
Optically Connected Memory For Disaggregated Data Centers
Optically Connected Memory For Disaggregated Data Centers
You might also like
- Module 2Document46 pagesModule 2tarunkumarsj117No ratings yet
- Honda CRV CR-V Radio Connector PinsDocument17 pagesHonda CRV CR-V Radio Connector Pinsdonald nugrahaNo ratings yet
- Prestige Medical Classic 2100 ManualDocument72 pagesPrestige Medical Classic 2100 Manualwael26724734083No ratings yet
- CXL Over Ethernet A Novel FPGA-based MemoryDocument9 pagesCXL Over Ethernet A Novel FPGA-based Memoryy18864773539No ratings yet
- Combining Memory and A Controller With Photonics Through 3D-Stacking To Enable Scalable and Energy-Efficient SystemsDocument12 pagesCombining Memory and A Controller With Photonics Through 3D-Stacking To Enable Scalable and Energy-Efficient SystemsSuman SamuiNo ratings yet
- 3D IC Architecture For High Density MemoriesDocument6 pages3D IC Architecture For High Density MemoriesUllasNo ratings yet
- Sdram JRNDocument15 pagesSdram JRNThanh Tùng CaoNo ratings yet
- Multiply Accumulate Operations in Memristor Crossbar Arrays Foranalog ComputingDocument22 pagesMultiply Accumulate Operations in Memristor Crossbar Arrays Foranalog ComputingMohammed Siyad BNo ratings yet
- Corona: System Implications of Emerging Nanophotonic TechnologyDocument12 pagesCorona: System Implications of Emerging Nanophotonic TechnologyshoaebNo ratings yet
- Towards Integration of A Dedicated Memory ControllDocument11 pagesTowards Integration of A Dedicated Memory ControllBilal KhanNo ratings yet
- High-Throughput Pattern Matching WithDocument14 pagesHigh-Throughput Pattern Matching WithDr. Ruqaiya KhanamNo ratings yet
- Toward Dark Silicon in Servers: Kashif RabbaniDocument4 pagesToward Dark Silicon in Servers: Kashif RabbaniKashif RabbaniNo ratings yet
- A Ferroelectric FET-Based Processing-In-Memory ArcDocument8 pagesA Ferroelectric FET-Based Processing-In-Memory ArcFlavia Monica RodriguesNo ratings yet
- 7 PBDocument8 pages7 PBPV sushmithaNo ratings yet
- Compare Performance of 2D and 3D Mesh Architectures in Network-On-ChipDocument5 pagesCompare Performance of 2D and 3D Mesh Architectures in Network-On-ChipJournal of ComputingNo ratings yet
- Reconfigurable 2T2R ReRAM Architecture For Versatile Data Storage and Computing In-MemoryDocument14 pagesReconfigurable 2T2R ReRAM Architecture For Versatile Data Storage and Computing In-Memory莊昆霖No ratings yet
- Computer Architecture Unit 4Document8 pagesComputer Architecture Unit 4Santhanalakshmi SekharNo ratings yet
- 10 1109@tcsii 2020 3013336Document5 pages10 1109@tcsii 2020 3013336Kleber OliveiraNo ratings yet
- 10125-2002 CSVT On The Data Reuse and Memory Bandwidth Analysis For Full-Search Block-Matching VLSI ArchitectureDocument12 pages10125-2002 CSVT On The Data Reuse and Memory Bandwidth Analysis For Full-Search Block-Matching VLSI Architecturenavakanth4592706No ratings yet
- Hardware Memory Management For Future Mobile Hybrid Memory SystemsDocument11 pagesHardware Memory Management For Future Mobile Hybrid Memory SystemsMansoor GoharNo ratings yet
- Nand 20250474Document6 pagesNand 20250474HarikrishnaChinthalaboyinaNo ratings yet
- Neuro-Memristive Circuits For Edge Computing: A ReviewDocument20 pagesNeuro-Memristive Circuits For Edge Computing: A ReviewMax LorenNo ratings yet
- 10T SRAM Computing-in-Memory Macros For Binary andDocument15 pages10T SRAM Computing-in-Memory Macros For Binary and그랬구나No ratings yet
- 1506 02626 PDFDocument9 pages1506 02626 PDFdakshNo ratings yet
- Mira PDFDocument11 pagesMira PDFCecilia ChinnaNo ratings yet
- 21EC52 Module 2Document46 pages21EC52 Module 21 1No ratings yet
- Electronics 12 00834Document15 pagesElectronics 12 00834Dat Nguyen ThanhNo ratings yet
- AreviewonSRAM Basedcomputingin Memory Circuitsfunctionsandapplications3Document27 pagesAreviewonSRAM Basedcomputingin Memory Circuitsfunctionsandapplications3예민욱No ratings yet
- What's Up With The Storage Hierarchy?: 2. Design GoalsDocument2 pagesWhat's Up With The Storage Hierarchy?: 2. Design GoalsKevin MarcusNo ratings yet
- ED Proof: A Modular Approach To Design Ternary Content Addressable Memory Architecture in Quantum Dot Cellular AutomataDocument7 pagesED Proof: A Modular Approach To Design Ternary Content Addressable Memory Architecture in Quantum Dot Cellular AutomataPrashant RawatNo ratings yet
- Distributed Beamforming Techniques For Cell-Free Wireless Networks Using Deep Reinforcement LearningDocument16 pagesDistributed Beamforming Techniques For Cell-Free Wireless Networks Using Deep Reinforcement Learningwho3No ratings yet
- A Memristor As Multi-Bit Memory: Feasibility Analysis: Ori BASS, Alexander FISH, Doron NAVEHDocument6 pagesA Memristor As Multi-Bit Memory: Feasibility Analysis: Ori BASS, Alexander FISH, Doron NAVEHHussain Bin AliNo ratings yet
- A Logic-Compatible EDRAM Compute-In-Memory With Embedded ADCs For Processing Neural NetworksDocument13 pagesA Logic-Compatible EDRAM Compute-In-Memory With Embedded ADCs For Processing Neural NetworksHelloNo ratings yet
- Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural NetworksDocument14 pagesNeural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networksreg2regNo ratings yet
- Approximate NoC and Memory Controller Architectures For GPGPU AcceleratorsDocument15 pagesApproximate NoC and Memory Controller Architectures For GPGPU AcceleratorsMiguel Ramírez CarrilloNo ratings yet
- IEEE CEM-Looking Ahead For Resistive Memory Technology PDFDocument10 pagesIEEE CEM-Looking Ahead For Resistive Memory Technology PDFdsak199No ratings yet
- A106-Wang 0Document6 pagesA106-Wang 0ali shaarawyNo ratings yet
- Cell Multproc Comm NTWK - Built For SPDDocument14 pagesCell Multproc Comm NTWK - Built For SPDlycankNo ratings yet
- Three DIMENSIONAL-CHIPDocument6 pagesThree DIMENSIONAL-CHIPKumar Goud.KNo ratings yet
- Code Kozyraki Isca 2003Document11 pagesCode Kozyraki Isca 2003Shabad KaurNo ratings yet
- The Main Memory System: Challenges and OpportunitiesDocument26 pagesThe Main Memory System: Challenges and OpportunitiesVinay MadhavNo ratings yet
- Processor Architecture Design Using 3D Integration TechnologyDocument6 pagesProcessor Architecture Design Using 3D Integration TechnologyMilo MiloNo ratings yet
- Self Aware Memory Management For Emerging Energy Efficient ArchitecturesDocument8 pagesSelf Aware Memory Management For Emerging Energy Efficient ArchitecturessoniathalavoorNo ratings yet
- A Classy Memory Management System CyM2SDocument7 pagesA Classy Memory Management System CyM2SJNarigonNo ratings yet
- Performance Comparison of 3D-Mesh and 3D-Torus Network-on-ChipDocument5 pagesPerformance Comparison of 3D-Mesh and 3D-Torus Network-on-ChipJournal of ComputingNo ratings yet
- Structured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong SungDocument11 pagesStructured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong Sungali shaarawyNo ratings yet
- Memory Performance and Scalability of Intel's and AMD's Dual-Core Processors - A Case StudyDocument10 pagesMemory Performance and Scalability of Intel's and AMD's Dual-Core Processors - A Case StudyAnonymous Wu14iV9dqNo ratings yet
- Overview of 3D Architecture Design Opportunities and TechniquesDocument6 pagesOverview of 3D Architecture Design Opportunities and TechniquesPramod Reddy RNo ratings yet
- Demystifying CXL Memory With Genuine CXL Ready Systems and DevicesDocument12 pagesDemystifying CXL Memory With Genuine CXL Ready Systems and Devicesy18864773539No ratings yet
- Gain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipFrom EverandGain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipNo ratings yet
- Access Pattern Based Local Memory Customization For Low Power Embedded SystemsDocument7 pagesAccess Pattern Based Local Memory Customization For Low Power Embedded SystemsFarheen AsifNo ratings yet
- RBC A Memory Architecture For Improved Performance and Energy EfficiencyDocument14 pagesRBC A Memory Architecture For Improved Performance and Energy EfficiencyMUHAMMAD SAQIB SHABBIR UnknownNo ratings yet
- Openram: An Open-Source Memory CompilerDocument6 pagesOpenram: An Open-Source Memory CompilerGATE 2019No ratings yet
- Design and Operation of Energy-Aware Wireless Sensor Networks Through Scheduling and RoutingDocument3 pagesDesign and Operation of Energy-Aware Wireless Sensor Networks Through Scheduling and RoutingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Vesti Energy-Efficient In-Memory Computing Accelerator For Deep Neural NetworksDocument14 pagesVesti Energy-Efficient In-Memory Computing Accelerator For Deep Neural NetworksPANTHADIP MAJINo ratings yet
- A Case For CXL-Centric Sever ProcessorsDocument13 pagesA Case For CXL-Centric Sever Processorsy18864773539No ratings yet
- MM 3Document11 pagesMM 3Doğuş KantarciNo ratings yet
- Hybrid Memory Cube New DRAM Architecture Increases Density and PerformanceDocument2 pagesHybrid Memory Cube New DRAM Architecture Increases Density and PerformanceLauri P. Laux Jr.No ratings yet
- Fast Decoding ECC For Future MemoriesDocument12 pagesFast Decoding ECC For Future MemoriesMihir SahaNo ratings yet
- Latest Technologies To Enhance The Performance of MemoriesDocument5 pagesLatest Technologies To Enhance The Performance of MemoriesSajid UmarNo ratings yet
- A New Reference Frame Recompression Algorithm and Its VLSI Architecture For UHDTV Video CodecDocument10 pagesA New Reference Frame Recompression Algorithm and Its VLSI Architecture For UHDTV Video Codecdev- ledumNo ratings yet
- Distributed Clustering in Ad-Hoc Sensor Networks: A Hybrid, Energy-Efficient ApproachDocument12 pagesDistributed Clustering in Ad-Hoc Sensor Networks: A Hybrid, Energy-Efficient ApproachNivedita Acharyya 2035No ratings yet
- Donau CarbonDocument2 pagesDonau CarbonLim Chee SiangNo ratings yet
- 4 Inventory Management and Risk PoolingDocument54 pages4 Inventory Management and Risk PoolingSpandana AchantaNo ratings yet
- Format For CompilationDocument3 pagesFormat For CompilationPrincess Mia CristobalNo ratings yet
- Bmj-2021-069211.full Reduce Unnecessary Use of Proton Pump InhibitorsDocument7 pagesBmj-2021-069211.full Reduce Unnecessary Use of Proton Pump InhibitorsYo MeNo ratings yet
- Case 10 (Post-Operative Pain Management & Complication)Document10 pagesCase 10 (Post-Operative Pain Management & Complication)ReddyNo ratings yet
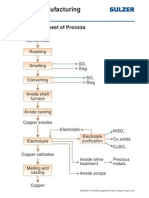
- Copper Manufacturing Process: General Flowsheet of ProcessDocument28 pagesCopper Manufacturing Process: General Flowsheet of ProcessflaviosazevedoNo ratings yet
- Compact Wideband Dual-Band Polarization and Pattern Diversity Antenna For Vehicle CommunicationsDocument6 pagesCompact Wideband Dual-Band Polarization and Pattern Diversity Antenna For Vehicle CommunicationsAnil NayakNo ratings yet
- i30-Drive-N-Limited-EditioN-Product BulletinDocument2 pagesi30-Drive-N-Limited-EditioN-Product BulletinYaxuan ZhuNo ratings yet
- WE503 IndicatorDocument1 pageWE503 IndicatorWANSNo ratings yet
- SAIL Challenges of Single Cell and Spatial ExperimentsDocument54 pagesSAIL Challenges of Single Cell and Spatial ExperimentsespartawithespartilhoNo ratings yet
- Companion Log 2018 10 10T13 44 31ZDocument15 pagesCompanion Log 2018 10 10T13 44 31ZTerbaik2u HDNo ratings yet
- Mystical Kashmir Vacation - With Houseboat Stay (14!04!2023T20 - 50) - QuoteId-25446607Document14 pagesMystical Kashmir Vacation - With Houseboat Stay (14!04!2023T20 - 50) - QuoteId-25446607time delhiNo ratings yet
- SW 500Document28 pagesSW 500Sujit KumarNo ratings yet
- Gurukul Hindi e Book by Sirhud KalraDocument17 pagesGurukul Hindi e Book by Sirhud KalraPARVANo ratings yet
- Big Data Analytics (2017 Regulation) : Unit - 2 Clustering and ClassificationDocument7 pagesBig Data Analytics (2017 Regulation) : Unit - 2 Clustering and ClassificationcskinitNo ratings yet
- Option B - BiochemistryDocument24 pagesOption B - BiochemistryRosaNo ratings yet
- TMV Trading PricelistDocument8 pagesTMV Trading Pricelistronald s. rodrigoNo ratings yet
- Research Paper Topics Oliver TwistDocument4 pagesResearch Paper Topics Oliver Twistnikuvivakuv3100% (1)
- Mathematical Thinking Skills of BSED-Math Students: Its Relationship To Study Habits and Utilization of SchoologyDocument18 pagesMathematical Thinking Skills of BSED-Math Students: Its Relationship To Study Habits and Utilization of SchoologyPsychology and Education: A Multidisciplinary JournalNo ratings yet
- Maxillofacial Anatomy: Rachmanda Haryo Wibisono Hendra Benyamin Joana de FatimaDocument47 pagesMaxillofacial Anatomy: Rachmanda Haryo Wibisono Hendra Benyamin Joana de FatimaDipo Mas SuyudiNo ratings yet
- Hearts of Care Community Hospital Project ProposalDocument33 pagesHearts of Care Community Hospital Project ProposalWALGEN TRADINGNo ratings yet
- Siwes ReportDocument26 pagesSiwes ReportdavidgrcaemichaelNo ratings yet
- Ascension 2014 01Document14 pagesAscension 2014 01José SmitNo ratings yet
- Biogas:: HistoryDocument6 pagesBiogas:: HistorysarayooNo ratings yet
- Final Paper Group 4Document38 pagesFinal Paper Group 4Denise RoyNo ratings yet
- Badugu VaraKumar PLSQLDocument5 pagesBadugu VaraKumar PLSQLNavya DasariNo ratings yet
- Excessive Generation of Ideas That Can Forever: Generating Ideas For BusinessDocument23 pagesExcessive Generation of Ideas That Can Forever: Generating Ideas For BusinessMary PulumbaritNo ratings yet
- (Milan Zeleny) Human Systems Management IntegratiDocument484 pages(Milan Zeleny) Human Systems Management IntegratiakselNo ratings yet























































































Download as pdf or txt
You might also like
- Module 2Document46 pagesModule 2tarunkumarsj117No ratings yet
- Honda CRV CR-V Radio Connector PinsDocument17 pagesHonda CRV CR-V Radio Connector Pinsdonald nugrahaNo ratings yet
- Prestige Medical Classic 2100 ManualDocument72 pagesPrestige Medical Classic 2100 Manualwael26724734083No ratings yet
- CXL Over Ethernet A Novel FPGA-based MemoryDocument9 pagesCXL Over Ethernet A Novel FPGA-based Memoryy18864773539No ratings yet
- Combining Memory and A Controller With Photonics Through 3D-Stacking To Enable Scalable and Energy-Efficient SystemsDocument12 pagesCombining Memory and A Controller With Photonics Through 3D-Stacking To Enable Scalable and Energy-Efficient SystemsSuman SamuiNo ratings yet
- 3D IC Architecture For High Density MemoriesDocument6 pages3D IC Architecture For High Density MemoriesUllasNo ratings yet
- Sdram JRNDocument15 pagesSdram JRNThanh Tùng CaoNo ratings yet
- Multiply Accumulate Operations in Memristor Crossbar Arrays Foranalog ComputingDocument22 pagesMultiply Accumulate Operations in Memristor Crossbar Arrays Foranalog ComputingMohammed Siyad BNo ratings yet
- Corona: System Implications of Emerging Nanophotonic TechnologyDocument12 pagesCorona: System Implications of Emerging Nanophotonic TechnologyshoaebNo ratings yet
- Towards Integration of A Dedicated Memory ControllDocument11 pagesTowards Integration of A Dedicated Memory ControllBilal KhanNo ratings yet
- High-Throughput Pattern Matching WithDocument14 pagesHigh-Throughput Pattern Matching WithDr. Ruqaiya KhanamNo ratings yet
- Toward Dark Silicon in Servers: Kashif RabbaniDocument4 pagesToward Dark Silicon in Servers: Kashif RabbaniKashif RabbaniNo ratings yet
- A Ferroelectric FET-Based Processing-In-Memory ArcDocument8 pagesA Ferroelectric FET-Based Processing-In-Memory ArcFlavia Monica RodriguesNo ratings yet
- 7 PBDocument8 pages7 PBPV sushmithaNo ratings yet
- Compare Performance of 2D and 3D Mesh Architectures in Network-On-ChipDocument5 pagesCompare Performance of 2D and 3D Mesh Architectures in Network-On-ChipJournal of ComputingNo ratings yet
- Reconfigurable 2T2R ReRAM Architecture For Versatile Data Storage and Computing In-MemoryDocument14 pagesReconfigurable 2T2R ReRAM Architecture For Versatile Data Storage and Computing In-Memory莊昆霖No ratings yet
- Computer Architecture Unit 4Document8 pagesComputer Architecture Unit 4Santhanalakshmi SekharNo ratings yet
- 10 1109@tcsii 2020 3013336Document5 pages10 1109@tcsii 2020 3013336Kleber OliveiraNo ratings yet
- 10125-2002 CSVT On The Data Reuse and Memory Bandwidth Analysis For Full-Search Block-Matching VLSI ArchitectureDocument12 pages10125-2002 CSVT On The Data Reuse and Memory Bandwidth Analysis For Full-Search Block-Matching VLSI Architecturenavakanth4592706No ratings yet
- Hardware Memory Management For Future Mobile Hybrid Memory SystemsDocument11 pagesHardware Memory Management For Future Mobile Hybrid Memory SystemsMansoor GoharNo ratings yet
- Nand 20250474Document6 pagesNand 20250474HarikrishnaChinthalaboyinaNo ratings yet
- Neuro-Memristive Circuits For Edge Computing: A ReviewDocument20 pagesNeuro-Memristive Circuits For Edge Computing: A ReviewMax LorenNo ratings yet
- 10T SRAM Computing-in-Memory Macros For Binary andDocument15 pages10T SRAM Computing-in-Memory Macros For Binary and그랬구나No ratings yet
- 1506 02626 PDFDocument9 pages1506 02626 PDFdakshNo ratings yet
- Mira PDFDocument11 pagesMira PDFCecilia ChinnaNo ratings yet
- 21EC52 Module 2Document46 pages21EC52 Module 21 1No ratings yet
- Electronics 12 00834Document15 pagesElectronics 12 00834Dat Nguyen ThanhNo ratings yet
- AreviewonSRAM Basedcomputingin Memory Circuitsfunctionsandapplications3Document27 pagesAreviewonSRAM Basedcomputingin Memory Circuitsfunctionsandapplications3예민욱No ratings yet
- What's Up With The Storage Hierarchy?: 2. Design GoalsDocument2 pagesWhat's Up With The Storage Hierarchy?: 2. Design GoalsKevin MarcusNo ratings yet
- ED Proof: A Modular Approach To Design Ternary Content Addressable Memory Architecture in Quantum Dot Cellular AutomataDocument7 pagesED Proof: A Modular Approach To Design Ternary Content Addressable Memory Architecture in Quantum Dot Cellular AutomataPrashant RawatNo ratings yet
- Distributed Beamforming Techniques For Cell-Free Wireless Networks Using Deep Reinforcement LearningDocument16 pagesDistributed Beamforming Techniques For Cell-Free Wireless Networks Using Deep Reinforcement Learningwho3No ratings yet
- A Memristor As Multi-Bit Memory: Feasibility Analysis: Ori BASS, Alexander FISH, Doron NAVEHDocument6 pagesA Memristor As Multi-Bit Memory: Feasibility Analysis: Ori BASS, Alexander FISH, Doron NAVEHHussain Bin AliNo ratings yet
- A Logic-Compatible EDRAM Compute-In-Memory With Embedded ADCs For Processing Neural NetworksDocument13 pagesA Logic-Compatible EDRAM Compute-In-Memory With Embedded ADCs For Processing Neural NetworksHelloNo ratings yet
- Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural NetworksDocument14 pagesNeural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networksreg2regNo ratings yet
- Approximate NoC and Memory Controller Architectures For GPGPU AcceleratorsDocument15 pagesApproximate NoC and Memory Controller Architectures For GPGPU AcceleratorsMiguel Ramírez CarrilloNo ratings yet
- IEEE CEM-Looking Ahead For Resistive Memory Technology PDFDocument10 pagesIEEE CEM-Looking Ahead For Resistive Memory Technology PDFdsak199No ratings yet
- A106-Wang 0Document6 pagesA106-Wang 0ali shaarawyNo ratings yet
- Cell Multproc Comm NTWK - Built For SPDDocument14 pagesCell Multproc Comm NTWK - Built For SPDlycankNo ratings yet
- Three DIMENSIONAL-CHIPDocument6 pagesThree DIMENSIONAL-CHIPKumar Goud.KNo ratings yet
- Code Kozyraki Isca 2003Document11 pagesCode Kozyraki Isca 2003Shabad KaurNo ratings yet
- The Main Memory System: Challenges and OpportunitiesDocument26 pagesThe Main Memory System: Challenges and OpportunitiesVinay MadhavNo ratings yet
- Processor Architecture Design Using 3D Integration TechnologyDocument6 pagesProcessor Architecture Design Using 3D Integration TechnologyMilo MiloNo ratings yet
- Self Aware Memory Management For Emerging Energy Efficient ArchitecturesDocument8 pagesSelf Aware Memory Management For Emerging Energy Efficient ArchitecturessoniathalavoorNo ratings yet
- A Classy Memory Management System CyM2SDocument7 pagesA Classy Memory Management System CyM2SJNarigonNo ratings yet
- Performance Comparison of 3D-Mesh and 3D-Torus Network-on-ChipDocument5 pagesPerformance Comparison of 3D-Mesh and 3D-Torus Network-on-ChipJournal of ComputingNo ratings yet
- Structured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong SungDocument11 pagesStructured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong Sungali shaarawyNo ratings yet
- Memory Performance and Scalability of Intel's and AMD's Dual-Core Processors - A Case StudyDocument10 pagesMemory Performance and Scalability of Intel's and AMD's Dual-Core Processors - A Case StudyAnonymous Wu14iV9dqNo ratings yet
- Overview of 3D Architecture Design Opportunities and TechniquesDocument6 pagesOverview of 3D Architecture Design Opportunities and TechniquesPramod Reddy RNo ratings yet
- Demystifying CXL Memory With Genuine CXL Ready Systems and DevicesDocument12 pagesDemystifying CXL Memory With Genuine CXL Ready Systems and Devicesy18864773539No ratings yet
- Gain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipFrom EverandGain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipNo ratings yet
- Access Pattern Based Local Memory Customization For Low Power Embedded SystemsDocument7 pagesAccess Pattern Based Local Memory Customization For Low Power Embedded SystemsFarheen AsifNo ratings yet
- RBC A Memory Architecture For Improved Performance and Energy EfficiencyDocument14 pagesRBC A Memory Architecture For Improved Performance and Energy EfficiencyMUHAMMAD SAQIB SHABBIR UnknownNo ratings yet
- Openram: An Open-Source Memory CompilerDocument6 pagesOpenram: An Open-Source Memory CompilerGATE 2019No ratings yet
- Design and Operation of Energy-Aware Wireless Sensor Networks Through Scheduling and RoutingDocument3 pagesDesign and Operation of Energy-Aware Wireless Sensor Networks Through Scheduling and RoutingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Vesti Energy-Efficient In-Memory Computing Accelerator For Deep Neural NetworksDocument14 pagesVesti Energy-Efficient In-Memory Computing Accelerator For Deep Neural NetworksPANTHADIP MAJINo ratings yet
- A Case For CXL-Centric Sever ProcessorsDocument13 pagesA Case For CXL-Centric Sever Processorsy18864773539No ratings yet
- MM 3Document11 pagesMM 3Doğuş KantarciNo ratings yet
- Hybrid Memory Cube New DRAM Architecture Increases Density and PerformanceDocument2 pagesHybrid Memory Cube New DRAM Architecture Increases Density and PerformanceLauri P. Laux Jr.No ratings yet
- Fast Decoding ECC For Future MemoriesDocument12 pagesFast Decoding ECC For Future MemoriesMihir SahaNo ratings yet
- Latest Technologies To Enhance The Performance of MemoriesDocument5 pagesLatest Technologies To Enhance The Performance of MemoriesSajid UmarNo ratings yet
- A New Reference Frame Recompression Algorithm and Its VLSI Architecture For UHDTV Video CodecDocument10 pagesA New Reference Frame Recompression Algorithm and Its VLSI Architecture For UHDTV Video Codecdev- ledumNo ratings yet
- Distributed Clustering in Ad-Hoc Sensor Networks: A Hybrid, Energy-Efficient ApproachDocument12 pagesDistributed Clustering in Ad-Hoc Sensor Networks: A Hybrid, Energy-Efficient ApproachNivedita Acharyya 2035No ratings yet
- Donau CarbonDocument2 pagesDonau CarbonLim Chee SiangNo ratings yet
- 4 Inventory Management and Risk PoolingDocument54 pages4 Inventory Management and Risk PoolingSpandana AchantaNo ratings yet
- Format For CompilationDocument3 pagesFormat For CompilationPrincess Mia CristobalNo ratings yet
- Bmj-2021-069211.full Reduce Unnecessary Use of Proton Pump InhibitorsDocument7 pagesBmj-2021-069211.full Reduce Unnecessary Use of Proton Pump InhibitorsYo MeNo ratings yet
- Case 10 (Post-Operative Pain Management & Complication)Document10 pagesCase 10 (Post-Operative Pain Management & Complication)ReddyNo ratings yet
- Copper Manufacturing Process: General Flowsheet of ProcessDocument28 pagesCopper Manufacturing Process: General Flowsheet of ProcessflaviosazevedoNo ratings yet
- Compact Wideband Dual-Band Polarization and Pattern Diversity Antenna For Vehicle CommunicationsDocument6 pagesCompact Wideband Dual-Band Polarization and Pattern Diversity Antenna For Vehicle CommunicationsAnil NayakNo ratings yet
- i30-Drive-N-Limited-EditioN-Product BulletinDocument2 pagesi30-Drive-N-Limited-EditioN-Product BulletinYaxuan ZhuNo ratings yet
- WE503 IndicatorDocument1 pageWE503 IndicatorWANSNo ratings yet
- SAIL Challenges of Single Cell and Spatial ExperimentsDocument54 pagesSAIL Challenges of Single Cell and Spatial ExperimentsespartawithespartilhoNo ratings yet
- Companion Log 2018 10 10T13 44 31ZDocument15 pagesCompanion Log 2018 10 10T13 44 31ZTerbaik2u HDNo ratings yet
- Mystical Kashmir Vacation - With Houseboat Stay (14!04!2023T20 - 50) - QuoteId-25446607Document14 pagesMystical Kashmir Vacation - With Houseboat Stay (14!04!2023T20 - 50) - QuoteId-25446607time delhiNo ratings yet
- SW 500Document28 pagesSW 500Sujit KumarNo ratings yet
- Gurukul Hindi e Book by Sirhud KalraDocument17 pagesGurukul Hindi e Book by Sirhud KalraPARVANo ratings yet
- Big Data Analytics (2017 Regulation) : Unit - 2 Clustering and ClassificationDocument7 pagesBig Data Analytics (2017 Regulation) : Unit - 2 Clustering and ClassificationcskinitNo ratings yet
- Option B - BiochemistryDocument24 pagesOption B - BiochemistryRosaNo ratings yet
- TMV Trading PricelistDocument8 pagesTMV Trading Pricelistronald s. rodrigoNo ratings yet
- Research Paper Topics Oliver TwistDocument4 pagesResearch Paper Topics Oliver Twistnikuvivakuv3100% (1)
- Mathematical Thinking Skills of BSED-Math Students: Its Relationship To Study Habits and Utilization of SchoologyDocument18 pagesMathematical Thinking Skills of BSED-Math Students: Its Relationship To Study Habits and Utilization of SchoologyPsychology and Education: A Multidisciplinary JournalNo ratings yet
- Maxillofacial Anatomy: Rachmanda Haryo Wibisono Hendra Benyamin Joana de FatimaDocument47 pagesMaxillofacial Anatomy: Rachmanda Haryo Wibisono Hendra Benyamin Joana de FatimaDipo Mas SuyudiNo ratings yet
- Hearts of Care Community Hospital Project ProposalDocument33 pagesHearts of Care Community Hospital Project ProposalWALGEN TRADINGNo ratings yet
- Siwes ReportDocument26 pagesSiwes ReportdavidgrcaemichaelNo ratings yet
- Ascension 2014 01Document14 pagesAscension 2014 01José SmitNo ratings yet
- Biogas:: HistoryDocument6 pagesBiogas:: HistorysarayooNo ratings yet
- Final Paper Group 4Document38 pagesFinal Paper Group 4Denise RoyNo ratings yet
- Badugu VaraKumar PLSQLDocument5 pagesBadugu VaraKumar PLSQLNavya DasariNo ratings yet
- Excessive Generation of Ideas That Can Forever: Generating Ideas For BusinessDocument23 pagesExcessive Generation of Ideas That Can Forever: Generating Ideas For BusinessMary PulumbaritNo ratings yet
- (Milan Zeleny) Human Systems Management IntegratiDocument484 pages(Milan Zeleny) Human Systems Management IntegratiakselNo ratings yet