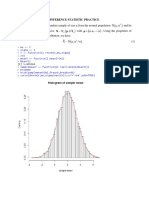
Download as pdf or txt
You might also like
- CIA Part 2 ExamDocument55 pagesCIA Part 2 ExamАндрей Б-н100% (4)
- Cramer Raoh and Out 08Document13 pagesCramer Raoh and Out 08Waranda AnutaraampaiNo ratings yet
- Chapter 7-Frequency AnalysisDocument18 pagesChapter 7-Frequency AnalysisnimcanNo ratings yet
- Polynomials and The FFT: Chapter 32 in CLR Chapter 30 in CLRSDocument34 pagesPolynomials and The FFT: Chapter 32 in CLR Chapter 30 in CLRSאביעד אלפסיNo ratings yet
- CS-E4820 Machine Learning: Advanced Probabilistic MethodsDocument2 pagesCS-E4820 Machine Learning: Advanced Probabilistic MethodsGigiNo ratings yet
- Chapter 3 Introduction To Data Science A Python Approach To Concepts, Techniques and ApplicationsDocument22 pagesChapter 3 Introduction To Data Science A Python Approach To Concepts, Techniques and ApplicationsChuin-Shan David ChenNo ratings yet
- 3rd Partial Collaborative Activity #1Document2 pages3rd Partial Collaborative Activity #1Javier Cedillo SanchezNo ratings yet
- MC RiskManageDocument19 pagesMC RiskManageWazzupWorldNo ratings yet
- cdd4 PDFDocument75 pagescdd4 PDFUsman HamIdNo ratings yet
- Edmund Landau PHD ThesisDocument17 pagesEdmund Landau PHD ThesisMartín-Blas Pérez PinillaNo ratings yet
- Random Numbers and Monte Carlo MethodsDocument6 pagesRandom Numbers and Monte Carlo MethodsAtif AvdovićNo ratings yet
- Method of Moments: Topic 13Document9 pagesMethod of Moments: Topic 13Zeeshan AhmedNo ratings yet
- Concentration of The Cost of A Random Matching Problem: Martin Hessler and Johan W Astlund August 20, 2008Document25 pagesConcentration of The Cost of A Random Matching Problem: Martin Hessler and Johan W Astlund August 20, 2008Michelle MenesesNo ratings yet
- 4404 Notes ATVDocument6 pages4404 Notes ATVSudeep RajaNo ratings yet
- Parameter Estimations of Normal Distribution Via Genetic Algorithm and Its Application To Carbonation DepthDocument6 pagesParameter Estimations of Normal Distribution Via Genetic Algorithm and Its Application To Carbonation DepthPablo BenitezNo ratings yet
- Lectura 2 Point Estimator BasicsDocument11 pagesLectura 2 Point Estimator BasicsAlejandro MarinNo ratings yet
- 1.8. Large Deviation and Some Exponential Inequalities.: B R e DX Essinf G (X), T e DX Esssup G (X)Document4 pages1.8. Large Deviation and Some Exponential Inequalities.: B R e DX Essinf G (X), T e DX Esssup G (X)Naveen Kumar SinghNo ratings yet
- CLT PDFDocument4 pagesCLT PDFdNo ratings yet
- Non Parametric PredictionDocument16 pagesNon Parametric PredictionTraderCat SolarisNo ratings yet
- Definition 9.1.1.: - April 25, 2016Document16 pagesDefinition 9.1.1.: - April 25, 2016hariharan1No ratings yet
- General Physics 106 Lab ManualDocument9 pagesGeneral Physics 106 Lab ManualFrancis anandNo ratings yet
- Unbiased StatisticDocument15 pagesUnbiased StatisticOrYuenyuenNo ratings yet
- Point Estimation: Definition of EstimatorsDocument8 pagesPoint Estimation: Definition of EstimatorsUshnish MisraNo ratings yet
- Week 8 Lecture NewDocument49 pagesWeek 8 Lecture NewHANJING QUANNo ratings yet
- Identifying Primes in Polynomial Time: The AKS Algorithm: Andrew PutmanDocument11 pagesIdentifying Primes in Polynomial Time: The AKS Algorithm: Andrew Putman25. Cao Anh Vũ 11ANo ratings yet
- Report4 Density Estimation AllDocument63 pagesReport4 Density Estimation AllJohnNo ratings yet
- Data Analysis For Social Scientists (14.1310x)Document12 pagesData Analysis For Social Scientists (14.1310x)SebastianNo ratings yet
- 18.S096: Homework Problem Set 1 (Revised) : Topics in Mathematics of Data Science (Fall 2015) Afonso S. BandeiraDocument6 pages18.S096: Homework Problem Set 1 (Revised) : Topics in Mathematics of Data Science (Fall 2015) Afonso S. BandeiraAbdelrhman ShoeebNo ratings yet
- Csci567 Hw1 Spring 2016Document9 pagesCsci567 Hw1 Spring 2016mhasanjafryNo ratings yet
- Method of MomentsDocument4 pagesMethod of MomentsladyfairynaNo ratings yet
- Estimation Theory PresentationDocument66 pagesEstimation Theory PresentationBengi Mutlu Dülek100% (1)
- Ieee Wind EnergyDocument16 pagesIeee Wind EnergyAnonymous ZFt1pzKY1No ratings yet
- Odf-SC1 05 MonteCarloDocument22 pagesOdf-SC1 05 MonteCarloi wNo ratings yet
- 1 Metrics IntroDocument5 pages1 Metrics IntroDmitri ZaitsevNo ratings yet
- Large Deviations: S. R. S. VaradhanDocument12 pagesLarge Deviations: S. R. S. VaradhanLuis Alberto FuentesNo ratings yet
- Applied Mathematics Letters: A. Amini-HarandiDocument4 pagesApplied Mathematics Letters: A. Amini-HarandiunebelleNo ratings yet
- 2.AppliedMathProb Individual 2011Document3 pages2.AppliedMathProb Individual 2011Yasamin RezashateriNo ratings yet
- Statistics DiffusionsDocument66 pagesStatistics DiffusionsGenevieve Magpayo NangitNo ratings yet
- Michael Parkinson PDFDocument6 pagesMichael Parkinson PDFPepeNo ratings yet
- Point Estimation: Institute of Technology of CambodiaDocument22 pagesPoint Estimation: Institute of Technology of CambodiaSao SavathNo ratings yet
- Statistical Inference: Classical and Bayesian MethodsDocument22 pagesStatistical Inference: Classical and Bayesian Methodsbetho1992No ratings yet
- Numerical Methods: Marisa Villano, Tom Fagan, Dave Fairburn, Chris Savino, David Goldberg, Daniel RaveDocument44 pagesNumerical Methods: Marisa Villano, Tom Fagan, Dave Fairburn, Chris Savino, David Goldberg, Daniel RaveSanjeev DwivediNo ratings yet
- A Probability Perspective To A Combinatorics ProblemDocument3 pagesA Probability Perspective To A Combinatorics ProblemcmcclosNo ratings yet
- Tests Based On Asymptotic PropertiesDocument6 pagesTests Based On Asymptotic PropertiesJung Yoon SongNo ratings yet
- Random Signals: 1 Kolmogorov's Axiomatic Definition of ProbabilityDocument14 pagesRandom Signals: 1 Kolmogorov's Axiomatic Definition of ProbabilitySeham RaheelNo ratings yet
- Prof. Richardson NeuralnetworksDocument61 pagesProf. Richardson NeuralnetworkschrissbansNo ratings yet
- 9.0 Lesson PlanDocument16 pages9.0 Lesson PlanSähilDhånkhårNo ratings yet
- C Inference Statistic With RDocument11 pagesC Inference Statistic With RLinh NguyễnNo ratings yet
- Maximum Likelihood An Introduction: L. Le CamDocument31 pagesMaximum Likelihood An Introduction: L. Le CamTiffany SpenceNo ratings yet
- ST102 NotesDocument21 pagesST102 NotesBenjamin Ng0% (1)
- SST1102 Lecture4Document23 pagesSST1102 Lecture4Tadiwanashe MagombeNo ratings yet
- Non-Parametric Methods Using Kernel Density EstimationDocument1 pageNon-Parametric Methods Using Kernel Density Estimationee12b056No ratings yet
- R300 Advanced Econometrics Methods Lecture SlidesDocument362 pagesR300 Advanced Econometrics Methods Lecture SlidesMarco BrolliNo ratings yet
- Sums of A Random VariablesDocument21 pagesSums of A Random VariablesWaseem AbbasNo ratings yet
- Review of Random VariablesDocument8 pagesReview of Random Variableselifeet123No ratings yet
- 17 The Assignment Problem: Author: PrerequisitesDocument23 pages17 The Assignment Problem: Author: PrerequisitesRama Krishna MuttavarapuNo ratings yet
- Multi Varia Da 1Document59 pagesMulti Varia Da 1pereiraomarNo ratings yet
- On The Eigenspectrum of The Gram Matrix and Its Relationship To The Operator EigenspectrumDocument18 pagesOn The Eigenspectrum of The Gram Matrix and Its Relationship To The Operator EigenspectrumMartine DumontNo ratings yet
- EstimationDocument12 pagesEstimationwe_spidus_2006No ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- EN112 Slide Show LimitsDocument6 pagesEN112 Slide Show LimitsAmos KewaNo ratings yet
- CD 111 Lecture 4 Week 5 (Mar 15th, 2023)Document26 pagesCD 111 Lecture 4 Week 5 (Mar 15th, 2023)Amos KewaNo ratings yet
- CD 111 Lecture 1 WK 2 - Ref List - Bibliograhy (Feb 22, 2023)Document25 pagesCD 111 Lecture 1 WK 2 - Ref List - Bibliograhy (Feb 22, 2023)Amos KewaNo ratings yet
- CD 111 - Scheme of Work - 2023Document5 pagesCD 111 - Scheme of Work - 2023Amos KewaNo ratings yet
- Ms Arjass 86202Document12 pagesMs Arjass 86202Haqiqi RafsanjaniNo ratings yet
- Channel Capacity of IMDD Optical CommunicationDocument6 pagesChannel Capacity of IMDD Optical CommunicationwatchitonthetvNo ratings yet
- Continuous Probability DistributionDocument53 pagesContinuous Probability Distributionanola prickNo ratings yet
- IPE - 302 Sessional SheetDocument22 pagesIPE - 302 Sessional SheetzahirrayhanNo ratings yet
- BA:Statistics For ManagementDocument128 pagesBA:Statistics For ManagementAnkur MittalNo ratings yet
- The T DistributionDocument5 pagesThe T DistributionSoftkillerNo ratings yet
- Koch I. Analysis of Multivariate and High-Dimensional Data 2013Document532 pagesKoch I. Analysis of Multivariate and High-Dimensional Data 2013rciani100% (15)
- E 456 - 96 Standard Terminology For Relating To Quality and Statistics1Document8 pagesE 456 - 96 Standard Terminology For Relating To Quality and Statistics1JORGE ARTURO TORIBIO HUERTA100% (2)
- Normal Distribution Excel ExampleDocument16 pagesNormal Distribution Excel ExamplehaffaNo ratings yet
- Mod 5 Hypo1finDocument50 pagesMod 5 Hypo1finJOHN GABRIEL ESTRADA CAPISTRANONo ratings yet
- Comparative Studies of The Model Evaluation Criterions MMRE and PRED in Software Cost Estimation ResearchDocument11 pagesComparative Studies of The Model Evaluation Criterions MMRE and PRED in Software Cost Estimation Researchutkarsh sharmaNo ratings yet
- chp2 EconometricDocument54 pageschp2 EconometricCabdilaahi CabdiNo ratings yet
- TC 005Document17 pagesTC 005Valya RusevaNo ratings yet
- Control ChartsDocument31 pagesControl ChartsAkash KazamaNo ratings yet
- PH Stat HelpDocument43 pagesPH Stat HelpTanner WarehamNo ratings yet
- 5 - Continuous Normal DistributionDocument11 pages5 - Continuous Normal DistributionSudibyo GunawanNo ratings yet
- Normal Distribution Test Multiple-Choice Questions (13 Marks)Document6 pagesNormal Distribution Test Multiple-Choice Questions (13 Marks)richard langley100% (1)
- M155ST2aAnswers PDFDocument7 pagesM155ST2aAnswers PDFHanna Grace HonradeNo ratings yet
- 5.confidence IntervalDocument53 pages5.confidence IntervaltunetonevidevideNo ratings yet
- ch09 Quantitative FinanceDocument41 pagesch09 Quantitative FinanceYogeeta RughooNo ratings yet
- Probability Theory and Probability DistributionsDocument8 pagesProbability Theory and Probability DistributionsCaesarKamanziNo ratings yet
- All LecturesDocument53 pagesAll LecturesKevin AlexanderNo ratings yet
- Statistical InferenceDocument148 pagesStatistical InferenceSara ZeynalzadeNo ratings yet
- 2071stat PDFDocument2 pages2071stat PDFsabi khadkaNo ratings yet
- Market Profile-Futures TradingDocument6 pagesMarket Profile-Futures TradingAlp Dhingra100% (2)
- Stakeholder Tracking and Analysis: The Reptrak® System For Measuring Corporate ReputationDocument23 pagesStakeholder Tracking and Analysis: The Reptrak® System For Measuring Corporate ReputationSilvi Julya IndNo ratings yet
- M & M P DPPM M F M: Odeling Onitoring of Roduct With Ultiple AIL OdesDocument7 pagesM & M P DPPM M F M: Odeling Onitoring of Roduct With Ultiple AIL OdesYosi SoltNo ratings yet