
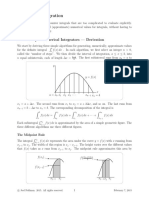
Chapter9-Parallel Distributed Algorithm
Chapter9-Parallel Distributed Algorithm
You might also like
- Solutions - An Introduction To ManifoldsDocument79 pagesSolutions - An Introduction To ManifoldsNoel Banton100% (11)
- IEOR E4007 November 24, 2021 G. IyengarDocument9 pagesIEOR E4007 November 24, 2021 G. IyengarKiKi ChenNo ratings yet
- A Comparison of Interior Point and SQP Methods On Optimal Control ProblemsDocument57 pagesA Comparison of Interior Point and SQP Methods On Optimal Control ProblemssamandondonNo ratings yet
- Gradient Decent - PDF 2Document7 pagesGradient Decent - PDF 2fidha salahudeenNo ratings yet
- 2010 AIP PradeepDocument12 pages2010 AIP PradeepICMAA 2016No ratings yet
- Monte Carlo Methods PrimerDocument4 pagesMonte Carlo Methods PrimerMrDubsterNo ratings yet
- A Generalization of Radon's Inequality: D M. B - G and O T. PDocument5 pagesA Generalization of Radon's Inequality: D M. B - G and O T. PFustei BogdanNo ratings yet
- The Dirichlet Series That Generates The M Obius Function Is The Inverse of The Riemann Zeta Function in The Right Half of The Critical StripDocument7 pagesThe Dirichlet Series That Generates The M Obius Function Is The Inverse of The Riemann Zeta Function in The Right Half of The Critical Stripsmith tomNo ratings yet
- 13 Generalized Programming and Subgradient Optimization PDFDocument20 pages13 Generalized Programming and Subgradient Optimization PDFAbrar HashmiNo ratings yet
- Lagrange MultDocument5 pagesLagrange Multshambel ZnabuNo ratings yet
- HRSAT82 (Honours Research in Astronomy)Document8 pagesHRSAT82 (Honours Research in Astronomy)Mpho MokanyaneNo ratings yet
- Point Particle QuantizationDocument11 pagesPoint Particle QuantizationSarthak0% (1)
- Review 3Document14 pagesReview 3Bharath SNo ratings yet
- ART Onvex OptimizationDocument16 pagesART Onvex OptimizationAn Son DangNo ratings yet
- Exact and Approximate Expressions For The Period of Anharmonic OscillatorsDocument11 pagesExact and Approximate Expressions For The Period of Anharmonic OscillatorsjeremyNo ratings yet
- Analysis II MS Sol 2015-16Document3 pagesAnalysis II MS Sol 2015-16Mainak SamantaNo ratings yet
- Examples of Manifolds: 1 n+1 N n+1 1 n+1 N n+1Document5 pagesExamples of Manifolds: 1 n+1 N n+1 1 n+1 N n+1kienkienNo ratings yet
- 08 Solution Heat Equation ExplicitDocument3 pages08 Solution Heat Equation ExplicitPondok HudaNo ratings yet
- The Method of Lagrange MultipliersDocument5 pagesThe Method of Lagrange MultipliersjesusNo ratings yet
- StudyGuideFinalExamFall2022 Purdue MA165Document17 pagesStudyGuideFinalExamFall2022 Purdue MA165Thomas sNo ratings yet
- Lecture 9Document8 pagesLecture 9Gordian HerbertNo ratings yet
- On Fitting Models For Danish Fire DataDocument49 pagesOn Fitting Models For Danish Fire Dataivancito8No ratings yet
- 1 Mathematical Preliminaries 2Document17 pages1 Mathematical Preliminaries 2shubhamNo ratings yet
- 23 Lect DualAlgoDocument51 pages23 Lect DualAlgozhongyu xiaNo ratings yet
- Speech Prediction (029-031)Document12 pagesSpeech Prediction (029-031)prathikNo ratings yet
- An Algorithm For Computing Risk Parity Weights - F. SpinuDocument6 pagesAn Algorithm For Computing Risk Parity Weights - F. SpinucastjamNo ratings yet
- 18.650 Statistics For ApplicationsDocument15 pages18.650 Statistics For ApplicationsbobNo ratings yet
- Expectation Values of Operators: Lecture Notes: QM 04Document8 pagesExpectation Values of Operators: Lecture Notes: QM 04Anum Hosen ShawonNo ratings yet
- 4.6. Representation of Functions As Power Series 99Document3 pages4.6. Representation of Functions As Power Series 99FernandoFierroGonzalezNo ratings yet
- Numerical PDFDocument19 pagesNumerical PDFDharmapaljungNo ratings yet
- Lecture 13Document7 pagesLecture 13FM KhanNo ratings yet
- Total Variation Norm Regularized Least Square: I.E. Minimize Kax BK + KDXK Where KDXK Is Not ProximableDocument12 pagesTotal Variation Norm Regularized Least Square: I.E. Minimize Kax BK + KDXK Where KDXK Is Not ProximableDisi LinNo ratings yet
- Acceleration Methods: Aitken's MethodDocument5 pagesAcceleration Methods: Aitken's MethodOubelaid AdelNo ratings yet
- DeltaDocument3 pagesDeltasupergravity66No ratings yet
- GR Exercise 1Document4 pagesGR Exercise 1Keshav PrasadNo ratings yet
- Lect 18 PDFDocument10 pagesLect 18 PDFwin alfalahNo ratings yet
- 18 ScisDocument12 pages18 Scisdark liuNo ratings yet
- Hu2010 Article IterationCalculationsOfPeriodiDocument6 pagesHu2010 Article IterationCalculationsOfPeriodiIdris anderson Dzeugoua DjibouengNo ratings yet
- A New Proof of A Classical FormulaDocument5 pagesA New Proof of A Classical FormulaKonstantinos MichailidisNo ratings yet
- Week 1Document15 pagesWeek 1ziyue wangNo ratings yet
- Problem Sheet On Green's FunctionsDocument3 pagesProblem Sheet On Green's FunctionsGiorgio LiNo ratings yet
- , x, - . -, x f (x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, σ, - . -, σ ∈Document5 pages, x, - . -, x f (x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, σ, - . -, σ ∈guido360No ratings yet
- Derivative RulesDocument8 pagesDerivative RuleslukeNo ratings yet
- C 06 Anti DifferentiationDocument31 pagesC 06 Anti Differentiationebrahimipour1360No ratings yet
- AM12 Optimization 2 HandoutDocument27 pagesAM12 Optimization 2 Handout张舒No ratings yet
- Propagator Greens Function in Quantum MeDocument3 pagesPropagator Greens Function in Quantum Metoby122No ratings yet
- Lecture 7Document10 pagesLecture 7mingkit.2021No ratings yet
- Mathematics Formulary PDFDocument30 pagesMathematics Formulary PDFfizarimaeNo ratings yet
- FALLSEM2023-24 SWE1002 TH VL2023240103269 2023-10-25 Reference-Material-IIIDocument6 pagesFALLSEM2023-24 SWE1002 TH VL2023240103269 2023-10-25 Reference-Material-IIIKartik SoniNo ratings yet
- Robert J. Lemke OliverDocument6 pagesRobert J. Lemke OliverDipendranath MahatoNo ratings yet
- MATH 115: Lecture XXVIII NotesDocument3 pagesMATH 115: Lecture XXVIII NotesDylan C. BeckNo ratings yet
- Calculus2014 Lecturenote 10 9Document8 pagesCalculus2014 Lecturenote 10 9盧思宇No ratings yet
- FixedpointDocument5 pagesFixedpointAnuradha yadavNo ratings yet
- Regularization of Derivatives by Fractional VelocityDocument5 pagesRegularization of Derivatives by Fractional VelocityDimiter ProdanovNo ratings yet
- FemDocument165 pagesFemmeda012No ratings yet
- Laguerre Polynomials - NormalizationDocument4 pagesLaguerre Polynomials - NormalizationMassimiliano NaldiNo ratings yet
- Kelly Portfolio OptimizationDocument19 pagesKelly Portfolio OptimizationRiccardo RoncoNo ratings yet
- Lecture Notes: Metric Spaces - Sergey MozgovoyDocument41 pagesLecture Notes: Metric Spaces - Sergey MozgovoyNúñezNo ratings yet
- Math 111Document163 pagesMath 111John Fritz SinghNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Heuristics For The Combined Cut Order Planning Two-Dimensional Layout Problem in The Apparel IndustryDocument33 pagesHeuristics For The Combined Cut Order Planning Two-Dimensional Layout Problem in The Apparel IndustryDÃljït SīñghNo ratings yet
- Algoritmo SQPDocument17 pagesAlgoritmo SQPGeno KronosNo ratings yet
- Math Constrained Optimization I FocDocument44 pagesMath Constrained Optimization I Focarm.unfurledNo ratings yet
- Methods To Manage and Optimize Forest Biomass Supply Chains - A ReviewDocument18 pagesMethods To Manage and Optimize Forest Biomass Supply Chains - A ReviewJuan David Gomez QuicenoNo ratings yet
- Assignment ProblemDocument32 pagesAssignment ProblemPunitValaNo ratings yet
- LP FormulationDocument40 pagesLP FormulationpranjalNo ratings yet
- Algorithm Analysis and Design PDFDocument190 pagesAlgorithm Analysis and Design PDFtheresNo ratings yet
- Microeconomic Analysis NotesDocument23 pagesMicroeconomic Analysis NotesMinira JafarovaNo ratings yet
- 7th Sem SyllabusDocument14 pages7th Sem SyllabusS D ManjunathNo ratings yet
- Schedule Float Analysis PDFDocument159 pagesSchedule Float Analysis PDFmohit16587No ratings yet
- Cloth 2 TexDocument15 pagesCloth 2 TexrakeshsinghpariharNo ratings yet
- ME 7th SemDocument6 pagesME 7th SemShaleen SharmaNo ratings yet
- Chapter 12 - Aggregate PlanningDocument4 pagesChapter 12 - Aggregate Planninghello_khay100% (2)
- Heuristics Vs OptimizationDocument3 pagesHeuristics Vs OptimizationshyamsakhareNo ratings yet
- Introduction To: Artificial IntelligenceDocument86 pagesIntroduction To: Artificial IntelligenceSyed Ali Faiez ZaidiNo ratings yet
- Honeywell APC Ethanol Case StudyDocument3 pagesHoneywell APC Ethanol Case StudymelvokingNo ratings yet
- CIM Assignment 6Document3 pagesCIM Assignment 6Abuzar AliNo ratings yet
- Simsched Direct Block Scheduler: A New Practical Algorithm For The Open Pit Mine Production Scheduling ProblemDocument8 pagesSimsched Direct Block Scheduler: A New Practical Algorithm For The Open Pit Mine Production Scheduling ProblemValentín Ibarra GonzalezNo ratings yet
- Syllabus-IE 101 Operations ResearchDocument3 pagesSyllabus-IE 101 Operations ResearchJourdan KanNo ratings yet
- Open Nucleus Breeding SystemsDocument18 pagesOpen Nucleus Breeding SystemsMisbakhul BadriNo ratings yet
- Fibonnaci Sequence (Golden Rule)Document12 pagesFibonnaci Sequence (Golden Rule)rbmalasaNo ratings yet
- Steve Sashihara's PresentationDocument34 pagesSteve Sashihara's PresentationHossam AhmedNo ratings yet
- Sequencing Problems Processing N Jobs Through 2 Machines Problem Example PDFDocument2 pagesSequencing Problems Processing N Jobs Through 2 Machines Problem Example PDFSaravana Selvakumar100% (1)
- Project Report FormatDocument14 pagesProject Report FormatAdwiteey ShishodiaNo ratings yet
- Traffic Signal Control With ACO - Thesis Renfrew PDFDocument109 pagesTraffic Signal Control With ACO - Thesis Renfrew PDFpakivermaNo ratings yet
- Chemical Engineering Plant Design: Dr. M. Azam SaeedDocument16 pagesChemical Engineering Plant Design: Dr. M. Azam SaeedMuhammad BilalNo ratings yet
- Spatial Analysis Techlectures Fall06Document138 pagesSpatial Analysis Techlectures Fall06iket100% (1)
- Free Parking Space Prediction & Reliability AnalysisDocument6 pagesFree Parking Space Prediction & Reliability AnalysisaslanNo ratings yet























































































Download as pdf or txt
You might also like
- Solutions - An Introduction To ManifoldsDocument79 pagesSolutions - An Introduction To ManifoldsNoel Banton100% (11)
- IEOR E4007 November 24, 2021 G. IyengarDocument9 pagesIEOR E4007 November 24, 2021 G. IyengarKiKi ChenNo ratings yet
- A Comparison of Interior Point and SQP Methods On Optimal Control ProblemsDocument57 pagesA Comparison of Interior Point and SQP Methods On Optimal Control ProblemssamandondonNo ratings yet
- Gradient Decent - PDF 2Document7 pagesGradient Decent - PDF 2fidha salahudeenNo ratings yet
- 2010 AIP PradeepDocument12 pages2010 AIP PradeepICMAA 2016No ratings yet
- Monte Carlo Methods PrimerDocument4 pagesMonte Carlo Methods PrimerMrDubsterNo ratings yet
- A Generalization of Radon's Inequality: D M. B - G and O T. PDocument5 pagesA Generalization of Radon's Inequality: D M. B - G and O T. PFustei BogdanNo ratings yet
- The Dirichlet Series That Generates The M Obius Function Is The Inverse of The Riemann Zeta Function in The Right Half of The Critical StripDocument7 pagesThe Dirichlet Series That Generates The M Obius Function Is The Inverse of The Riemann Zeta Function in The Right Half of The Critical Stripsmith tomNo ratings yet
- 13 Generalized Programming and Subgradient Optimization PDFDocument20 pages13 Generalized Programming and Subgradient Optimization PDFAbrar HashmiNo ratings yet
- Lagrange MultDocument5 pagesLagrange Multshambel ZnabuNo ratings yet
- HRSAT82 (Honours Research in Astronomy)Document8 pagesHRSAT82 (Honours Research in Astronomy)Mpho MokanyaneNo ratings yet
- Point Particle QuantizationDocument11 pagesPoint Particle QuantizationSarthak0% (1)
- Review 3Document14 pagesReview 3Bharath SNo ratings yet
- ART Onvex OptimizationDocument16 pagesART Onvex OptimizationAn Son DangNo ratings yet
- Exact and Approximate Expressions For The Period of Anharmonic OscillatorsDocument11 pagesExact and Approximate Expressions For The Period of Anharmonic OscillatorsjeremyNo ratings yet
- Analysis II MS Sol 2015-16Document3 pagesAnalysis II MS Sol 2015-16Mainak SamantaNo ratings yet
- Examples of Manifolds: 1 n+1 N n+1 1 n+1 N n+1Document5 pagesExamples of Manifolds: 1 n+1 N n+1 1 n+1 N n+1kienkienNo ratings yet
- 08 Solution Heat Equation ExplicitDocument3 pages08 Solution Heat Equation ExplicitPondok HudaNo ratings yet
- The Method of Lagrange MultipliersDocument5 pagesThe Method of Lagrange MultipliersjesusNo ratings yet
- StudyGuideFinalExamFall2022 Purdue MA165Document17 pagesStudyGuideFinalExamFall2022 Purdue MA165Thomas sNo ratings yet
- Lecture 9Document8 pagesLecture 9Gordian HerbertNo ratings yet
- On Fitting Models For Danish Fire DataDocument49 pagesOn Fitting Models For Danish Fire Dataivancito8No ratings yet
- 1 Mathematical Preliminaries 2Document17 pages1 Mathematical Preliminaries 2shubhamNo ratings yet
- 23 Lect DualAlgoDocument51 pages23 Lect DualAlgozhongyu xiaNo ratings yet
- Speech Prediction (029-031)Document12 pagesSpeech Prediction (029-031)prathikNo ratings yet
- An Algorithm For Computing Risk Parity Weights - F. SpinuDocument6 pagesAn Algorithm For Computing Risk Parity Weights - F. SpinucastjamNo ratings yet
- 18.650 Statistics For ApplicationsDocument15 pages18.650 Statistics For ApplicationsbobNo ratings yet
- Expectation Values of Operators: Lecture Notes: QM 04Document8 pagesExpectation Values of Operators: Lecture Notes: QM 04Anum Hosen ShawonNo ratings yet
- 4.6. Representation of Functions As Power Series 99Document3 pages4.6. Representation of Functions As Power Series 99FernandoFierroGonzalezNo ratings yet
- Numerical PDFDocument19 pagesNumerical PDFDharmapaljungNo ratings yet
- Lecture 13Document7 pagesLecture 13FM KhanNo ratings yet
- Total Variation Norm Regularized Least Square: I.E. Minimize Kax BK + KDXK Where KDXK Is Not ProximableDocument12 pagesTotal Variation Norm Regularized Least Square: I.E. Minimize Kax BK + KDXK Where KDXK Is Not ProximableDisi LinNo ratings yet
- Acceleration Methods: Aitken's MethodDocument5 pagesAcceleration Methods: Aitken's MethodOubelaid AdelNo ratings yet
- DeltaDocument3 pagesDeltasupergravity66No ratings yet
- GR Exercise 1Document4 pagesGR Exercise 1Keshav PrasadNo ratings yet
- Lect 18 PDFDocument10 pagesLect 18 PDFwin alfalahNo ratings yet
- 18 ScisDocument12 pages18 Scisdark liuNo ratings yet
- Hu2010 Article IterationCalculationsOfPeriodiDocument6 pagesHu2010 Article IterationCalculationsOfPeriodiIdris anderson Dzeugoua DjibouengNo ratings yet
- A New Proof of A Classical FormulaDocument5 pagesA New Proof of A Classical FormulaKonstantinos MichailidisNo ratings yet
- Week 1Document15 pagesWeek 1ziyue wangNo ratings yet
- Problem Sheet On Green's FunctionsDocument3 pagesProblem Sheet On Green's FunctionsGiorgio LiNo ratings yet
- , x, - . -, x f (x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, σ, - . -, σ ∈Document5 pages, x, - . -, x f (x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, x, - . -, x, σ, - . -, σ ∈guido360No ratings yet
- Derivative RulesDocument8 pagesDerivative RuleslukeNo ratings yet
- C 06 Anti DifferentiationDocument31 pagesC 06 Anti Differentiationebrahimipour1360No ratings yet
- AM12 Optimization 2 HandoutDocument27 pagesAM12 Optimization 2 Handout张舒No ratings yet
- Propagator Greens Function in Quantum MeDocument3 pagesPropagator Greens Function in Quantum Metoby122No ratings yet
- Lecture 7Document10 pagesLecture 7mingkit.2021No ratings yet
- Mathematics Formulary PDFDocument30 pagesMathematics Formulary PDFfizarimaeNo ratings yet
- FALLSEM2023-24 SWE1002 TH VL2023240103269 2023-10-25 Reference-Material-IIIDocument6 pagesFALLSEM2023-24 SWE1002 TH VL2023240103269 2023-10-25 Reference-Material-IIIKartik SoniNo ratings yet
- Robert J. Lemke OliverDocument6 pagesRobert J. Lemke OliverDipendranath MahatoNo ratings yet
- MATH 115: Lecture XXVIII NotesDocument3 pagesMATH 115: Lecture XXVIII NotesDylan C. BeckNo ratings yet
- Calculus2014 Lecturenote 10 9Document8 pagesCalculus2014 Lecturenote 10 9盧思宇No ratings yet
- FixedpointDocument5 pagesFixedpointAnuradha yadavNo ratings yet
- Regularization of Derivatives by Fractional VelocityDocument5 pagesRegularization of Derivatives by Fractional VelocityDimiter ProdanovNo ratings yet
- FemDocument165 pagesFemmeda012No ratings yet
- Laguerre Polynomials - NormalizationDocument4 pagesLaguerre Polynomials - NormalizationMassimiliano NaldiNo ratings yet
- Kelly Portfolio OptimizationDocument19 pagesKelly Portfolio OptimizationRiccardo RoncoNo ratings yet
- Lecture Notes: Metric Spaces - Sergey MozgovoyDocument41 pagesLecture Notes: Metric Spaces - Sergey MozgovoyNúñezNo ratings yet
- Math 111Document163 pagesMath 111John Fritz SinghNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Heuristics For The Combined Cut Order Planning Two-Dimensional Layout Problem in The Apparel IndustryDocument33 pagesHeuristics For The Combined Cut Order Planning Two-Dimensional Layout Problem in The Apparel IndustryDÃljït SīñghNo ratings yet
- Algoritmo SQPDocument17 pagesAlgoritmo SQPGeno KronosNo ratings yet
- Math Constrained Optimization I FocDocument44 pagesMath Constrained Optimization I Focarm.unfurledNo ratings yet
- Methods To Manage and Optimize Forest Biomass Supply Chains - A ReviewDocument18 pagesMethods To Manage and Optimize Forest Biomass Supply Chains - A ReviewJuan David Gomez QuicenoNo ratings yet
- Assignment ProblemDocument32 pagesAssignment ProblemPunitValaNo ratings yet
- LP FormulationDocument40 pagesLP FormulationpranjalNo ratings yet
- Algorithm Analysis and Design PDFDocument190 pagesAlgorithm Analysis and Design PDFtheresNo ratings yet
- Microeconomic Analysis NotesDocument23 pagesMicroeconomic Analysis NotesMinira JafarovaNo ratings yet
- 7th Sem SyllabusDocument14 pages7th Sem SyllabusS D ManjunathNo ratings yet
- Schedule Float Analysis PDFDocument159 pagesSchedule Float Analysis PDFmohit16587No ratings yet
- Cloth 2 TexDocument15 pagesCloth 2 TexrakeshsinghpariharNo ratings yet
- ME 7th SemDocument6 pagesME 7th SemShaleen SharmaNo ratings yet
- Chapter 12 - Aggregate PlanningDocument4 pagesChapter 12 - Aggregate Planninghello_khay100% (2)
- Heuristics Vs OptimizationDocument3 pagesHeuristics Vs OptimizationshyamsakhareNo ratings yet
- Introduction To: Artificial IntelligenceDocument86 pagesIntroduction To: Artificial IntelligenceSyed Ali Faiez ZaidiNo ratings yet
- Honeywell APC Ethanol Case StudyDocument3 pagesHoneywell APC Ethanol Case StudymelvokingNo ratings yet
- CIM Assignment 6Document3 pagesCIM Assignment 6Abuzar AliNo ratings yet
- Simsched Direct Block Scheduler: A New Practical Algorithm For The Open Pit Mine Production Scheduling ProblemDocument8 pagesSimsched Direct Block Scheduler: A New Practical Algorithm For The Open Pit Mine Production Scheduling ProblemValentín Ibarra GonzalezNo ratings yet
- Syllabus-IE 101 Operations ResearchDocument3 pagesSyllabus-IE 101 Operations ResearchJourdan KanNo ratings yet
- Open Nucleus Breeding SystemsDocument18 pagesOpen Nucleus Breeding SystemsMisbakhul BadriNo ratings yet
- Fibonnaci Sequence (Golden Rule)Document12 pagesFibonnaci Sequence (Golden Rule)rbmalasaNo ratings yet
- Steve Sashihara's PresentationDocument34 pagesSteve Sashihara's PresentationHossam AhmedNo ratings yet
- Sequencing Problems Processing N Jobs Through 2 Machines Problem Example PDFDocument2 pagesSequencing Problems Processing N Jobs Through 2 Machines Problem Example PDFSaravana Selvakumar100% (1)
- Project Report FormatDocument14 pagesProject Report FormatAdwiteey ShishodiaNo ratings yet
- Traffic Signal Control With ACO - Thesis Renfrew PDFDocument109 pagesTraffic Signal Control With ACO - Thesis Renfrew PDFpakivermaNo ratings yet
- Chemical Engineering Plant Design: Dr. M. Azam SaeedDocument16 pagesChemical Engineering Plant Design: Dr. M. Azam SaeedMuhammad BilalNo ratings yet
- Spatial Analysis Techlectures Fall06Document138 pagesSpatial Analysis Techlectures Fall06iket100% (1)
- Free Parking Space Prediction & Reliability AnalysisDocument6 pagesFree Parking Space Prediction & Reliability AnalysisaslanNo ratings yet