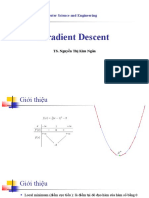
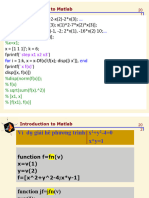
Download as odp, pdf, or txt
You might also like
- BTL ĐSTTDocument10 pagesBTL ĐSTTTrần Toàn83% (6)
- 1.2 Đo Thi Cua Ham SoDocument18 pages1.2 Đo Thi Cua Ham SoHuyền VũNo ratings yet
- Chiến lược giảm để trịDocument47 pagesChiến lược giảm để trịmrbkiter100% (1)
- Bài 8 - TƯƠNG QUAN VÀ H I QUYDocument12 pagesBài 8 - TƯƠNG QUAN VÀ H I QUYminhanh.2003tniNo ratings yet
- Hoi Quy Tuyen TinhDocument9 pagesHoi Quy Tuyen TinhDuyên NguyễnNo ratings yet
- K - LinearRegressionDocument23 pagesK - LinearRegressionmadaik965No ratings yet
- Bài Tập Thực Hành EXCELDocument91 pagesBài Tập Thực Hành EXCELPhuong LeNo ratings yet
- Bai 3 6-Excel PDFDocument90 pagesBai 3 6-Excel PDFduy quang nguyễnNo ratings yet
- Bai Tap Kinh Te Luong Hoi Quy Don Bien Co Dap AnDocument8 pagesBai Tap Kinh Te Luong Hoi Quy Don Bien Co Dap AnDương ThuỳNo ratings yet
- KTL Chương 4Document24 pagesKTL Chương 4phamluunhutnam14092003No ratings yet
- R For RegressionDocument7 pagesR For RegressionHuy Từ Phạm NgọcNo ratings yet
- LÝ THUYẾT PCADocument6 pagesLÝ THUYẾT PCAPhú VũNo ratings yet
- DHMT 02Document50 pagesDHMT 02Hieu LaptopNo ratings yet
- Đề Cương Ôn Ktl Cuối KỳDocument34 pagesĐề Cương Ôn Ktl Cuối KỳdyhgnnNo ratings yet
- KinhTếLượngDocument65 pagesKinhTếLượngVân TrườngNo ratings yet
- Hoi Qui Va Tuong QuanDocument35 pagesHoi Qui Va Tuong Quantrieunn22No ratings yet
- Mô hình hồi quy tuyến tínhDocument43 pagesMô hình hồi quy tuyến tínhVince VoNo ratings yet
- L3 Linear RegressionDocument18 pagesL3 Linear RegressionBa Toan NguyenNo ratings yet
- Chapter 2.1-Linear RegressionDocument17 pagesChapter 2.1-Linear Regressionha quanNo ratings yet
- Lovebook VN - 1Document57 pagesLovebook VN - 1tthhuu2111No ratings yet
- Chapter 3.1-Gradient DescentDocument21 pagesChapter 3.1-Gradient Descentha quanNo ratings yet
- Chuong4 5.3.ARIMA ModelsDocument58 pagesChuong4 5.3.ARIMA ModelsPhương Trang LêNo ratings yet
- Slide Trò ChơiDocument359 pagesSlide Trò Chơi5g55fnjhwtNo ratings yet
- Chương - 01 - Counting Statistics and Error PredictionDocument98 pagesChương - 01 - Counting Statistics and Error PredictionDũng NguyễnNo ratings yet
- CH 3Document74 pagesCH 3Quân PhạmNo ratings yet
- 3.linear RegressionDocument13 pages3.linear Regression21020127 Hà Công NgaNo ratings yet
- PP Sử Dụng Hàm Sinh (Đại Số Sơ Cấp) - Phạm Thế Bảo (Repaired)Document12 pagesPP Sử Dụng Hàm Sinh (Đại Số Sơ Cấp) - Phạm Thế Bảo (Repaired)bảo phạmNo ratings yet
- ôn tập thống kêDocument21 pagesôn tập thống kêTrung ThuNo ratings yet
- Kiến thức toán cho lýDocument3 pagesKiến thức toán cho lý33Nguyễn Đình Thi 9/3No ratings yet
- BaiGiang Matlab Phan3 2024Document40 pagesBaiGiang Matlab Phan3 202445 Bùi ĐẮc VINHNo ratings yet
- L12- Dự Đoán Bằng Hồi Quy Tuyến Tính-DMDocument30 pagesL12- Dự Đoán Bằng Hồi Quy Tuyến Tính-DMnguyenhoai04102003No ratings yet
- BG Tinh Don Dieu Cua Ham So 65244 1663643725-1-4Document4 pagesBG Tinh Don Dieu Cua Ham So 65244 1663643725-1-424a4022589No ratings yet
- Lời mở đầuDocument8 pagesLời mở đầunduc0163401003No ratings yet
- Bài tập lớn ĐSTT Nhóm 8 L20Document7 pagesBài tập lớn ĐSTT Nhóm 8 L20VY TRẦN ĐOÀN NHẬTNo ratings yet
- Chương 1. Hàm số gửi svDocument19 pagesChương 1. Hàm số gửi svHương ThuNo ratings yet
- KTL2Document17 pagesKTL2050610220832No ratings yet
- Tai Lieu Chuyen de Khao Sat Su Bien Thien Va Ve Do Thi Cua Ham SoDocument181 pagesTai Lieu Chuyen de Khao Sat Su Bien Thien Va Ve Do Thi Cua Ham Sominhteu20056No ratings yet
- ch1 Linear Systems 2022Document68 pagesch1 Linear Systems 2022John WatsonNo ratings yet
- MMedu - Tóm tắt Toán 7Document9 pagesMMedu - Tóm tắt Toán 7Phan Thanh TùngNo ratings yet
- 1. Xác Suất — Deep AI KhanhBlogDocument14 pages1. Xác Suất — Deep AI KhanhBlog2211140208 Phùng Phương NgânNo ratings yet
- kinh tế lượngDocument5 pageskinh tế lượngLương TrầnNo ratings yet
- Hồi Quy Tuyến Tính FulbrightDocument38 pagesHồi Quy Tuyến Tính Fulbrightpibaso6725No ratings yet
- Bai Giang TCC 9772Document75 pagesBai Giang TCC 9772HiềnNo ratings yet
- Tong Hop Kien Thuc Mon Toan Lop 7Document9 pagesTong Hop Kien Thuc Mon Toan Lop 7minhducNo ratings yet
- GT1 Chuong1 v4 PDFDocument205 pagesGT1 Chuong1 v4 PDFVũ Đỗ VănNo ratings yet
- Chinh Phục VDC Giải Tích 2023 Phan Nhật LinhDocument498 pagesChinh Phục VDC Giải Tích 2023 Phan Nhật LinhTai Lieu On ThiNo ratings yet
- Buoi 7 - SVMDocument46 pagesBuoi 7 - SVMNguyễn AnNo ratings yet
- - Nguyễn Đào Lan Anh - AMA303 - 211 - D02Document14 pages- Nguyễn Đào Lan Anh - AMA303 - 211 - D02Sa SaNo ratings yet
- Phan I - Ch4-Multivariate RegressionDocument74 pagesPhan I - Ch4-Multivariate RegressionMinh Khánh CaoNo ratings yet
- Chuong 8 Thong ke - Hồi quy tuyến tính đơnDocument27 pagesChuong 8 Thong ke - Hồi quy tuyến tính đơnVy Phạm Thị TrúcNo ratings yet
- Chương 2 - Phân phối xác suất của đại lượng ngẫu nhiên rời rạcDocument22 pagesChương 2 - Phân phối xác suất của đại lượng ngẫu nhiên rời rạcdieuulinhh955No ratings yet
- Công Thức Môn Quản Trị Vận Hành Doanh NghiệpDocument25 pagesCông Thức Môn Quản Trị Vận Hành Doanh NghiệpOanh Trịnh Vũ KiềuNo ratings yet
- Chuong 6. Phan Tich Hoi Qui.1Document145 pagesChuong 6. Phan Tich Hoi Qui.1thu31tranconghienNo ratings yet
- Hoi Quy Tuyen TinhDocument24 pagesHoi Quy Tuyen TinhNguyễn VũNo ratings yet
- Btlgt2 p01 Nhom n1Document18 pagesBtlgt2 p01 Nhom n1CaoLong NguyenNo ratings yet
- Kinh Tế Lượng (Econometrics) : Chương 4: Đa cộng tuyến (Multicollinerity)Document24 pagesKinh Tế Lượng (Econometrics) : Chương 4: Đa cộng tuyến (Multicollinerity)LinaNo ratings yet
- Chương 3Document46 pagesChương 3Lộc Phạm PhướcNo ratings yet
- Phan 3 Bien Ngau Nhien PDF 1703071367096Document6 pagesPhan 3 Bien Ngau Nhien PDF 1703071367096phqa1199No ratings yet
- BaigiangToiuu 2Document22 pagesBaigiangToiuu 2Ánh Thiện TriệuNo ratings yet
- So NDocument4 pagesSo NNguyễn QuyNo ratings yet
- Chuong IIDocument37 pagesChuong IINguyễn QuyNo ratings yet
- 5 Chuong 5.1 Dhcp-DNS-webDocument20 pages5 Chuong 5.1 Dhcp-DNS-webNguyễn QuyNo ratings yet
- 2 - Chuong 2 - HE DIEU HANHDocument20 pages2 - Chuong 2 - HE DIEU HANHNguyễn QuyNo ratings yet
- 7 - Chuong 7 - NGUYEN TAC - QUAN TRIDocument21 pages7 - Chuong 7 - NGUYEN TAC - QUAN TRINguyễn QuyNo ratings yet