Download as pdf or txt
You might also like
- Interlace Tumblr ThemeDocument39 pagesInterlace Tumblr ThemejamesNo ratings yet
- 237 242 437 537 542 Firmware Update Instructions enDocument6 pages237 242 437 537 542 Firmware Update Instructions enRichard Gobeille0% (1)
- Ephesus SlidesCarnivalDocument43 pagesEphesus SlidesCarnivalAr CondeNo ratings yet
- What Is Engineering PresentationDocument12 pagesWhat Is Engineering PresentationJimmy ThomasNo ratings yet
- q4 Itik PPT FinalDocument20 pagesq4 Itik PPT FinalEbs DandaNo ratings yet
- CDSS Day-3Document207 pagesCDSS Day-3junitasariNo ratings yet
- Lab Course File: Course Code:-Bcse2014 Room No.Document35 pagesLab Course File: Course Code:-Bcse2014 Room No.Akshay Maan07No ratings yet
- NPD Models Role of Information and Idea Generation For NPD: Session 2Document31 pagesNPD Models Role of Information and Idea Generation For NPD: Session 2Hina SaadNo ratings yet
- Timeseriesdatabases NewwaystostoreandaccessdataDocument81 pagesTimeseriesdatabases NewwaystostoreandaccessdataAgnes Lilla SzakacsNo ratings yet
- Madhavakrishnan.S 10E Term2 E-Record (2022-2021)Document33 pagesMadhavakrishnan.S 10E Term2 E-Record (2022-2021)Madhavkrishnan SNo ratings yet
- CS423 Data Warehousing and Data Mining: Dr. Hammad AfzalDocument31 pagesCS423 Data Warehousing and Data Mining: Dr. Hammad AfzalZafar IqbalNo ratings yet
- Data Mining: Some Slide Material Taken From: Groth, Han and Kamber, SAS InstituteDocument58 pagesData Mining: Some Slide Material Taken From: Groth, Han and Kamber, SAS InstituteRaj MohanNo ratings yet
- The Belief-Desire-Intention Model of Agency: Georgeff@aaii - Oz.auDocument10 pagesThe Belief-Desire-Intention Model of Agency: Georgeff@aaii - Oz.auPiotrFronczewskiNo ratings yet
- Graphics and Design - PresentationDocument23 pagesGraphics and Design - PresentationRocio A RubecindoNo ratings yet
- ABC ChinaDocument71 pagesABC ChinaHeri SaxoNo ratings yet
- Data MiningDocument26 pagesData MiningAnil HegdeNo ratings yet
- Lecture 2Document27 pagesLecture 2Muhammad Nawaz AwanNo ratings yet
- Augmented Reality Quiz: Presented By-Abhishekh Mishra 1220439014Document37 pagesAugmented Reality Quiz: Presented By-Abhishekh Mishra 1220439014Aman MishraNo ratings yet
- Brief 49024 52918 28102015917512011nguyendangbinh - UngdungphuongphapmohinhdongdangvaphantichthunguyenDocument3 pagesBrief 49024 52918 28102015917512011nguyendangbinh - UngdungphuongphapmohinhdongdangvaphantichthunguyenHương Vũ QuỳnhNo ratings yet
- Big Data in Planetary Science: A Presentation by Amirtha Varshini Harini Keerthirajan Partha SarathiDocument33 pagesBig Data in Planetary Science: A Presentation by Amirtha Varshini Harini Keerthirajan Partha SarathiNv BvNo ratings yet
- Curriculum Vitae - Robi Perdiansyah PutraDocument2 pagesCurriculum Vitae - Robi Perdiansyah PutraRoby perdiansyah PutraNo ratings yet
- AI STD 10 Part B Unit 4Document25 pagesAI STD 10 Part B Unit 4Prabhat KumarNo ratings yet
- 1 Basic ConceptsDocument20 pages1 Basic ConceptsAmrit Preet KaurNo ratings yet
- What Is Engineering?Document14 pagesWhat Is Engineering?jayanthiNo ratings yet
- Career Development: Class 2 - Zeeta MaharajDocument62 pagesCareer Development: Class 2 - Zeeta MaharajVenkat VenkatNo ratings yet
- BarrocaKoriaLindMulas2017FrontEnd Tool Kit PDFDocument93 pagesBarrocaKoriaLindMulas2017FrontEnd Tool Kit PDFMansonia Equipamientos en maderaNo ratings yet
- 1 English For Information Technology Elementa-51-60Document10 pages1 English For Information Technology Elementa-51-60HERRERANo ratings yet
- How Can Design Thinking Speed Up InnovationDocument56 pagesHow Can Design Thinking Speed Up InnovationMishelle DueñasNo ratings yet
- Class 2 DPDocument17 pagesClass 2 DPrajeshmanamNo ratings yet
- Lecture 1 Introduction To Data MiningDocument42 pagesLecture 1 Introduction To Data MiningAsma Batool NaqviNo ratings yet
- Inquiries, Investigations Inquiries, Investigations and Immersion and ImmersionDocument18 pagesInquiries, Investigations Inquiries, Investigations and Immersion and ImmersionChristian DequilatoNo ratings yet
- Problem Space WorkshopDocument33 pagesProblem Space WorkshopMohamed Ahmed RammadanNo ratings yet
- Data Analytics Forum 10.12.17Document19 pagesData Analytics Forum 10.12.17Rudra GandhiNo ratings yet
- Week 2 - Ideation and Creative Problem SolvingDocument38 pagesWeek 2 - Ideation and Creative Problem SolvingKkimm ChiiNo ratings yet
- Obreros: 2 TimoteoDocument46 pagesObreros: 2 TimoteoMaríaNo ratings yet
- Curriculum Development of The Hilda Taba Model in Digital LiteracyDocument25 pagesCurriculum Development of The Hilda Taba Model in Digital LiteracyDevy Yulistiawati UtomoNo ratings yet
- Migration Resource CalculatorDocument8 pagesMigration Resource CalculatorPatrick Ferdinand AlvarezNo ratings yet
- ACC-157 (Module 10-16)Document38 pagesACC-157 (Module 10-16)Vitany Gyn Cabalfin TraifalgarNo ratings yet
- Research Paper On Data Mining 2014 PDFDocument6 pagesResearch Paper On Data Mining 2014 PDFafnhemzabfueaa100% (1)
- 2013 Data Science Salary Survey: Tools, Trends, What Pays (And What Doesn't) For Data ProfessionalsDocument23 pages2013 Data Science Salary Survey: Tools, Trends, What Pays (And What Doesn't) For Data ProfessionalsJesús BravoNo ratings yet
- 2019 - Park - Estimating Node Importance in Knowledge Graphs Using Graph Neural NetworksDocument11 pages2019 - Park - Estimating Node Importance in Knowledge Graphs Using Graph Neural NetworkslgmoyanoNo ratings yet
- Augmented Reality: Dream App or Disaster For Cities??8 Oct 2009Document49 pagesAugmented Reality: Dream App or Disaster For Cities??8 Oct 2009api-26178594No ratings yet
- Big DataDocument23 pagesBig Dataarshpreetmundra14No ratings yet
- G4 - Publishing ICT ProjectsDocument23 pagesG4 - Publishing ICT Projectsmialicera3No ratings yet
- IDS Sec-1 CS1-CS8 Merged SlidesDocument419 pagesIDS Sec-1 CS1-CS8 Merged Slidessourab jainNo ratings yet
- Lecture 1.1 SlidesDocument54 pagesLecture 1.1 Slidessindhuk55No ratings yet
- Monday - IR Fundamentals - Grace Yang - AFIRM19-IRDocument77 pagesMonday - IR Fundamentals - Grace Yang - AFIRM19-IRlekha.cceNo ratings yet
- Learning English by Project Based Learning : Exploring The Traditions and Nature of BaliDocument12 pagesLearning English by Project Based Learning : Exploring The Traditions and Nature of Baliamaliaazizah134100% (1)
- M2 - 55348A - Administering Microsoft Endpoint Configuration Manager - SkillpipeDocument23 pagesM2 - 55348A - Administering Microsoft Endpoint Configuration Manager - SkillpipeDepolo PoloNo ratings yet
- Information Quality PDFDocument112 pagesInformation Quality PDFArmando EscotoNo ratings yet
- Equiv Ta Decimal Number To Binary NumberDocument14 pagesEquiv Ta Decimal Number To Binary Numberdumittemmodu-9871No ratings yet
- I I T Kanpur: Desi GN ProgrammeDocument12 pagesI I T Kanpur: Desi GN ProgrammePushkar AwasthiNo ratings yet
- RainbowDocument40 pagesRainbowLyne Daguplo MulitNo ratings yet
- Technology GregDocument2 pagesTechnology Greggrandolph8No ratings yet
- Project Module BDocument20 pagesProject Module Bhayaton408No ratings yet
- Ontology SeminarDocument95 pagesOntology SeminarAmrutNo ratings yet
- Pattern RecognitionDocument32 pagesPattern Recognitionsomya mathurNo ratings yet
- Code - May June 2024Document76 pagesCode - May June 2024ashokvedNo ratings yet
- Cristo en COlosensesDocument45 pagesCristo en COlosensesMaríaNo ratings yet
- Ingles 5 Modulo 4Document24 pagesIngles 5 Modulo 4eduardo crakNo ratings yet
- Mis Module 2Document33 pagesMis Module 2mohammedansil791No ratings yet
- Computer Programming: A Simplified Entry to Python, Java, and C++ Programming for BeginnersFrom EverandComputer Programming: A Simplified Entry to Python, Java, and C++ Programming for BeginnersNo ratings yet
- 23eng Pde1Document5 pages23eng Pde1Kristóf KássaNo ratings yet
- CircuitDocument13 pagesCircuitKristóf KássaNo ratings yet
- 2023márc MűegyLabIntroDocument25 pages2023márc MűegyLabIntroKristóf KássaNo ratings yet
- Python - A Tool For Percolation Analysis in Triangular LatticeDocument4 pagesPython - A Tool For Percolation Analysis in Triangular LatticeKristóf KássaNo ratings yet
- Using FTP Adapter Oracle Integration PDFDocument46 pagesUsing FTP Adapter Oracle Integration PDFsureshretekNo ratings yet
- Lecture's Objectives /1 - SQL: Dr. Ala Al-ZobaidieDocument7 pagesLecture's Objectives /1 - SQL: Dr. Ala Al-ZobaidietruciousNo ratings yet
- DebugDocument13 pagesDebugwsosaNo ratings yet
- Computer Lab Rules and RegulationsDocument5 pagesComputer Lab Rules and RegulationsMirasol Baring100% (1)
- Spring Hibernate JSF Primefaces IntergrationDocument21 pagesSpring Hibernate JSF Primefaces IntergrationHuy Quan VuNo ratings yet
- Traditional Process ModelsDocument23 pagesTraditional Process ModelsHassam ShahidNo ratings yet
- Rubina Pradhan: Dev0psDocument4 pagesRubina Pradhan: Dev0psVishal JainNo ratings yet
- MVC Architecture in OAFDocument2 pagesMVC Architecture in OAFAjay TulseNo ratings yet
- Document Review and Approval Application DesignDocument37 pagesDocument Review and Approval Application DesignSubhashNo ratings yet
- 7th Sem Web Programming Lab Viva Questions and Answers PDFDocument5 pages7th Sem Web Programming Lab Viva Questions and Answers PDFSWATHI ACHARYA 105100% (1)
- Export Import For StudentsDocument7 pagesExport Import For StudentsMithun Sarker100% (1)
- 1939 PLMEurope 25.10.17-10-30 Alex-Van-Der-Linden ASML Road To Change Management in Teamcenter PDFDocument56 pages1939 PLMEurope 25.10.17-10-30 Alex-Van-Der-Linden ASML Road To Change Management in Teamcenter PDFJoshua DanielNo ratings yet
- Dragon Med Practice - UserguideDocument126 pagesDragon Med Practice - UserguideDZeiglerNo ratings yet
- Aafaaq OBIEE AdminDocument7 pagesAafaaq OBIEE AdminBhimavarapu RamiReddyNo ratings yet
- Tipe LaptopDocument30 pagesTipe LaptoprifyalNo ratings yet
- VBScript Interview QuestionsDocument4 pagesVBScript Interview Questionssachxn100% (1)
- 8 Linux Advanced File System Management m8 SlidesDocument24 pages8 Linux Advanced File System Management m8 SlidesToto RobiNo ratings yet
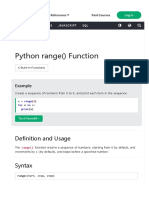
- Python Range Function: Definition and UsageDocument5 pagesPython Range Function: Definition and UsageIsac MartinsNo ratings yet
- Upgrade Oracle From 10.2.0.1 To 10.2.0.4: GoldlinkDocument6 pagesUpgrade Oracle From 10.2.0.1 To 10.2.0.4: Goldlinkyashkr2010No ratings yet
- Department of EducationDocument19 pagesDepartment of EducationJOSEPH DHEL RAQUELNo ratings yet
- Cutover MigrationDocument11 pagesCutover MigrationMukeshRawattNo ratings yet
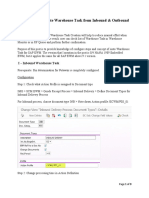
- EWM - Auto Create Warehouse Task From Inbound & OutboundDocument9 pagesEWM - Auto Create Warehouse Task From Inbound & Outboundwaseem abbasNo ratings yet
- Motherboard Manual Gigabyte K8VM800M Via8237Document14 pagesMotherboard Manual Gigabyte K8VM800M Via8237Paul JavierNo ratings yet
- Chapter 1.3 Operating Systems 1 - Windows, MacOS, Linux, Chrome, Android, iOSDocument53 pagesChapter 1.3 Operating Systems 1 - Windows, MacOS, Linux, Chrome, Android, iOSM. Michael GuelcanNo ratings yet
- YAT Release NotesDocument43 pagesYAT Release NotesAchmad HanifNo ratings yet
- AsasasasasaDocument27 pagesAsasasasasaSivaReddyNo ratings yet
- Determination of Molecular Radius of Glycerol Molecule by Using R SoftwareDocument5 pagesDetermination of Molecular Radius of Glycerol Molecule by Using R SoftwareGustavo Dos SantosNo ratings yet
- EXCEL To Tally LeggerImport-ok - 2Document7 pagesEXCEL To Tally LeggerImport-ok - 2Mukesh MakadiaNo ratings yet