centro de Desenvolvimento da GestãoNo ratings yet
- Circuito Integrado BA05STDocument10 pagesCircuito Integrado BA05STEstefano EspinozaNo ratings yet
- Lab 7 QUBE-Servo PD Control WorkbookDocument6 pagesLab 7 QUBE-Servo PD Control WorkbookLuis EnriquezNo ratings yet
- Ignition Loss of Cured Reinforced Resins: Standard Test Method ForDocument3 pagesIgnition Loss of Cured Reinforced Resins: Standard Test Method ForElida SanchezNo ratings yet