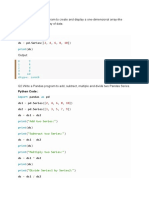
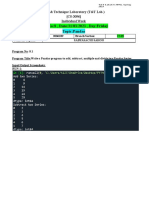
Download as pdf or txt
You might also like
- Introduction To RAPID - Operating Manual - ABB RoboticsDocument58 pagesIntroduction To RAPID - Operating Manual - ABB RoboticsPrabhu100% (2)
- Microsoft V Motorola ITC '376 Patent Claim ChartDocument265 pagesMicrosoft V Motorola ITC '376 Patent Claim ChartFlorian MuellerNo ratings yet
- Creation of Series Using List, Dictionary & NdarrayDocument65 pagesCreation of Series Using List, Dictionary & Ndarrayrizwana fathimaNo ratings yet
- Pandas Practicals - Term-1Document18 pagesPandas Practicals - Term-1Rudra DewanganNo ratings yet
- XII - Informatics Practices (LAB MANUAL)Document42 pagesXII - Informatics Practices (LAB MANUAL)ghun assudani100% (1)
- DataFrame CreationDocument16 pagesDataFrame CreationSarvesh MariappanNo ratings yet
- Pip3 Install JupyterDocument16 pagesPip3 Install Jupyterblah blNo ratings yet
- Practical File PythonDocument25 pagesPractical File Pythonkaizenpro01No ratings yet
- National Public School: Name-Karan Choudhary Class-XII Subject - Informatics Practices (065) Board Roll No.Document24 pagesNational Public School: Name-Karan Choudhary Class-XII Subject - Informatics Practices (065) Board Roll No.rajeshNo ratings yet
- National Public School: Name-Karan Choudhary Class-XII Subject - Informatics Practices (065) Board Roll No.Document35 pagesNational Public School: Name-Karan Choudhary Class-XII Subject - Informatics Practices (065) Board Roll No.rajeshNo ratings yet
- Practical Record 2 PYTHON AND SQL PROGRAMS - 2023Document76 pagesPractical Record 2 PYTHON AND SQL PROGRAMS - 2023isnprincipal2020No ratings yet
- IP DataFrames (Introduction)Document18 pagesIP DataFrames (Introduction)WhiteNo ratings yet
- SBLC 1Document23 pagesSBLC 1RajNo ratings yet
- Creation of DFDocument16 pagesCreation of DFSarvesh MariappanNo ratings yet
- Saish IP ProjectDocument16 pagesSaish IP ProjectSaish ParkarNo ratings yet
- Suryadatta National School Class 12 CBSE Informatics Practices Practicals ListDocument19 pagesSuryadatta National School Class 12 CBSE Informatics Practices Practicals ListOm JagdeeshNo ratings yet
- Jashan MLDocument20 pagesJashan MLanuragmonu0001No ratings yet
- Practical File Part 1Document17 pagesPractical File Part 1Om Rane XII CNo ratings yet
- Python PracticalsDocument26 pagesPython Practicalsvenkat krishnanNo ratings yet
- Practical Xii 11-25Document14 pagesPractical Xii 11-25ain't MohitNo ratings yet
- PandaDocument33 pagesPandakrNo ratings yet
- Pandas DataframeDocument48 pagesPandas DataframeJames PrakashNo ratings yet
- Practical File: School Name School LogoDocument35 pagesPractical File: School Name School Logovinayak chandra100% (1)
- Project FileRonak IPDocument27 pagesProject FileRonak IPash kathumNo ratings yet
- Journal 12Document54 pagesJournal 12Be xNo ratings yet
- Python ProgramsDocument25 pagesPython ProgramsPrajwalNo ratings yet
- IP Practical PRGMDocument41 pagesIP Practical PRGMJeya IshwaryaNo ratings yet
- ML Lab Manual FinalDocument36 pagesML Lab Manual Finaltrinadhrao30112003No ratings yet
- Add Column, Drop DataframeDocument6 pagesAdd Column, Drop DataframePainNo ratings yet
- Informatics Practices Practical List22-2323Document7 pagesInformatics Practices Practical List22-2323Shivam GoswamiNo ratings yet
- Kendriya Vidyalaya Ujjain: Submitted By:-Subodhit ChouhanDocument21 pagesKendriya Vidyalaya Ujjain: Submitted By:-Subodhit ChouhanSubodhit ChouhanNo ratings yet
- Informatics Practices Practical List22-2323Document7 pagesInformatics Practices Practical List22-2323Shivam GoswamiNo ratings yet
- G Pandey PracticalDocument33 pagesG Pandey PracticalSadananda Moirãngthëm Gidi LêïjreNo ratings yet
- Pandas Questions Ip FileDocument13 pagesPandas Questions Ip FileAISHI SHARMANo ratings yet
- Sheet 5 PandasDocument13 pagesSheet 5 PandasIrene GabrielNo ratings yet
- Python Series DataFrames Commands Methods Properties Examples (2022-23) PDFDocument16 pagesPython Series DataFrames Commands Methods Properties Examples (2022-23) PDFSaniya Santhosh100% (1)
- IP - Record 2023-24Document79 pagesIP - Record 2023-24FreyaNo ratings yet
- IP - Pandas 1 & 2 (Worksheet) Class 12Document16 pagesIP - Pandas 1 & 2 (Worksheet) Class 12WhiteNo ratings yet
- 5 SCDocument13 pages5 SCSABYASACHI SAHOONo ratings yet
- Python SlipsDocument9 pagesPython Slipsemmamusk061No ratings yet
- Practical List IpDocument10 pagesPractical List IpRaj aditya Shrivastava100% (1)
- Kunj Project 1Document34 pagesKunj Project 1kunj123sharmaNo ratings yet
- 7 Days Analytics Course 3feiz7 4Document8 pages7 Days Analytics Course 3feiz7 4anupamakarupiahNo ratings yet
- Pandasmatplotlib Practical FileDocument15 pagesPandasmatplotlib Practical FilegodayushshrivastavaNo ratings yet
- IP Practical 2023-24 (1 To 34)Document32 pagesIP Practical 2023-24 (1 To 34)Epic Person100% (1)
- 12 IP CBSE Practical File (PART-1)Document27 pages12 IP CBSE Practical File (PART-1)AdithyaNo ratings yet
- Info PracticalDocument56 pagesInfo PracticalBoves AlexNo ratings yet
- Fds MannualDocument39 pagesFds MannualsudhaNo ratings yet
- Kunj 3Document34 pagesKunj 3kunj123sharmaNo ratings yet
- Ip Practical FileDocument20 pagesIp Practical Fileayanspartan3536No ratings yet
- Record Program - Series (2022)Document8 pagesRecord Program - Series (2022)ShyamNo ratings yet
- Practical File Questions With AnswersDocument7 pagesPractical File Questions With AnswersPriyanshu KumarNo ratings yet
- National Public School: Name-Mohit Kumar Class-XII Subject - Informatics Practices (065) Board Roll No.Document35 pagesNational Public School: Name-Mohit Kumar Class-XII Subject - Informatics Practices (065) Board Roll No.rajeshNo ratings yet
- National Public School: Name-Mohit Kumar Class-XII Subject - Informatics Practices (065) Board Roll No.Document35 pagesNational Public School: Name-Mohit Kumar Class-XII Subject - Informatics Practices (065) Board Roll No.rajeshNo ratings yet
- Block 1-Data Handling Using Pandas DataFrameDocument17 pagesBlock 1-Data Handling Using Pandas DataFrameBhaskar PVNNo ratings yet
- Viksit Ip Project FileDocument33 pagesViksit Ip Project Fileviksit427No ratings yet
- Intro To Py and ML - Part 2Document10 pagesIntro To Py and ML - Part 2KAORU AmaneNo ratings yet
- Ipr Practical 2022Document7 pagesIpr Practical 2022Shivam GoswamiNo ratings yet
- IP Practic MINEDocument30 pagesIP Practic MINESouryo Das GuptaNo ratings yet
- Lab 8Document9 pagesLab 8358PRAKHAR DUBEYNo ratings yet
- Wa0012.Document30 pagesWa0012.hewepo4344No ratings yet
- SPF File FormatDocument29 pagesSPF File FormatStelios AntoniouNo ratings yet
- MS Press - Programming Windows With MFC - 2nd Edition by Jeff ProsiseDocument1,427 pagesMS Press - Programming Windows With MFC - 2nd Edition by Jeff ProsiseShahbazNo ratings yet
- DAX Refernce MicrosoftDocument697 pagesDAX Refernce MicrosoftMuhammad Azeem KhanNo ratings yet
- 5 - Handling Primitive Data TypesDocument10 pages5 - Handling Primitive Data TypesJoey LazarteNo ratings yet
- Import Shapefile To Access DB VBADocument4 pagesImport Shapefile To Access DB VBAtecnicoengenNo ratings yet
- Pec3 - Practicas de ProgramacionDocument43 pagesPec3 - Practicas de ProgramacionGaliciaNo ratings yet
- How To Use Automatic Shared Memory Management (ASMM) in Oracle 10g & Later Releases Document 295626.1Document10 pagesHow To Use Automatic Shared Memory Management (ASMM) in Oracle 10g & Later Releases Document 295626.1Alexander SuarezNo ratings yet
- ECE 513 Part1 ArduinoUnoFundamentals Ver1.2Document76 pagesECE 513 Part1 ArduinoUnoFundamentals Ver1.2Jecren Godinez BoocNo ratings yet
- DS, C, C++, Aptitude, Unix, RDBMS, SQL, CN, OsDocument176 pagesDS, C, C++, Aptitude, Unix, RDBMS, SQL, CN, Osapi-372652067% (3)
- Digital System Design 2 - CHAPTER 5Document46 pagesDigital System Design 2 - CHAPTER 5Hồng PhúNo ratings yet
- Cisco IOS SNMP Support Command ReferenceDocument478 pagesCisco IOS SNMP Support Command ReferencescorcdNo ratings yet
- Q4Mod1TLEGrade9 10WebPageDesign Daulong 450MHS 250SINHS FOR STUDENTSDocument11 pagesQ4Mod1TLEGrade9 10WebPageDesign Daulong 450MHS 250SINHS FOR STUDENTSEimhiosNo ratings yet
- PHP ProgrammingDocument92 pagesPHP ProgrammingRamakrishna ChintalaNo ratings yet
- Python Programming - Unit-1Document168 pagesPython Programming - Unit-1VIJAY GNo ratings yet
- Python 3 Cheat Sheet: Int Float Bool STR List TupleDocument2 pagesPython 3 Cheat Sheet: Int Float Bool STR List TupleDeen IslamNo ratings yet
- Data DictionaryDocument36 pagesData DictionaryDheeya NuruddinNo ratings yet
- Lecture#8-Instruction Set Architecture - 012458Document17 pagesLecture#8-Instruction Set Architecture - 012458ALINo ratings yet
- DataType in TypeScriptDocument4 pagesDataType in TypeScriptRaheel IqbalNo ratings yet
- Python Assignment 1Document8 pagesPython Assignment 1eshanpadhiar3No ratings yet
- Java Ref CardDocument2 pagesJava Ref CardcrennydaneNo ratings yet
- ML Lab ExperimentsDocument116 pagesML Lab ExperimentsSaniyaNo ratings yet
- Python Lab ProgramsDocument34 pagesPython Lab Programsharish03022004No ratings yet
- Oraclecoding (Encrypted)Document67 pagesOraclecoding (Encrypted)Ashish GulshanNo ratings yet
- Dafny TutorialDocument30 pagesDafny TutorialSumit LahiriNo ratings yet
- 7 From Prof. Dullea: CSC8490 Introduction To PL/SQLDocument36 pages7 From Prof. Dullea: CSC8490 Introduction To PL/SQLAkash KumarNo ratings yet
- Docmail Hybrid Mail API v2 Guide 30/03/2011Document70 pagesDocmail Hybrid Mail API v2 Guide 30/03/2011ScribrWillNo ratings yet
- Language Fundamentals-JavaDocument8 pagesLanguage Fundamentals-JavasycuneNo ratings yet
- 030 Decaf SpecificationDocument13 pages030 Decaf Specificationdeepak168No ratings yet